
[TOC]
神经渲染综述
翻译整理自 Advances in Neural Rendering [arXiv]
Ayush Tewari, Justus Thies, Ben Mildenhall, Pratul Srinivasan, Edgar Tretschk, Yifan Wang, Christoph Lassner, Vincent Sitzmann, Ricardo Martin-Brualla, Stephen Lombardi, Tomas Simon, Christian Theobalt, Matthias Niessner, Jonathan T. Barron, Gordon Wetzstein, Michael Zollhoefer, Vladislav Golyanik
摘要
合成照片般真实的图像和视频是计算机图形学的核心,也是几十年来研究的重点。传统上,场景的合成图像是通过光栅化或光线追踪等渲染算法生成的,这些算法将具体定义的几何和材料属性的表示作为输入。总的来说,这些输入定义了实际的场景和被渲染的内容,并被称为场景表示(其中一个场景由一个或多个物体组成)。场景表示的例子包括带有伴随纹理的三角形网格(例如,由艺术家创建)、点云(例如,来自深度传感器)、体积网格(例如,来自CT扫描)或隐含的表面函数(例如,截断的符号距离场)。使用可微分的渲染损失从观测中重建这样的场景表示,被称为逆向图形或逆向渲染。神经渲染与此密切相关,它结合了经典计算机图形学和机器学习的思想,创造了从真实世界的观察中合成图像的算法。神经渲染是朝着合成照片般逼真的图像和视频内容的目标的一次飞跃。近年来,通过数以百计的出版物,我们看到了这一领域的巨大进步,这些出版物展示了将可学习组件注入渲染管道的不同方法。这篇关于神经渲染进展的最新报告着重介绍了将经典的渲染原理与学习的三维场景表征(现在通常被称为神经场景表征)相结合的方法。这些方法的一个关键优势是,它们在设计上是三维一致的,能够实现诸如捕获场景的新视角合成的应用。除了处理静态场景的方法外,我们还包括用于非刚性变形物体建模和场景编辑与合成的神经场景表征。虽然这些方法大多是针对场景的,但我们也讨论了跨对象类别的通用技术,并可用于生成性任务。除了回顾这些最先进的方法外,我们还提供了当前文献中使用的基本概念和定义的概述。最后,我们讨论了开放的挑战和社会影响。

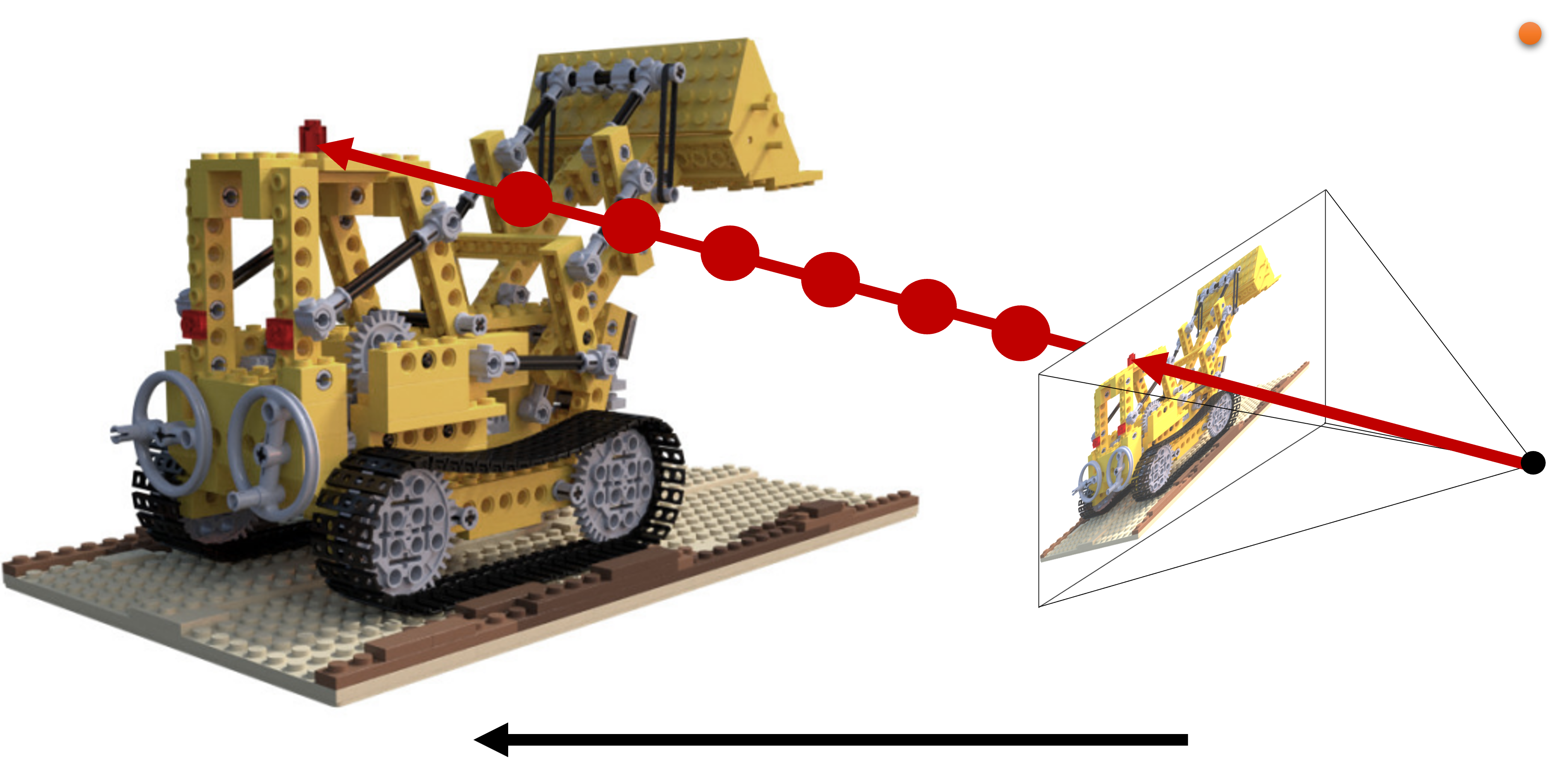
这份SOTA讨论了大量的神经渲染方法,这些方法能够实现诸如新视角的 静态和动态场景的合成、物体的生成性建模和场景重光。关于各种方法的更多细节见第4节。 方法的更多细节,见第4节。图片改编自 [MST20, TY20, CMK21, ZSD21, BBJ21, LSS21, PSB21, JXX21, PDW21] ©2021 IEEE.
1. 简介
合成可控的、照片般真实的图像和视频是计算机图形学的基本目标之一。在过去的几十年里,人们开发了一些方法和表现形式来模仿真实相机的图像形成模型,包括处理复杂的材料和全局照明。这些方法基于物理学定律,模拟了从光源到虚拟摄像机的光传输,进行合成。为此,在渲染过程中必须知道场景的所有物理参数。例如,这些参数包含关于场景几何和材料属性的信息,如反射率或不透明度。考虑到这些信息,现代光线追踪技术可以生成照片般真实的图像。除了基于物理学的渲染方法,还有各种近似于真实世界图像形成模型的技术。这些方法是基于数学近似(例如,表面的片状线性近似;即三角形网格)和启发式方法(例如,Phong阴影),以提高适用性(例如,用于实时应用)。虽然这些方法需要较少的参数来表示一个场景,但所实现的真实性也会降低。
虽然传统的计算机图形学允许我们生成高质量的可控场景图像,但场景的所有物理参数,例如相机参数、照度和物体的材料都需要作为输入提供。如果我们想生成真实世界场景的可控图像,我们就需要从现有的观察结果(如图像和视频)来估计这些物理属性。这种估计任务被称为逆向渲染,是非常具有挑战性的,特别是当目标是照片逼真的合成。相比之下,神经渲染是一个迅速兴起的领域,它可以紧凑地表示场景,通过利用神经网络,可以从现有的观察中学习渲染(见《神经渲染的进展》)。神经渲染的主要思想是将经典(基于物理学的)计算机图形学的见解与深度学习的最新进展相结合。与经典计算机图形学类似,神经渲染的目标是以一种可控的方式生成照片般真实的图像(参见[TFT20]中对神经渲染的定义)。例如,这包括新颖的视点合成、重新打光、场景变形和合成。
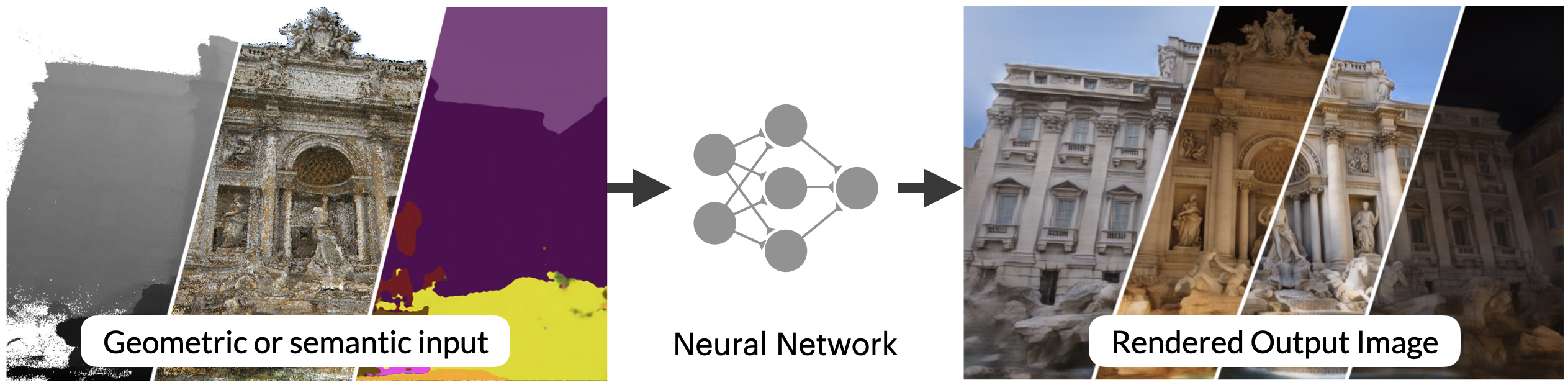
(a)二维神经渲染,也被称为神经细化、神经再渲染或延迟神经渲染,是基于例如使用经典渲染器生成的二维输入,并学习以二维方式渲染场景。
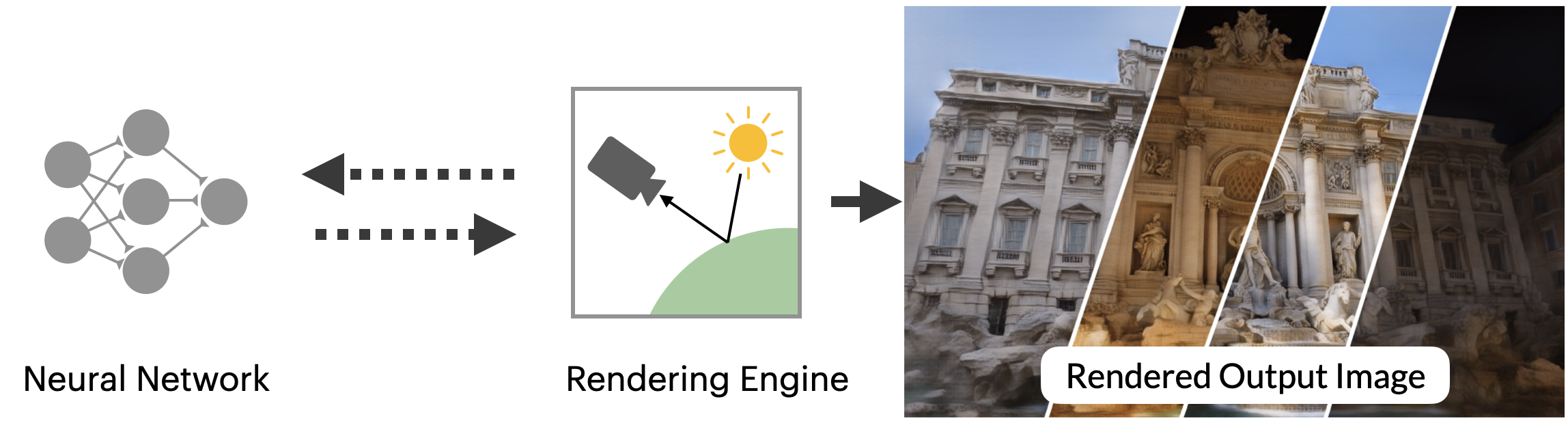
(b)3D神经渲染学习在3D中表现一个场景,并使用来自计算机图形学的固定可微分渲染方案,这些方案的动机是物理学。
图1:”神经渲染 “这个术语经常被用于两个不同的概念。之前关于神经渲染的STAR报告[TFT20]主要关注(0(a))所示的范式,其中神经网络被训练为从一些二维输入信号(如语义标签或栅格化的代理几何体)直接映射到输出图像–神经网络被训练为渲染。本报告重点关注一种新出现的神经渲染范式,如(0(b))所示,NeRF[MST20]就是很好的例证。在这里,一个神经网络被监督,以代表一个特定场景的形状或外观,并且该神经代表使用一个有点传统的图形 “引擎 “进行渲染,该引擎是以分析方式定义的,而不是学习的。与之前的范式不同,这里的神经网络并不学习如何渲染–而是学习以三维方式表示一个场景,然后根据图像形成的物理学原理渲染该场景。图片改编自[NSC19]。
早期的神经渲染方法(在[TFT20]中涉及)使用神经网络将场景参数转换为输出图像。场景参数要么直接作为一维输入,要么使用经典的计算机图形管道来生成二维输入。深度神经网络是在对真实世界场景的观察上进行训练的,并学习对这些场景进行建模和渲染。深度神经网络可以被看作是一个通用的函数近似器。具体来说,一个网络根据其输入参数、模型结构和可训练参数定义了一个函数系列。随机梯度下降法被用来从这个空间中找到最能解释训练集的函数,这是由训练损失衡量的。从这个角度看,神经渲染的目的是找到控制参数和相应的输出图像之间的映射,其中和是图像的高度和宽度。这可以被解释为一个复杂而具有挑战性的稀疏数据插值问题。因此,神经渲染与经典的函数拟合类似,必须在欠拟合和过度拟合之间进行权衡,即很好地代表训练集与泛化到未观察到的输入。如果网络的表示能力不足,所得到的图像质量会很低,例如,结果往往是模糊的。另一方面,如果表征能力太大,网络就会过度适应训练集,在测试时不能对未见过的输入进行泛化。找到正确的网络架构本身就是一门艺术。在神经渲染的背景下,设计正确的物理动机的归纳偏差往往需要强大的图形背景。这些物理动机的归纳偏差作为正则器,确保找到的函数接近于三维空间和/或图像形成在我们现实世界中的工作方式,从而在测试时导致更好的泛化。归纳偏见可以通过不同方式添加到网络中。例如,在所采用的层方面,在网络中的哪一点,以何种形式提供输入,甚至通过整合经典计算机图形学中的非训练性(但可区分)组件。这方面的一个很好的例子是最近的神经渲染技术,它试图通过只学习三维场景的表示,并依靠计算机图形学的渲染功能来监督,从而将建模和渲染过程分离开来。例如,神经辐射场(NeRF)[MST20]使用多层感知器(MLP)来逼近三维场景的辐射和密度场。这种学习到的体积表征可以从任何虚拟摄像机中使用可分析的微分渲染(即体积整合)进行渲染。在训练中,假设从几个摄像机的视角观察场景。通过从这些训练视点渲染估计的三维场景,并使渲染的图像和观察到的图像之间的差异最小化,对这些观察结果进行网络训练。一旦训练完成,由神经网络近似的三维场景就可以从一个新的视点进行渲染,实现可控的合成。与使用神经网络学习渲染功能的方法相比[TFT20],NeRF在方法中更明确地使用了计算机图形学的知识,由于(物理的)归纳偏向,能够更好地归纳到新的视图中:场景的密度和辐射度的中间三维结构表示。因此,NeRF在三维空间中学习了有物理意义的颜色和密度值,然后物理学启发的光线投射和体积整合可以一致地渲染成新的视图。
所取得的质量以及该方法的简单性,导致了该领域的 “爆炸 “式发展。已经取得了一些进展,改善了适用性,实现了可控性,捕捉了动态变化的场景,以及训练和推理时间。在这份报告中,我们介绍了该领域的这些最新进展。为了促进对这些方法的深入理解,我们在第3节中通过详细描述不同的组件和设计选择来讨论神经渲染的基本原理。具体来说,我们澄清了当前文献中使用的不同场景表征的定义(表面和体积方法),并描述了使用深度神经网络对其进行近似的方法。我们还介绍了用于训练这些表征的计算机图形学的基本渲染函数。由于神经渲染是一个发展非常迅速的领域,在许多不同的维度上都取得了重大进展,我们对最近的方法进行了分类,并对其应用领域进行了简明的概述。基于这个分类法和不同的应用领域,我们在第4节介绍了最先进的方法。报告的最后,第5节讨论了开放性的挑战,第6节讨论了照片逼真的合成媒体的社会影响。
2. 本文的范围
在这份SOTA中,我们关注的是先进的神经渲染方法,它将经典的渲染与可学习的三维表征相结合(见图1)。底层的神经三维表征在设计上是三维一致的,能够控制不同的场景参数。在本报告中,我们对不同的场景表示进行了全面的概述,并详细介绍了从经典渲染管道以及机器学习中借来的组件的基本原理。我们进一步关注使用神经辐射场[MST20]和体积化渲染的方法。然而,我们并不关注那些主要在二维屏幕空间中进行推理的神经渲染方法;我们参考了[TFT20]关于此类方法的讨论。我们也不涉及光线追踪图像的神经超采样和去噪方法[CKS17, KBS15]。
3. 神经渲染的基本原理
神经渲染,特别是三维神经渲染是基于计算机图形学的经典概念(见图1)。神经渲染管道学会了从真实世界的图像中渲染和/或表示一个场景,这些图像可以是无序的图像集,也可以是结构化的多视图图像或视频。它通过模仿相机捕捉场景的物理过程来实现这一目标。三维神经渲染的一个关键属性是在训练过程中,相机捕捉过程(即投影和图像形成)与三维场景表示的分离。这种分离有几个优点,特别是在图像合成过程中导致了高水平的三维一致性(例如,对于新的视点合成)。为了将投影和其他物理过程与三维场景表示分离开来,三维神经渲染方法依赖于计算机图形学中已知的图像形成模型(例如光栅化、点拼接或体积整合)。这些模型是以物理学为动力的,特别是发射器的光线与场景以及相机本身的相互作用。这种光传输是用渲染方程[And86]制定的。
计算机图形领域为这个渲染方程提供了各种近似的方法。这些近似方法取决于所使用的场景表现,范围从经典的栅格化到路径追踪和体积整合。三维神经渲染利用了这些渲染方法。在下文中,我们将详细介绍常见的神经渲染方法中使用的场景表示(第3.1节)和渲染方法(第3.2节)。请注意,为了从真实图像中学习,场景表示和渲染方法本身都必须是可分的(第3.3节)。
3.1. 场景表示
几十年来,计算机图形界一直在探索各种基元,包括点云、隐式和参数化表面、网格和体积(见图2)。虽然这些表示法在计算机图形学领域有明确的定义,但在目前的神经渲染文献中,特别是关于隐式和显式表面表示法和体积表示法时,常常会出现混淆。一般来说,体积表征可以代表表面,但反之亦然。体积表征存储的是体积属性,如密度、不透明度或占有率,但它们也可以存储多维特征,如颜色或辐射度。与体积表征相反,表面表征储存的是物体表面的属性。它们不能用来模拟体积物质,如烟雾(除非是一个粗略的近似值)。对于表面和体积表征,都有连续和离散的对应物(见图2)。连续表征对神经渲染方法特别有趣,因为它们可以提供解析的梯度。
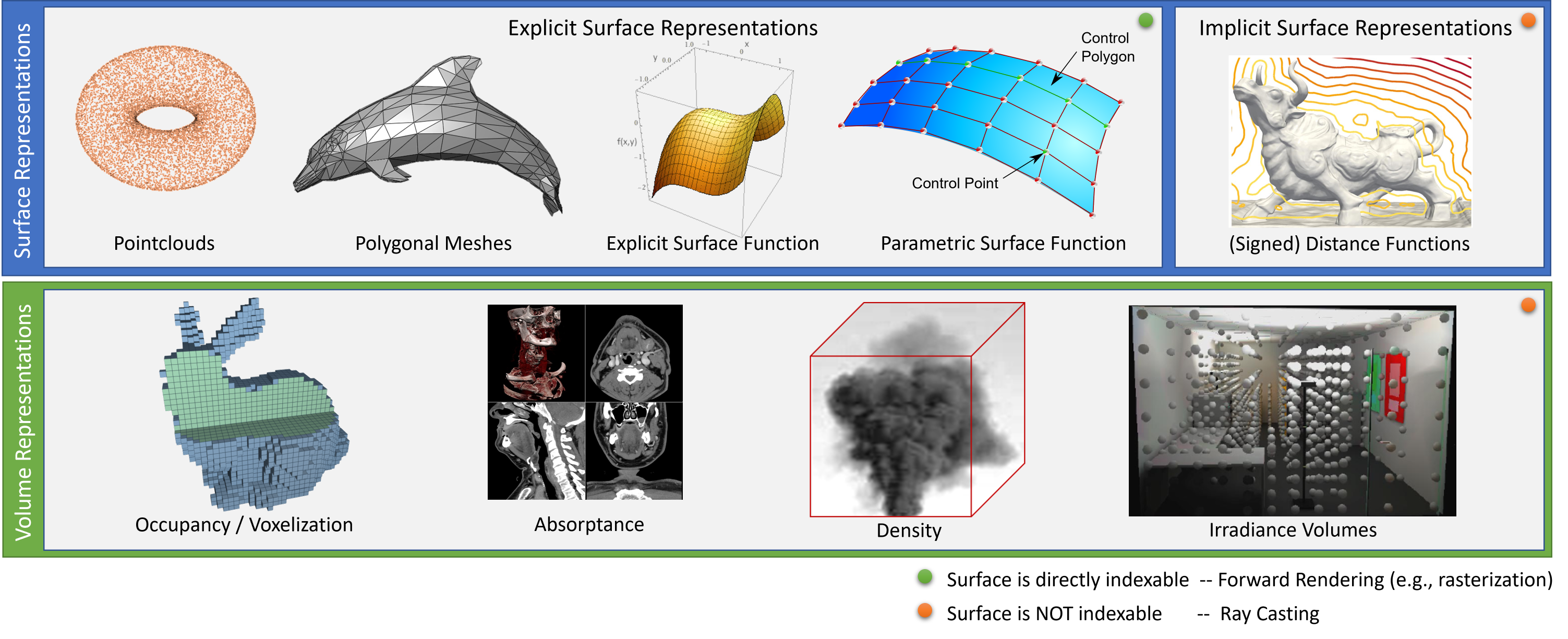
对于曲面表示,有两种不同的方式来表示曲面–显式或隐式。 在欧氏空间的 $f_\mathit{explicit}(.) \in \mathbb{R}$ 中,使用显式曲面函数的曲面定义为。
\[\begin{equation} S_\mathit{explicit} = \left\lbrace \left( \begin{array}{c} x\\ y\\ f_\mathit{explicit}(x,y)\\ \end{array} \right) ~\middle|~ \left( \begin{array}{c} x\\ y\\ \end{array} \right) \in \mathbb{R}^2 \right\rbrace. \end{equation}\]请注意,一个显式曲面也可以用参数函数 $f_\mathit{parametric}(.) \in \mathbb{R}^3$ 表示,它概括了 $S_\mathit{explicit}$ 。
\[\begin{equation} S_\mathit{explicit}^{*} = \left\lbrace f_\mathit{parametric}(u,v) ~\middle|~ \left( \begin{array}{c} u\\ v\\ \end{array} \right) \in \mathbb{R}^2 \right\rbrace. \end{equation}\]使用隐含曲面函数 $f_\mathit{implicit}(\cdot) \in \mathbb{R}$ 的曲面被定义为零级集。
\[\begin{equation} S_\mathit{implicit} = \left\lbrace \left( \begin{array}{c} x\\ y\\ z\\ \end{array} \right) \in \mathbb{R}^3 ~\middle|~ f_\mathit{implicit}(x,y,z) = 0 \right\rbrace. \end{equation}\]而体积表示法定义了整个空间的属性。
\[\begin{equation} V = \left\lbrace f_\mathit{vol}(x,y,z) ~\middle|~ \left( \begin{array}{c} x\\ y\\ z\\ \end{array} \right) \in \mathbb{R}^3 \right\rbrace. \end{equation}\]请注意,对于所有这些表征来说,各自的函数域都可以被限制。
一般来说,对于这三种场景表示,基础函数可以是任何能够近似于各自内容的函数。 对于像平面这样的简单曲面,函数 $f_{implicit}$ 、 $f_{explicit}$ 可以是线性函数。 为了处理更复杂的曲面或体积,可以使用多项式(例如来自泰勒级数)或多变量高斯。 为了进一步提高表现力,这些函数可以在空间上进行定位,然后组合成一个混合物,例如,多个高斯可以形成一个高斯混合物。 径向基函数网络就是这样的混合模型,可以作为隐含表面和体积函数的近似器[CBC01a]。 请注意,这些径向基函数网络可以被解释为神经网络的一个单层。
由于神经网络,尤其是多层感知器(MLPs)是通用的函数近似器,它们可以用来 “学习 “基础函数( $f_\mathit{implicit}$ 、 $f_\mathit{explicit}$ 、 $f_\mathit{parametric}$ 或 $f_\mathit{vol}$)。 (与高斯混合物类似,多个局部的、较弱的MLP也可以组合成一个混合物,例如,[RPLG21]。) 在神经渲染的背景下,一个使用神经网络来逼近表面或体积表示函数的场景表示被称为神经场景表示。 请注意,表面和体积表征都可以被扩展来存储额外的信息,比如颜色或与视图相关的辐射度。
在下文中,我们将讨论不同的基于MLP的函数近似器,这些函数构建了最近的神经表面和体积表征的基础。
3.1.1. MLP作为通用函数逼近器
众所周知,多层感知器(MLPs)可以作为通用函数近似器[HSW89]。具体来说,我们使用MLPs来表示表面或体积属性。多层感知器是一个传统的全连接的神经网络。在场景再现的背景下,MLP将空间中的一个坐标作为输入,并产生与该坐标相对应的一些值作为输出。这种类型的网络也被称为基于坐标的神经网络(由此产生的表示被称为基于坐标的场景表示)。请注意,输入的坐标空间可以与欧几里得空间对齐,但也可以嵌入例如网格的uv空间(产生一个神经参数化的表面)。
将基于ReLU的MLPs用于神经表示和渲染任务的一个关键发现是使用了位置编码。受自然语言处理中使用的位置编码的启发(例如,在Transformers[VSP17]中),输入坐标是使用一组基函数进行位置编码的。这些基函数可以是固定的[MST20],也可以是学习的[TSM20]。这些空间嵌入简化了MLP学习从一个位置到一个特定值的映射的任务,因为通过空间嵌入,输入空间被分割了。作为一个例子,NeRF[MST20]中使用的位置编码被定义为。
\[\begin{align} \mathbf x &\mapsto [\cos(\mathbf M \mathbf x), \sin(\mathbf M\mathbf x)] \\ \textrm{where } \mathbf M &= \begin{bmatrix} \mathbf I & 2 \mathbf I & 2^2 \mathbf I & \ldots & 2^{p-1} \mathbf I \end{bmatrix}^\top . \end{align}\]这里, $\mathbf x$ 是输入坐标, $p$ 是一个控制使用频率的超参数(取决于目标信号的分辨率)。 这种输入坐标的 “软 “二进制编码使网络更容易获得更高频率的输入。
如上所述,基于MLP的函数近似器可用于表示表面或体积(即 $f_\mathit{implicit}$ 、 $f_\mathit{explicit}$ 、 $f_\mathit{parametric}$ 或 $f_\mathit{vol}$ ),但它们也可用于存储其他属性,如颜色。 例如,有一些混合表示法,由经典的表面表示法(如点云或网格)与MLP组成,用于存储表面外观(例如,纹理场[OMN19])。
3.1.2. 表面表征
点云。点云是欧几里得空间的一组元素。一个连续的表面可以被点云离散化–点云的每个元素都代表表面上的一个样本点 $(x, y, z)$ 。对于每个点,可以存储额外的属性,如法线或颜色。以法线为特征的点云也被称为定向点云。除了可以看作是无限小的表面补丁的简单点之外,还可以使用有半径的定向点云(代表一个位于底层表面的切线平面上的二维圆盘)。这种表示方法被称为表面元素,别名surfels[PZvBG00]。在计算机图形学中,它们经常被用来渲染点云或模拟的粒子。这种surfels的渲染被称为splatting,最近的工作表明它是可分的[YSW19a]。使用这样一个可微分的渲染管道,可以直接回传到点云的位置以及伴随的特征(如半径或颜色)。在基于神经点的图形[ASK20a]和SynSin[WGSJ20]中,可学习的特征被附加到点上,可以存储关于实际表面的外观和形状的丰富信息。在ADOP[RFS21a]中,这些可学习的特征被一个MLP解释,该MLP可以解释与视图相关的影响。请注意,我们也可以用MLP来预测离散位置的特征,而不是明确地存储特定点的特征。
如上所述,点云是欧几里得空间的一组元素,因此,除了表面,它们也可以代表体积(例如,存储额外的不透明度或密度值)。对每个点使用一个半径自然会导致一个完整的基于球体的表述[LZ21]。
网格。多边形网格表示一个表面的片状线性近似。特别是,三角形和四边形网格在计算机图形中被用作表面的事实上的标准表示。图形管道和图形加速器(GPU)被优化为每秒处理和栅格化数十亿个三角形。大多数图形编辑工具都使用三角形网格,这使得这种表示方法对任何内容创建管道都很重要。为了与这些管道直接兼容,许多 “经典 “的逆向图形和神经渲染方法都使用这种基本的表面表示。使用可分化的渲染器,顶点位置以及顶点属性(如颜色)可以被优化以再现图像。神经网络可以被训练来预测顶点位置,例如,预测动态变化的表面[BNT21]。代替使用顶点属性,在三角形内存储表面属性的一个常见策略是纹理图。二维纹理坐标被附加到网格的顶点上,这些顶点参考纹理图像中的某个位置。使用arycentric插值,可以计算出三角形中任何一点的纹理坐标,并且可以使用双线性插值从纹理中检索出属性。纹理的概念也被整合到了标准的图形管道中,还有一些额外的功能,如mip-mapping,这是正确处理纹理的采样所需要的(比方说,采样定理)。延迟神经渲染[TZN19],使用包含可学习的视图依赖特征的纹理,即所谓的神经纹理。具体来说,一个粗略的网格被用作底层的三维表示,以栅格化这些神经纹理。一个神经网络在图像空间解释这些栅格化的特征。请注意,该网络可以是一个像素级的MLP,那么神经纹理就代表了表面辐射度。
与使用离散纹理相比,可以使用连续纹理。纹理场[OMN19]的作者提出使用一个MLP来预测每个表面点的颜色值。在神经反射场纹理(NeRF-Tex)[BGP21]中,NeRF[MST20]的思想与使用二维神经纹理和底层三维网格的思想相结合。NeRF-Tex以用户定义的参数为条件,控制外观,因此,可由艺术家编辑。
隐式的表面。隐式曲面将曲面定义为一个函数的零级集,见公式3。最常用的隐式曲面表示是有符号距离函数(SDF)。这些SDF表示被用于许多三维扫描技术,这些技术使用体积融合[CL96]来增量重建静态[IKH11, NZIS13]或动态物体的表面[NFS15]。隐式表面表示法有很多优点,因为它们避免了定义网格模板的要求,因此,能够表示未知拓扑结构的物体或动态场景中不断变化的拓扑结构。上面提到的体积融合方法使用离散的(截断的)有符号距离函数,即使用包含有符号距离值的三维网格。Hoppe等人[HDD92]提出了片断线性函数来模拟带符号的距离函数,即输入表面点样本。Carr等人的开创性工作[CBC01b]使用径向基函数网络代替。这个径向基函数网络表示一个连续的隐含曲面函数,可以看作是第一个 “神经 “隐含曲面表示法。最近的神经隐含曲面表示法是基于基于坐标的多层感知器(MLPs),在第3.1.1节中有所介绍。这类表征在神经场景表征和渲染中得到了广泛的应用。它们同时在[PFS19, CZ19]中被提出用于形状建模,其中MLP架构被用来将连续坐标映射到有符号的距离值。这种坐标网络或神经隐含表征所代表的信号的保真度主要受限于网络的容量。因此,与上述其他表征相比,隐含曲面在记忆效率方面具有潜在的优势,而且作为一种连续的表征,理论上它们可以在无限的分辨率下表示几何图形。在最初的提议之后,人们以广泛的热情进行了各种不同重点的改进,包括改进训练方案[XFYS20, NO20,YAK20],利用全局-局部背景[XWC19,EGO20],采用特定的参数化[GCV19, DGY20,CTZ20,KJJ21,YRSH21]或空间分区[GCS20,TTG20,CLI20, TLY21, MLL21]。由于没有预先定义网格模板或物体拓扑结构的要求,神经隐含曲面很适合于对不同拓扑结构的物体进行建模[PFS19,CZ19]。输出相对于输入坐标的分析梯度可以通过反向传播来计算。这使得在梯度上实现正则化项成为可能[GYH20],此外还有其他以几何学为动机的正则化器[GYH20,PFAK20,YAK20]。这些重述可以扩展到同时编码场景的辐射度[KJJ21, YTB21,AS19]。这对于神经渲染是很有用的,我们希望场景的表示能够同时编码场景的几何和外观。
3.1.3. 体积表征
体素网格。作为 $\mathbb{R}^3$ 中的像素等价物,体素通常被用来表示体积。它们可以存储几何体的占有率,或者存储具有体积效应的场景的密度值,如透明度。此外,场景的外观也可以被存储[GSHG98]。使用三线插值,这些体积属性可以在体素网格中的任何一点被访问。这种插值法特别适用于基于样本的渲染方法,如射线投射。虽然存储的属性可以有特定的语义(如占有率),但这些属性也可以被学习。Sitzmann等人提出使用DeepVoxels[STH19],其中特征被存储在体素网格中。在光线投射渲染程序之后,对特征的积累和解释是通过一个深度神经网络完成的。这些DeepVoxels可以被看作是体积神经纹理,它可以直接使用反向传播进行优化。虽然基于体素的密集表征查询速度快,但它们的内存效率低,而且三维CNN,可能在这些体积上操作,计算量大。八叉树数据结构[LK10]可以用来以稀疏的方式表示体积。八叉树上的稀疏三维卷积[WGG17, ROUG17]可以帮助缓解一些问题,但是这些紧凑的数据结构不容易被即时更新。因此,它们很难集成到学习框架中。其他缓解密集体素网格记忆挑战的方法包括使用特定对象的形状模板[KTEM18]、多平面[ZTF18, MSOC19,FBD19,TS20,WPYS21]或多球体[BFO20,ALG20]图像,它们都是为了用稀疏的近似来表示体素网格。
神经性体积表征。不使用体素网格来存储特征或其他感兴趣的量,这些量也可以使用神经网络来定义,类似于神经隐含面(见第3.1.2节)。MLP网络结构可以用来对体积进行参数化,可能比显性体素网格的方式更节省内存。但是,根据基础网络的大小,这些表征的采样成本可能很高,因为对于每个采样,必须计算通过网络的整个前馈通道。大多数方法可以大致分为使用全局或局部网络[GCV19,GCS20,CZ19,MFA19,AL20,AS19,SZW19,OMN19,GYH20,YKM20,DNJ20,SMB20,NMOG20,LGL20,JJHZ20,LZP20,KSW20]。同时使用网格和神经网络的混合表征在计算和记忆效率之间做了权衡[PNM20, JSM20,CLI20,MLL21]。与神经隐含曲面类似,神经体积表征允许计算分析梯度,这在[SMB20,TTG21,PSB21]中被用来定义正则化项。
一般性评论。使用基于坐标的神经网络对场景进行体积建模(如NeRF),表面上看与使用坐标网络对曲面进行隐含建模(如神经隐含曲面)相似。然而,类似于NeRF的体积表征不一定是隐性的–因为网络的输出是密度和颜色,场景的几何是由网络显性地而不是隐性地进行参数化。尽管如此,在文献中,这些模型仍然被称为 “隐式”,这也许是指场景的几何是由神经网络的权重 “隐式 “定义的(与SDF文献中使用的 “隐式 “定义不同)。还要注意的是,这是与深度学习和统计学界通常使用的不同的 “隐式 “定义,其中 “隐式 “通常是指其输出被隐式定义为动态系统的固定点的模型,其梯度是使用隐式函数定理计算的[BKK19]。
3.2. 可微分图像的形成
前面几节中的场景表示法使我们能够表示场景的三维几何和外观。作为下一步,我们将描述如何通过渲染从这种场景表示中生成图像。将三维场景渲染成二维图像平面的一般方法有两种:射线投射和光栅化,也见图3。场景的渲染图像也可以通过定义场景中的相机来计算。大多数方法都使用针孔摄像机,所有的摄像机光线都会通过空间中的一个点(焦点)。有了给定的摄像机,从摄像机原点射出的光线可以投向场景,以计算出渲染的图像。
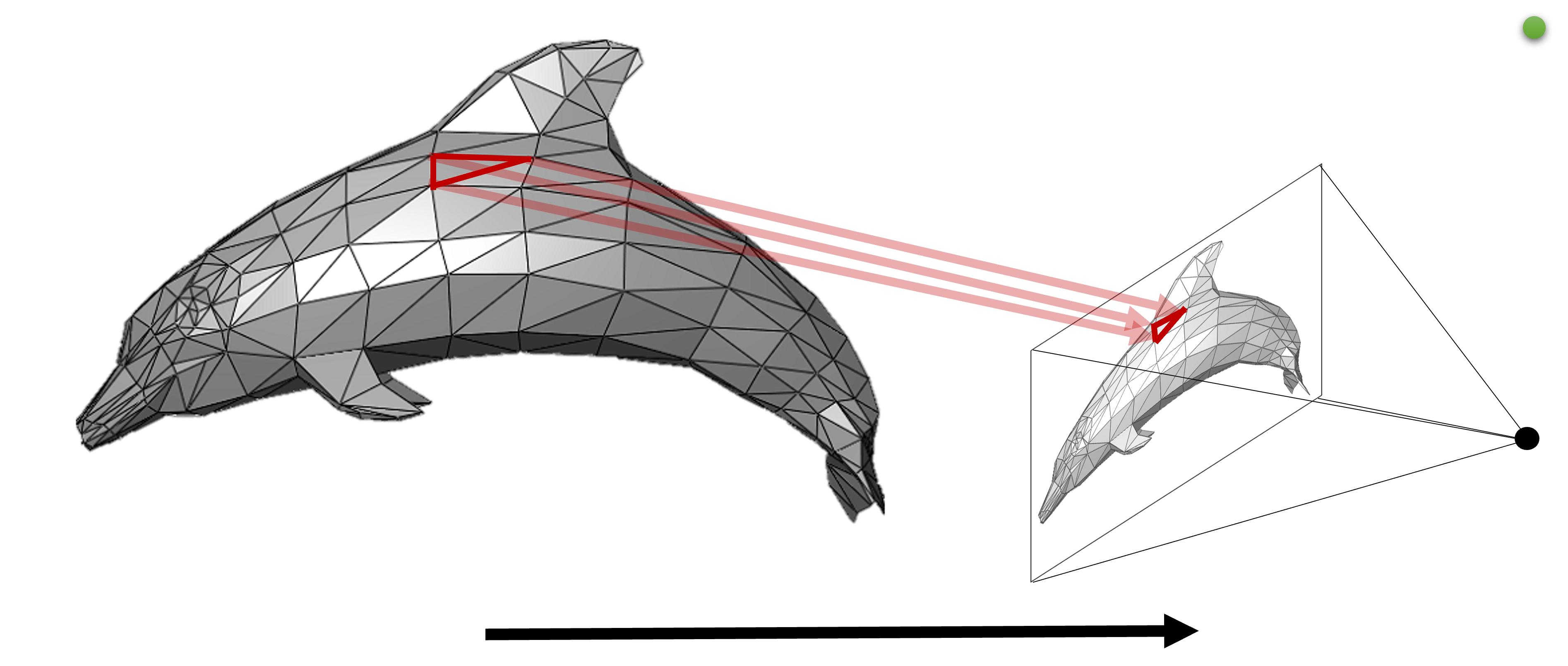
(a)正向渲染(如光栅化)–图像是通过将三维表示投射到图像平面上产生的。
(b)射线投射–图像是通过投射观察射线、对三维表示进行采样并累积来生成的。图片改编自[MST20]。
图3:对于显式曲面的表示,曲面是可以直接索引的。这使得我们可以使用前向渲染方法,将曲面投射到图像平面上,并相应地设置一个像素(例如,使用栅格化或点拼接)。隐式表面表示法和体积表示法不能提供直接的表面信息来进行前向渲染,相反,从虚拟摄像机看到的三维空间必须被采样以生成图像(例如,使用射线行进法)。
光线投射。在针孔模型中,基本截距定理可以用来描述三维中的一个点 $\mathbf{p} \in \mathbb{R}^3$ 如何被投射到图像平面中的正确位置 $\mathbf{q} \in \mathbb{R}^2$ 。根据定义,它是一个非单射函数,而且很难求逆–这使得它成为三维重建问题的核心。
针孔模型对这种投影只有一个参数矩阵:内在矩阵 $\mathbf{K}$ 包含按像素大小归一化的焦距 $\mathbf{f}=[\alpha_x, \alpha_y]$ ,轴斜度 $\gamma$ 和中心点 $\mathbf{c}=[c_x, c_y]$ 。利用截距定理并假设同质坐标 $\mathbf{p}’=[x, y, z, 1]$ ,我们发现投影坐标为 $\mathbf{q}’=\mathbf{K}\cdot \mathbf{p}’$ ,其中
\[\mathbf{K} = \begin{bmatrix} \alpha_x & \gamma & c_x & 0\\ 0 & \alpha_y & c_y & 0\\ 0 & 0 & 1 & 0\\ \end{bmatrix}.\]这假定投影的中心在坐标原点,并且相机是轴对齐的。为了对任意的相机位置进行概括,可以使用一个外在的矩阵 $\mathbf{R}$ 。这个同质的4x4的矩阵 $\mathbf{E}$ 由以下部分组成
\[\mathbf{E}=\begin{bmatrix} \mathbf{R}_{3\times 3} & \mathbf{t}_{3\times 1} \\ \mathbf{0}_{1\times 3} & 1 \\ \end{bmatrix},\]其中 $\mathbf{R}$ 是一个旋转矩阵, $\mathbf{t}$ 是一个平移矢量,这样 $\mathbf{R} \cdot \mathbf{p_w}+\mathbf{t}=\mathbf{p_c}$ ,我们用 $\mathbf{p_w}$ 表示世界坐标的一个点, $\mathbf{p_c}$ 表示相机坐标的一个点。这种 $\mathbf{R}$ 和 $\mathbf{t}$ 的定义在计算机视觉中很常见(比如OpenCV使用的),被称为 “世界到相机 “的映射,而在计算机图形中(比如OpenGL),类似的反向 “相机到世界 “的映射更为普遍。假设采用 “世界到摄像头 “的惯例并使用同质坐标,我们可以将 $\mathbf{p_w}$ 到 $\mathbf{q_p}$ 的完整投影写成。
如果使用 “凸轮到世界 “的惯例,射线铸造也同样方便。虽然这些方程由于深度的模糊性而是非主观的,但它们非常适用于自动区分,并且可以在图像形成模型中进行端到端的优化。
为了对目前的相机进行正确的建模,还有一个组件必须被考虑在内:镜头。撇开必须在图像形成过程中建模的景深或运动模糊等效应不谈,它们为投影函数增加了失真效应。不幸的是,没有一个简单的模型来捕捉所有不同的镜头效应。校准包,如OpenCV中的校准包,通常实现了有多达12个畸变参数的模型。它们是通过五度以下的多项式建模的,因此不是可逆的(相对于点投影而言,这是射线投影的要求)。更现代的相机校准方法使用更多的参数,并达到更高的精度[SLPS20],并可以使其成为可逆和可微的。
\[\mathbf{q_p}'=\mathbf{K}\cdot\begin{bmatrix} \mathbf{R} & \mathbf{t} \\ \mathbf{0}_{1\times 3} & 1 \\ \end{bmatrix}\cdot\mathbf{p_w}'.\]光栅化。光线投射的另一个选择是几何基元的栅格化。这种技术并不试图模仿真实世界的图像形成过程,而是利用物体的几何属性来快速创建图像。它主要用于网格,网格由一组顶点 $\mathbf{v}$ 和面 $\mathbf{f}$ 描述,连接三倍或四倍的顶点以定义表面。一个基本的见解是,三维的几何操作可以只对顶点进行操作:例如,我们可以使用相同的外在矩阵 $\mathbf{E}$ 来将每个点从世界坐标系转换到相机坐标系。在这种转换之后,视角范围之外的点或法线方向错误的点可以被剔除,以减少在接下来的步骤中要处理的点和面的数量。剩下的点投射到图像坐标上的位置可以再次通过使用上述的内在矩阵 $\mathbf{K}$ 找到。面信息可以用来插值面基元的深度,而最上面的面可以存储在一个Z缓冲区中。
这种实现投影的方式通常比射线投射更快:它主要是随着场景中可见顶点的数量而扩展,而射线投射则是随着像素的数量和要相交的基元的数量而扩展。然而,使用它更难捕捉到某些效果(例如照明效果、阴影、反射)。它可以通过 “软 “栅格化而变得可微分。例如,这已经在[LLCL19, RRN20]中实现了。
3.2.1. 表面渲染
点云渲染。在计算机图形学文献中,点云渲染技术被广泛使用[KB04,SP04]。如前所述,点云是连续表面或体积的离散样本。点云渲染相当于从不规则分布的离散样本中重建连续信号,例如,连续表面的外观,然后在图像空间的每个像素位置对重建的信号进行重采样。
这个过程可以通过两种不同的方式完成。第一种方法是基于经典的信号处理理论,可以看作是一种 “软 “点拼接(类似于下面网格渲染部分的软光栅器)。它首先使用连续的局部重建核子 $r (\cdot )$ 构建连续信号,即 $\mathbf f=\sum\mathbf f_i r(\mathbf p_i)$ 。本质上,这种方法相当于将离散样本与一些局部确定性模糊核[LKL18, ID18,SALARY18]相混合,例如EWA splatting[ZPVBG01, ZPVBG02],它是一个空间变化的重建核,旨在最小化混叠。在神经渲染中,离散的样本可以存储一些可学习的特征。相应地,上述步骤可以有效地将各个特征投射并混合成一个二维特征图。如果这些特征有预定的语义(如颜色、法线),则可以使用固定的阴影函数或BRDF来生成最终的图像。如果特征是学习的神经描述符,则部署一个二维神经网络来将二维特征图转化为RGB图像。最近采用这种方法的神经点渲染方法包括SinSyn和Pulsar [WGSJ20, LZ21]。出于性能方面的考虑,它们在混合步骤中使用空间不变和各向同性的核。虽然这些简化的核子可能会导致渲染假象,如孔洞、模糊的边缘和混叠,但这些假象可以在神经着色步骤中得到补偿。
除了软点溅射的方法,我们可以使用OpenGL或DirectX的传统点渲染器。在这里,每个点都被投射到一个像素(或一个小的像素区域),从而形成一个稀疏的特征图。我们可以使用深度神经网络来直接在图像空间中重建信号 [ASK20b]。请注意,这种天真的渲染方法并不提供与点位置有关的梯度 $(\mathbf{p})$ ,只允许区分渲染函数与(神经)特征的关系。与此相反,软点拼接方法通过重建核 $r(\mathbf{p})$提供点位置梯度。
网格渲染。有许多通用的渲染器允许将网格栅格化或以其他方式进行可分化的渲染。在可微分的网格光栅化器中,Loper和Black[LB14]开发了一个名为OpenDR的可微分渲染框架,它近似于主渲染器,并通过自动微分计算梯度。神经网格渲染器(NMR)[KUH18]使用手工制作的函数对可见度变化进行光栅化操作,近似于后向梯度。[LTJ18]提出了Paparazzi,这是一个使用图像滤波器进行网格几何处理的可分析微分渲染器。Petersen等人[PBDCO19]提出了Pix2Vex,一个通过附近三角形的软混合方案的 $C^{\infty}$ 可微分渲染器,[LLCL19]引入了Soft Rasterizer,它渲染和聚集了网格三角形的概率图,允许梯度流从渲染的像素到被遮挡和远距离的顶点。虽然大多数光栅器只支持基于直接光照的渲染,但[LHL21]也支持软阴影的可区分渲染。在基于物理的渲染领域,[LADL18a]和[ALKN19]引入了一个可区分的光线追踪器来实现基于物理的渲染效果的可区分性,处理相机位置、照明和纹理。此外,Mitsuba 2 [NDVZJ19]和Taichi [HLA19, HAL20]是通用的基于物理的渲染器,通过自动分化支持可分化网格渲染,以及其他许多图形技术。
神经隐式曲面渲染。当输入的观测值是二维图像的形式时,实现隐含曲面的网络被扩展到不仅产生与几何有关的量,即有符号的距离值,而且还产生与外观有关的量。一个隐式可微分渲染器[SZW19,NMOG20,LZP20,LSCL19,YKM20,KJJ21,BKW21,TLY21]可以通过使用神经隐式函数的几何分支首先找到观察射线与曲面的交点,然后从外观分支获得该点的RGB值来实现。表面交点的搜索通常是基于球体追踪算法的某种变体[Har96]。球体追踪算法从摄像机中心沿着视线方向对三维空间进行迭代采样,直到到达表面。球体追踪是一种优化的射线行进方法,它通过在前一个位置采样的SDF值来调整步长,但这种迭代策略仍然会造成计算上的浪费。Takikawa等人 ([TLY21])通过将光线追踪算法适应于稀疏八叉树数据结构来改善渲染性能。从二维监督中进行几何和外观联合估计的隐式表面渲染的一个常见问题是几何和外观的模糊性。在[NMOG20,YKM20,KJJ21,BKW21]中,从二维图像中提取前景掩码,为几何分支提供额外的监督信号。最近,[OPG21]和[YGKL21b]通过将表面函数制定为体积渲染公式(下文介绍)来解决这个问题;另一方面,[ZYQ21]使用现成的深度估计方法来生成伪地面真实签名距离值以协助几何分支的训练。
3.2.2. 体积渲染
体积渲染是以光线投射为基础的,并且已经被证明在神经渲染中是有效的,特别是在从多视图输入数据中学习场景表示方面。具体来说,场景被表示为一个连续的体积密度或占有率的领域,而不是一个硬表面的集合。
这意味着射线在空间的每一点上都有与场景内容相互作用的一些概率,而不是二元交叉事件。这种连续模型作为机器学习管道的可微分渲染框架效果很好,它在很大程度上依赖于存在良好的梯度进行优化。
尽管完全通用的体积渲染确实考虑了 “散射 “事件,即光线可以从体积粒子上反射出去[Jar08],但我们将把这个总结限制在神经体积渲染方法通常用于视图合成的基本模型上[LH96, Max95],它只考虑了 “发射 “和 “吸收 “事件,即光线被体积粒子发射或阻挡。
给定一组像素坐标,我们可以使用之前描述的相机模型来计算出相应的穿越三维空间的射线,其原点 $\mathbf p$ 和方向 $\omega_{\text{o}}$ 。沿着这条射线的入射光线可以用一个简单的发射/吸收模型定义为
\[\begin{equation} L(\mathbf p, \omega_{\text{o}}) = \int_{t_0}^{t_1} T(\mathbf p, \omega_{\text{o}}, t_0, t) \sigma(\mathbf p + t\omega_{\text{o}}) L_{\text{e}}(\mathbf p + t\omega_{\text{o}}, -\omega_{\text{o}}) \, dt \, , \end{equation}\]其中 $\sigma$ 是某一点的体积密度, $L_{\text{e}}$ 是某一点和方向的发射光,而透射率 $T$ 是一个嵌套的积分表达式
\[\begin{equation} T(\mathbf p,\, \omega_{\text{o}},\, t_0, \, t) = \exp\left(- \int_{t_0}^t \sigma(\mathbf p + s\omega_{\text{o}}) \, ds \right) \, . \end{equation}\]密度表示一条光线在某一点与场景的体积 “介质 “相互作用的不同概率,而透射率则描述了光线在从某一点 $p + t\omega_{\text{o}}$ 向摄像机返回的过程中会被衰减的程度。
这些表达式只能对简单的密度和颜色场进行分析评估。在实践中,我们通常使用正交法对积分进行近似计算,其中 $\sigma$ 和 $L_{\text{e}}$ 被假定为在一组在一组分割光线长度的 $N$ 区间 ${[t_{i-1}, t_i)}_{i=1}^N$ 内是片状恒定的。
\[\begin{align} L(\mathbf p,\, \omega_{\text{o}}) \,&\approx \, \sum_{i=1}^N T_i \alpha_i \, L_{\text{e}}^{(i)} \, , \\ T_i &= \exp\left(- \sum_{j=1}^{i-1} \Delta_j \sigma_j \right) \, , \\ \alpha_i &= 1 - \exp(-\Delta_i \sigma_i) \, , \\ \Delta_i &= t_i - t_{i-1} \, . \end{align}\]关于这个近似的完整推导,我们请读者参考Max和Chen [MC10]。请注意,当写成这种形式时,近似 $L$ 的表达式完全对应于阿尔法合成的颜色 $L_{text{e}}^{(i)}$ 从后面到前面[PD84]。
NeRF[MST20]和相关的方法(例如[MBRS21,NG21b,PCPMMN21,SDZ21,ZRSK20,NSP21])使用可微分体积渲染将场景表示投射到二维图像。这使得这些方法可以在 “逆向渲染 “框架中使用,即从二维图像中估计出一个三维或更高维度的场景表征。体积渲染需要沿射线处理许多样本,每个样本都需要通过网络进行完整的前向传递。最近的工作提出了增强数据结构[general21, HSM21,GKJ21]、修剪[LGL20]、重要性采样[NSP21]、快速集成[LMW21]和其他策略来加速渲染速度,尽管这些方法的训练时间仍然很慢。自适应坐标网络使用多分辨率网络架构加速训练,该架构在训练阶段通过以最佳和有效的方式分配可用的网络容量进行优化[MLL21]。
3.3. 优化
训练神经网络的核心是一个非线性优化,旨在应用训练集的约束条件,以获得一组神经网络权重。因此,由神经网络近似的函数适合于给定的训练数据。通常情况下,神经网络的优化是基于梯度的;更具体地说,利用SGD的变体,如Momentum或Adam[KB14],其中梯度是通过利用反向传播算法获得。在神经渲染的背景下,神经网络实现了三维场景的表示,而训练数据包括对场景的二维观察。使用神经场景表征的可微分渲染得到的渲染结果与使用各种损失函数的给定观测结果进行比较。这些重建损失可以用每个像素的L1或L2项来实现,也可以使用感知[JAF16]甚至是基于判别器的损失公式[GPAM14]。然而,关键是这些损失直接与各自的可分化渲染公式相联系,以便更新场景表征,参见第3.1节。
4. 应用
在这一节中,我们将讨论神经渲染的具体应用和底层神经场景表征。我们首先在第4.1节中讨论了对静态内容的新型视图合成的改进。然后,我们在第4.2节中概述了跨越物体和场景的通用方法。之后,第4.3节讨论了非静态、动态场景。接下来我们在第4.4节中讨论编辑和合成场景。然后,我们在第4.5节中概述了重新打光和材料编辑。最后,我们在第4.6节中讨论了几个工程框架。我们还对每种应用的不同方法进行了分类。表1、表2、表3、表4和表5中分别列出了这些方法。
4.1. 静态内容的新视图合成
| Method | Required Data |
Requires Pre-trained NeRF |
3D Representation |
Persistent 3D |
Network Inputs |
Code |
|---|---|---|---|---|---|---|
| Mildenhall et al. [MST20] | I+P | ✗ | V | F | PE(P)+ PE(V) | Link |
| Sitzman et al. [SZW19] | I+P | ✗ | S | P | P | Link |
| Niemeyer et al. [NMOG20] | I+P+M | ✗ | O | F | P | Link |
| Chen et al. [CZ19] | S | ✗ | O | F | P | Link |
| Gu et al. [LGL20] | I+P | ✗ | G+V | F | PE(P)+ PE(V) | Link |
| Lindell et al. [LMW21] | I+P | ✗ | V | P | PE(P)+ PE(V) | Link |
| Reiser et al. [RPLG21] | I+P | ✓ | G+V | F | PE(P)+ PE(V) | Link |
| Garbin et al. [GKJ21] | I+P | ✓ | G | F | P+V | ✗ |
| Hedman et al. [HSM21] | I+P | ✓ | G | F | P + PE(V) | Link |
| Yu et al. [general21] | I+P | ✓ | G | F | P+V | Link |
| Neff et al. [NSP21] | I+P+D | ✗ | V | F | PE(P)+ PE(V) | Link |
| Sitzman et al. [SRF21] | I+P | ✗ | ✗ | N | L | Link |
表1:第4.1节中介绍的用于静态场景视图合成的部分方法。尽管其中一些表示方法被用于静态场景视图合成之外的应用,但在本表中,我们仅根据其用于静态场景视图合成的基础三维场景表示方法对这些方法进行分类。I: 图像,P:相机姿势(精确或近似),S:三维形状,M:物体掩码,D:深度。G:网格,V:神经体积,S:神经SDF,O:神经占位。F:完全。P:部分,N:不保证。P:3D位置,V:2D观察方向,L:光场射线坐标。PE():参数的位置编码。
新颖的视图合成是指从新的摄像机位置渲染给定场景的任务,给定的是一组图像和它们的摄像机姿势作为输入。本节后面介绍的大多数应用都以某种方式概括了视图合成的任务:除了能够移动摄像机之外,它们还可能允许移动或变形场景中的物体,改变照明,等等。
视图合成方法是根据几个突出的标准进行评估的。显然,输出的图像应该看起来尽可能的逼真。然而,这并不是故事的全部–也许更重要的是多视图三维一致性。当摄像机在场景中移动时,渲染的视频序列必须看起来描绘出一致的三维内容,没有闪烁或扭曲。随着神经渲染领域的成熟,大多数方法都朝着产生一个固定的三维表示的方向发展,作为输出,可用于渲染新的二维视图,如在范围内解释。这种方法自动提供了一定程度的多视图一致性,而在历史上,如果过于依赖黑盒子的二维卷积网络作为图像生成器或渲染器,是很难实现的。
在表1中,我们对所讨论的方法进行了概述。
4.1.1. 从三维体素网格表征进行视图合成
我们将简要回顾一下使用三维体素网格和体积渲染模型进行视图合成的最新历史。
DeepStereo[FNPS16]提出了第一个用于视图合成的端到端深度学习管道。这项工作包括了许多现在已经变得普遍的概念。卷积神经网络以平面扫描体积(PSV)的形式呈现输入图像,其中每个附近的输入都被重新投射到一组候选深度平面,要求网络简单地评估每个候选深度的每个像素的重新投射的匹配程度。CNN的输出被转换为一个使用softmax的深度概率分布,然后被用来结合一叠拟议的彩色图像(每个深度平面一个)。最终的损失只在渲染的输出和保持的目标图像之间的像素级差异上执行,不需要中间的启发式损失。
DeepStereo的一个主要缺点是,它需要运行一个CNN来估计深度概率,并独立产生每个输出帧,导致运行时间缓慢,并缺乏多视图的3D一致性。Stereo Magnification[ZTF18]直接解决了这个问题,使用CNN将一个平面扫描体积直接处理成一个名为 “多平面图像 “或MPI的输出持久的三维体素网格表示。渲染新的视图只需要使用alpha合成,从新的位置渲染RGB-alpha网格。为了实现高质量的图像,立体放大法严重扭曲了其三维网格的参数化,使其偏向于两个输入视图中的一个参考框架。这大大降低了对密集网格的存储要求,但意味着新的视图只能在输入立体对的直接邻近区域进行渲染。后来通过改进单个MPI的训练程序[STB19],为网络提供多于两幅的输入图像[FBD19],或将多个MPI组合在一起表示一个场景[MSOC19]来解决这一缺陷。
上述所有方法都使用前馈神经网络从有限的输入图像集映射到输出图像或三维表示,并且必须在大量的输入/输出视图对数据集上进行训练。相比之下,DeepVoxels[STH19]使用单一场景的图像,与学习的渲染器共同优化三维体素网格的特征,而不需要任何外部训练数据。同样,Neural Volumes[LSS19]优化了一个三维CNN,为单一场景的多视图视频数据产生一个输出的体积表示。这种单一场景的训练范式最近大为流行,利用了视图合成的独特的 “自我监督 “方面:任何输入图像也可以通过重渲染损失作为监督。与基于MPI的方法相比,DeepVoxels和Neural Volumes还使用了一个三维体素网格参数化,它不严重偏向于一个特定的观察方向,允许从任何方向渲染观察重建的场景的新颖视图。
值得一提的是,一些主要集中在三维形状重建(而不是现实的图像合成)的计算机视觉论文采用了阿尔法合成体积渲染模型,与这种视图合成研究并行[HRRR18, KHM17, TZEM17];然而,这些结果受到三维CNN的内存限制的严重制约,无法产生超过 $128^3$ 分辨率的体素网格输出。
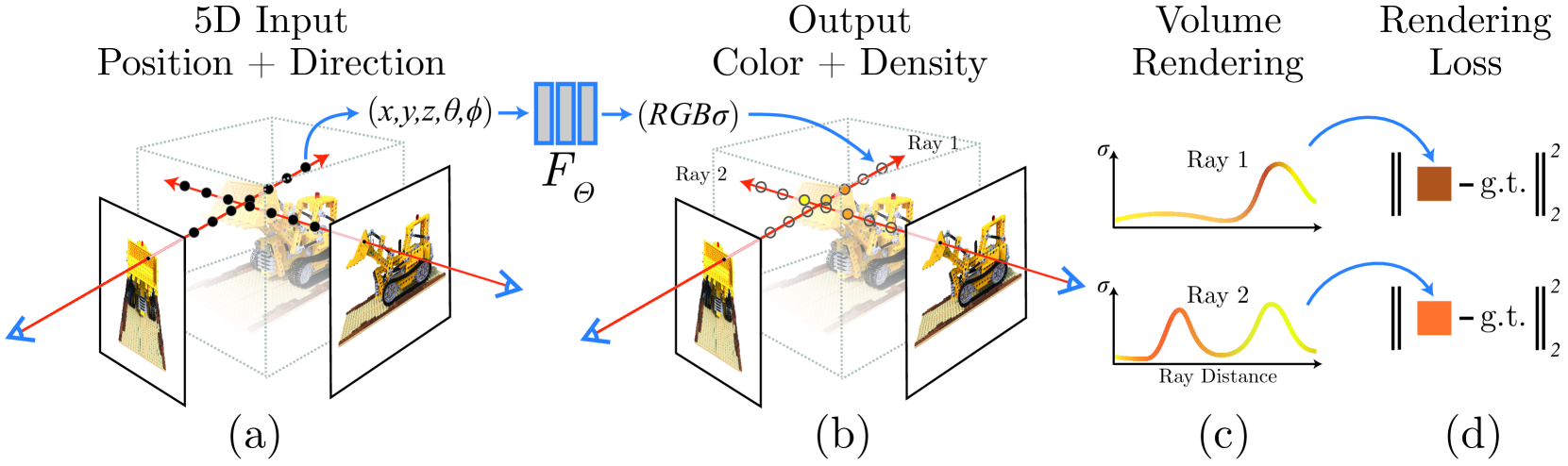
图4:神经辐射场(NeRF)的场景表示和体积渲染程序的概述。NeRF通过沿相机射线的5D坐标(位置和观察方向)采样来合成图像(a),将这些位置输入MLP以产生颜色和体积密度(b),并使用体积渲染将这些值合成为图像(c)。由于这个渲染函数是可微分的,NeRF场景表示MLP可以通过最小化合成图像和真实观察图像之间的残差来进行优化(d)。推荐使用数字变焦。图片改编自[MST20]。
4.1.2. 从神经网络表示的视图合成
为了解决体素网格的分辨率和内存限制,场景表示网络(SRNs)[SZW19]将基于球体追踪的神经渲染器与多层感知器(MLP)结合起来作为场景表示,主要关注跨场景的泛化,以实现少数照片的重建。Differentiable Volumetric Rendering(DVR)[NMOG20]同样利用了表面渲染的方法,但证明了在单一场景上的过度拟合能够重建更复杂的外观和几何形状。
神经辐射场(NeRF[MST20]标志着基于MLP的场景表征在单场景、逼真的新颖视图合成中的应用取得了突破,见图4。NeRF没有采用基于表面的方法,而是直接应用第3.2.2节中描述的体积渲染模型,从输入位置和观察方向映射到输出体积密度和颜色的MLP来合成图像。一组不同的MLP权重被优化,以代表每一个新的输入场景,基于对输入图像的像素化渲染损失。
这个整体框架与上一节所述的工作有许多相似之处。然而,基于MLP的场景表示可以实现比离散的三维体积更高的分辨率,因为在优化过程中有效地对场景进行微分压缩。例如,一个能够渲染 $800 \times 800$ 分辨率输出图像的NeRF表示只需要5MB的网络权重。相比之下,一个 $800^3$ RGBA体素网格将消耗接近2GB的存储空间。
这种能力可以归因于NeRF在通过MLP之前对输入的空间坐标进行了位置编码的使用。与之前使用神经网络表示隐性表面[PFS19, CZ19]或体积[MON19]的工作相比,这使得NeRF的MLP可以在不增加其容量(就网络权重数量而言)的情况下表示更高频率的信号。
从离散的三维网格切换到基于MLP的表示方法的主要缺点是渲染速度。与其直接查询一个简单的数据结构,现在计算空间中一个点的颜色和密度值需要评估整个神经网络(几十万次浮点运算)。在一个典型的桌面GPU上,一个标准的深度学习框架中的NeRF的实现需要几十秒的时间来渲染一个高分辨率的图像。
4.1.3. 提高渲染速度
已经提出了几种不同的方法来加快基于MLP表示的体积渲染。神经稀疏体素场[LGL20]在优化MLP的同时建立并动态更新一个八叉树结构,允许积极跳过空隙和提前终止射线(当沿射线的透射率接近零时)。KiloNeRF[RPLG21]将跳空和提前终止与密集的三维网格MLP结合起来,每个网格的权重数量比标准NeRF网络小得多。
最近有三项同时进行的工作提出了在稀疏的三维网格上缓存NeRF MLP所学到的各种数值的方法,允许在训练完成后进行实时渲染。每种方法都修改了预测与视图有关的颜色的方式,以促进更快的渲染和更小的内存需求,用于缓存的表示。SNeRG[HSM21]在稀疏的三维纹理图集中存储体积密度和一个小的空间变化特征向量,使用快速着色器沿射线合成这些值,并运行一个微小的MLP解码器,为每条射线产生依赖视图的颜色。FastNeRF[GKJ21]将体积密度与权重一起缓存起来,用于组合一组学习过的球面基函数,在三维中的每一点产生随视图变化的颜色。PlenOctrees[YLT21]查询MLP以产生体积密度和球面谐波系数的稀疏体素八叉树,并使用渲染损失进一步微调这个八叉树表示,以提高其输出图像质量。
NeX-MPI[WPYS21]将多平面图像参数化与MLP场景表示相结合,将视图相关效应参数化为全局学习的基础函数的线性组合。由于该模型直接在三维MPI坐标网格上进行监督,一旦优化完成,该网格可以很容易地被缓存以实时渲染新视图。
另一种加速渲染的方法是训练MLP表征本身,以有效地预先计算沿射线的部分或全部体积积分。AutoInt[LMW21]通过监督网络的梯度表现得像一个标准的NeRF MLP,来训练一个网络沿着射线段 “自动整合 “输出颜色值。这使得渲染步骤可以将沿射线的积分分解成比标准正交估计少一个数量级的片段(少到2或4个样本),以速度换取质量上的微小损失。光场网络[SRF21]更进一步,优化MLP以直接编码从输入光线到输出颜色(场景的光场)的映射。这使得渲染时,每条光线只需对MLP进行一次评估,而基于体积和表面的渲染器则需要进行数百次评估,并能实现实时的新颖视图合成。这些方法在渲染速度和多视点一致性之间进行了权衡:将MLP表示作为射线而非三维点的函数进行重新参数化,意味着从不同角度看,场景不再被保证是一致的。在这种情况下,多视角一致性必须通过监督来实施,要么提供大量的输入图像,要么通过在三维场景的数据集上的概括来学习这一特性。
4.1.4. 其他改进措施
多篇论文增强了渲染模型、监督数据或体积MLP场景表示的鲁棒性。
深度监督。DONeRF[NSP21]训练了一个 “深度神谕 “网络来预测每条光线的样本位置,大大减少了通过NeRF MLP发送的样本数量,并允许进行交互式速率渲染。然而,这种方法是用密集的深度图来监督的,而对于真实数据来说,这是很有挑战性的。深度监督的NeRF[DLZR21]使用稀疏的点云输出直接监督NeRF的输出深度(以沿每条射线的预期终止深度的形式),该点云是使用从运动结构中估计摄像机位置的副产品。NerfingMVS[WLR21]使用多级管道进行深度监督,首先在稀疏的从运动中获得的深度估计上对单视角深度估计网络进行微调,然后使用产生的密集深度图来指导NeRF优化。
优化相机姿态。NeRF-[WWX21]和自校准神经辐射场[JAC21]联合优化NeRF MLP和输入摄像机的姿势,绕过了对前向场景的结构-运动预处理的需要。Bundle-Adjusting Neural Radiance Fields(BARF)[LMTL21]通过对位置编码函数的每个频率分量应用从粗到细的退火计划扩展了这一想法,为联合重建和摄像机注册提供了一个更平滑的优化轨迹。然而,这些方法都不能为宽基线的360度捕捉从头开始优化姿势。GNeRF[MCL21]通过训练一组循环一致的网络(一个生成性的NeRF和一个姿势分类器)来实现这一点,这些网络从姿势映射到图像斑块,再返回到姿势,优化直到真实斑块的分类姿势与采样斑块的姿势相匹配。他们将这个GAN训练阶段与标准的NeRF优化阶段交替进行,直到结果收敛。
混合表面/体积表示法。Yariv等人[YKM20]提出的隐性微分渲染器(IDR)将一个类似DVR的隐性表面MLP与一个类似NeRF的视图分支结合起来,该分支将观察方向、隐性表面法线和三维表面点作为输入并预测视图变化的输出颜色。这项工作表明,将法线矢量作为颜色分支的输入有助于更有效地分解几何和外观的表示。它还表明,摄像机的姿势可以与形状表示法一起联合优化,以便从小的误判错误中恢复。
UNISURF[OPG21]提出了一种混合MLP表示,统一了表面和体积渲染。为了渲染一条射线,UNISURF使用寻根法得到一个 “表面 “交点,将体积视为一个占用场,然后仅在该点周围的一个区间内分配体积渲染样本。这个区间的宽度在优化过程中单调地减少,允许早期迭代监督整个训练体积,而后期阶段则用紧密间隔的样本更有效地细化表面。Azinovic等人[AMBG21]提出使用SDF表示而不是体积密度来重建RGB-D数据的场景。他们将sdf值转换为可用于NeRF公式的密度。NeuS[WLL21]将体积密度与有符号的距离场联系起来,并重新参数化透射率函数,使其在这个SDF的零交叉点上精确地达到最大斜率,从而允许对相应的表面进行无偏估计。VolSDF[YGKL21b]使用了一种从SDF到体积密度的替代映射,这使得他们能够设计出一种新的重采样策略,以实现体积渲染正交方程中近似不透明度的可证明的约束误差。在[LFS21]中,作者提出了一种名为MINE的方法,它是多平面图像(MPI)和NeRF之间的混合体。他们能够从单色图像中重建密集的三维重建,他们在RealEstate10K、KITTI和Flowers光场上进行了演示。
稳健性和质量。NeRF++[ZRSK20]提供了一个 “倒置球体 “的空间参数化,可以使NeRF用于大规模、无边界的三维场景。单位球体外的点被倒回单位球体中,并通过一个单独的MLP。
NeRF in the Wild [MBRS21]为MLP表示法增加了额外的模块,以考虑不同图像中不一致的照明和物体。他们将其强大的模型应用于PhotoTourism数据集[SSS06](由世界各地著名地标的互联网图像组成),并能够通过使用与每个输入图像相关的潜伏代码嵌入,去除人和汽车等瞬时物体,并捕捉时间变化的外观。
MipNeRF[BMT21]修改了应用于三维点的位置编码,以纳入像素足迹,见图5。通过预先将位置编码整合到与沿射线采样的每个正交段相对应的圆锥体上,MipNeRF可以被训练成在多个不同尺度上对场景进行编码(类似于二维纹理的mipmap),防止在从不同的位置或分辨率渲染场景时出现混叠。Mip-NeRF 360 [BMV21] 。扩展了MipNeRF,并解决了在无边界场景中训练时出现的问题。训练时出现的问题(近处和远处物体的不平衡细节 导致模糊的、低分辨率的结尾),其中摄像机围绕一个点旋转了360度。它利用了在线场景参数化、在线蒸馏和一个新的基于变形的基于正则器。
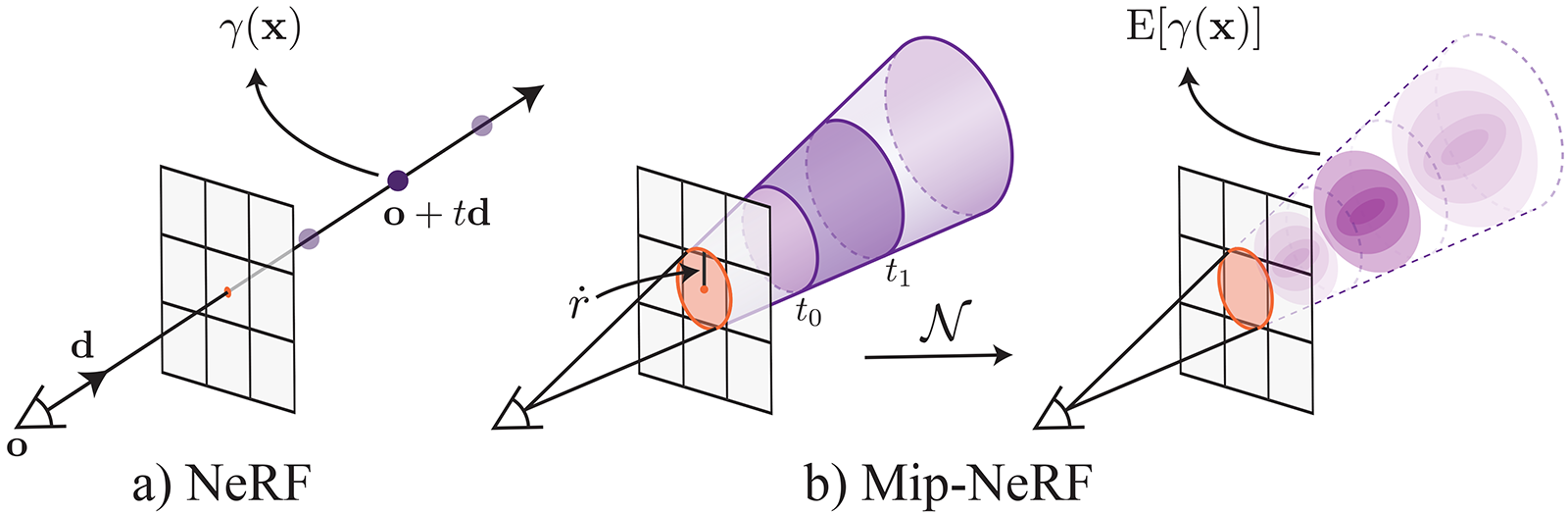
图5:MipNeRF[BMT21]不是沿着从相机投影中心追踪的射线取样(a),而是对每个相机像素的三维典型地壳进行采样(b)。图片改编自[BMT21]。
NeRF和计算成像。最近有几项工作将NeRF与标准的计算成像任务相结合。DeblurNeRF [ML 21a]联合优化了一个静态的NeRF表示,以及训练集中每个像素的每个射线偏移,这些偏移考虑了由于相机运动或景深造成的模糊。一旦优化完成,可以在不应用射线偏移的情况下渲染NeRF,以获得清晰的测试视图。黑暗中的NeRF[MHMB21]直接对原始线性相机数据进行训练,以实现对高水平图像噪声的改进,允许重建黑暗的夜间场景,以及恢复完整的高动态范围辐射值。HDR-NeRF [HZF21]同样恢复了线性值的HDR NeRF,但是通过使用后处理的可变曝光图像作为输入,并求解非线性相机后处理曲线,在应用于优化的NeRF时再现输入。NeRF-SR [WWG21a]在训练过程中对每个像素的多条超采样光线进行平均,并且通过使用CNN将渲染的图像斑块与场景的高分辨率参考图像的类似斑块合并,对渲染的图像斑块进行超分辨率处理。
大尺度场景。最近的一系列出版物关注大规模的神经辐射场。它们能够重新渲染街景数据[RLS21]、建筑物和整个城市[XXP21, TRS21],甚至是地球尺度[XXP21]。为了处理这样的大场景,这些方法通过将场景分解为空间单元[TRS21]或不同尺度[XXP21](包括渐进式训练方案)来使用本地化的NeRFs。URF[RLS21]利用了额外的激光雷达数据来监督深度预测。在这些大规模的场景中,必须特别注意处理天空和高度变化的曝光和光照变化(参见NeRF-W [MBRS21])。NeRF-W[MBRS21]在学习到的表象之间进行插值,但不提供对它的语义控制。NeRF-OSR[RES21]是第一个允许联合编辑摄像机视点和建筑物及历史遗迹照明的方法。对于训练,NeRF-OSR需要在不受控制的环境中拍摄的室外照片集(进一步的细节见第4.5节)。
来自文本的NeR。NeRF公式[MST20]是一个基于优化的框架,它也允许我们在优化过程中纳入其他能源条款。为了通过文本输入来操纵或生成NeRF,我们可以采用一个(预训练的)基于CLIP的目标[RKH21]。梦想领域[JMB21]将NeRF与CLIP结合起来,仅从自然语言描述中产生多样化的三维物体,通过基于图像标题上的CLIP分数的多视图约束来优化辐射场。CLIPNeRF [WCH21]提出了一个基于CLIP的形状和外观映射器来控制一个有条件的NeRF。
4.2. 物体和场景类的泛化
| Method | Conditioning | Required Data |
3D Repre- sentation |
Class Specific Prior |
Generative Model |
Inference Type |
Code |
|---|---|---|---|---|---|---|---|
| Yu et al. [YYTK21] | L | G | V | ✗ | ✗ | A | Link |
| Raj et al. [RZS20] | L | F | V | ✗ | ✗ | A | ✗ |
| Trevithick et al. [TY20] | L | G | V | ✗ | ✗ | A | Link |
| Wang et al. [WWG21] | L | G | V | ✗ | ✗ | A | ✗ |
| Reizenstein et al. [RSH21] | L | G | V | ✗ | ✗ | A | ✗ |
| Sitzmann et al. [SZW19] | G | G | S | ✓ | ✓ | D | Link |
| Kosiorek et al. [KSZ21] | G | G | V | ✗ | ✓ | A | ✗ |
| Rematas et al. [RMBF21] | G | G | V | ✓ | ✓ | D | Link |
| Xie et al. [XPMBB21] | G | G | V | ✗ | ✗ | A | ✗ |
| Tancik et al. [TMW21] | G | G | V | ✗ | ✗ | GB | Link |
| Gao et al. [GSL20] | G | F | V | ✗ | ✗ | GB | ✗ |
| Nguyen-Phuoc et al. [NPLT19] | G | G | V | ✓ | ✓ | ✗ | Link |
| Schwarz et al. [SLNG20] | G | G | V | ✓ | ✓ | ✗ | ✗ |
| Chan et al. [CMK21] | G | G | V | ✓ | ✓ | ✗ | Link |
| Anonymous [Ano22] | G | G | V | ✓ | ✓ | ✗ | ✗ |
| Niemeyer et al. [NG21a] | G | G | V | ✓ | ✓ | ✗ | ✗ |
表2:第4.2节中提出的一些泛化方法。G:全局,L:局部。I: 隐性的,E:显性的。G:一般,B:身体,F:面部。A:摊销/编码器,D:自动解码器,GB:基于梯度的。V:神经体积,S:神经SDF。
虽然之前有大量的工作涉及到基于体素、基于网格或非三维结构的神经场景表征在多个场景和物体类别上的泛化,但我们在此重点讨论利用基于MLP的场景表征进行泛化的最新进展。在单一场景上过度拟合单一MLP的方法[MST20,YKM20]需要大量的图像观测,而跨场景表征泛化的核心目标是给定少数或可能只有单一输入视图的新颖视图合成。在表2中,我们对所讨论的方法进行了概述,按照它们是否利用局部或全局条件、它们是否可以用作无条件生成模型、它们利用哪种三维表征(体积、SDF或占用)、它们需要哪种训练数据以及如何进行推理(用编码器摊销、通过自动解码器框架或通过基于梯度的元学习)来分类。
![]()
图6:来自DTU MVS数据集[JDV14]的输入图像和由PixelNeRF[YYTK21]获得的没有测试时间优化的新视图。此外,训练和测试集不共享相同的场景。图片改编自[YYTK21]。
我们可以区分两个关键的跨场景泛化的方法。其中一种工作方法让人想起基于图像的渲染[CW93, SK00],其中多个输入视图被扭曲和混合以合成一个新的观点。在基于MLP的场景表示的背景下,这通常是通过局部调节来实现的,其中场景表示MLP的坐标输入与局部变化的特征向量相连接,存储在离散的场景表示中,如体素网格[PNM20]。PiFU[SHN19]使用一个图像编码器来计算输入图像上的特征,并通过在图像平面上投射三维坐标来确定这些特征的三维MLP的条件–然而,PiFU并没有一个可区分的渲染器,因此需要地面真实的三维监督。PixelNeRF[YYTK21](见图6)和Pixel-Aligned Avatars[RZS20]在体积渲染框架中利用了这种方法,这些特征在多个视图上聚集,MLP产生颜色和密度场,像NeRF中那样进行渲染。当对多个场景进行训练时,他们学会了用于重建的场景先验,从而能够从几个视图中高保真地重建场景。PixelNeRF也可以在特定的物体类别上进行训练,使物体实例从一个或多个摆放的图像中进行三维重建。GRF[TY20]使用了一个类似的框架,有一个额外的注意力模块来推理不同采样输入图像中的三维点的可见性。Stereo Radiance Fields[CBLPM21]同样从几个上下文视图中提取特征,但利用学习到的跨上下文图像的成对特征之间的对应匹配来聚合跨上下文图像的特征,而不是简单的平均聚合。最后,IBRNet[WWG21]和NeRFormer[RSH21]引入了跨射线样本的变换器网络,对可见度进行推理。
这种基于图像的方法的一个替代方案旨在学习一个整体的、全局的场景表示,而不是依赖图像或其他离散的空间数据结构。这是通过推断一套描述整个场景的场景表示MLP的权重来实现的,给定的是一组观测数据。有一项工作是通过将场景编码为单一的、低维的潜伏代码来实现的,该代码随后被用于调节场景表示MLP。场景表示网络(SRNs)[SZW19]通过超网络将低维潜伏代码映射到MLP场景表示的参数中,随后通过射线行进渲染产生的三维MLP。为了重建一个给定视图的实例,SRN优化潜伏代码,使其渲染与输入视图相匹配。Differentiable Volumetric Rendering[NG20]同样使用表面渲染,但是通过分析计算其梯度并通过CNN编码器进行推理。光场网络[SRF21]利用低维潜伏代码直接对三维场景的四维光场进行参数化,实现了单次评估渲染。NeRF-VAE将NeRF嵌入到变异自动编码器中,类似于用单一的潜伏代码表示整个场景,但是学习一个生成模型,从而实现采样[KSZ21]。Sharf[RMBF21]使用一个类别中物体体素化形状的生成模型,这反过来又为更高分辨率的神经辐射场提供了条件,该神经辐射场使用体积渲染法进行渲染,以获得更高的新视点合成保真度。Fig-NeRF[XPMBB21]将一个物体类别建模为以潜伏代码为条件的模板形状,该模板经历了一个变形,该变形也以同一潜伏变量为条件。这使得网络能够将某些形状变化解释为更直观的变形。Fig-NeRF专注于从真实的物体扫描中检索物体类别,并且还提出使用学习背景模型将物体从其背景中分割出来。将场景表示为低维潜伏代码的一个替代方案是通过基于梯度的元学习[SCT20],在几个优化步骤中快速优化MLP场景表示的权重。这可以用来实现从少数图像快速重建神经辐射场[TMW21]。当在一个新的场景上训练时,预训练的模型收敛得更快,而且与标准的神经辐射场训练相比,需要更少的视图。PortraitNeRF[GSL20]提出了一种元学习方法,从一个人的单一正面图像中恢复NeRF。为了考虑主体之间的姿势差异,它在一个姿势无关的典型参考框架中对三维肖像进行建模,该框架使用三维关键点对每个主体进行扭曲。Bergman等人[BKW21]利用基于梯度的元学习和图像特征的局部调节来快速恢复一个场景的新NeRF。
与其根据对所寻求的3D场景的一组观察结果推断出低维潜伏代码,不如利用类似的方法来学习无条件的生成模型。在这里,一个配备了神经渲染器的三维场景表示被嵌入到一个生成对抗网络中。我们不是从一组观测值中推断出低维潜伏代码,而是定义一个潜伏代码的分布。在一个前向通道中,我们从该分布中抽出一个潜代码,在该潜代码上设置MLP场景表示的条件,并通过神经呈现器呈现一个图像。然后,该图像可用于对抗性损失。这使得我们能够在只给定二维图像的情况下学习三维场景的形状和外观的三维生成模型。这种方法最早是通过体素网格参数化的三维场景表示法提出来的[NPLT19]。GRAF[SLNG20]首次在这个框架中利用了有条件的NeRF,并在逼真度方面取得了重大改进。Pi-GAN[CMK21]通过SIREN架构[SMB20]的基于FiLM的调节方案[PSDV18]进一步改进了这个架构。StyleNeRF[Ano22]通过采用StyleGAN的条件机制进一步提高了图像质量,并通过只利用NeRF生成低分辨率的特征图和随后用精心设计的上采样网络进行上采样来提高运行时间(实现更高分辨率的图像生成),以避免混叠,确保多视图的一致性。虽然这些方法不需要对每个三维场景进行更多的观察,因此也不需要地面真实的相机姿势,但它们仍然需要了解相机姿势的分布(例如,对于人像图像,相机姿势的分布必须产生合理的人像角度)。CAMPARI [NG21a]通过联合学习相机姿势分布和生成模型来解决这个约束。GIRAFFE [NG21b]提出通过将一个场景参数化为几个前景(物体)NeRF和一个背景NeRF的组成,来学习由几个物体组成的场景的生成模型。每个NeRF的潜伏代码被分别采样,然后由一个体积渲染器将它们组合成一个连贯的2D图像。
4.3. 学习表现和渲染非静态内容
| Method | Data | Deformation | Class-Specific
Prior | Controllable
Parameters | Code |
| :—: | :—: | :—: | :—: | :—: | :—: |
| Lombardi et al. [LSS21] | MV | I | G | V,R | Link |
| Li et al. [LNSW21] | MV | I | G | V,R | ✗ |
| Xian et al. [XHKK21] | Mo | I | G | V,R | ✗ |
| Gao et al. [GSKH21] | Mo | I | G | V,R | ✗ |
| Du et al. [DZY21] | Mo | I | G | V,R | Link |
| Pumarola et al. [PCPMMN21] | Mo | E | G | V,R | Link |
| Park et al. [PSB21] | Mo | E | G | V,R | Link |
| Tretschk et al. [TTG21] | Mo | E | G | V,R | Link |
| Park et al. [PSH21] | Mo | I+E | G | V,R | Link |
| Attal et al. [ALG21] | Mo+D | I | G | V,R | Link |
| Li et al. [LSZ21] | MV | I | G | V,R | ✗ |
| Gafni et al. [GTZN21] | Mo | E | F | V,R,E | Link |
| Wang et al. [WBL20] | MV | I | F | V,R | ✗ |
| Guo et al. [GCL21] | Mo | I | F | V,R,E | Link |
| Noguchi et al. [NSLH21] | Mo+3D | E | B | V,R,E | Link |
| Su et al. [SYZR21] | Mo | E | B | V,R,E | ✗ |
| Peng et al. [PDW21] | MV | E | B | V,R,E | Link |
| Peng et al. [PZX21] | MV | I+E | B | V,R | Link |
| Liu et al. [LHR21] | MV | E | B | V,R,E | ✗ |
| Xu et al. [XAS21] | MV+Mo | I | B | V,R,E | ✗ |
表3:第4.3节中介绍的非静态、动态场景的部分方法。MV:多视图,Mo:单眼,D:深度,3D:三维姿势。I: 隐式地,E: 显式地。G:一般的,B:身体,F:脸/头。V:视点,R:回放,E:编辑。
虽然最初的神经辐射场[MST20]被用来表示静态场景和物体,但也有一些方法可以额外处理动态变化的内容。在表3中,我们对讨论的方法进行了概述。
这些方法可以分为时间变化的表示,允许对动态变化的场景进行新的视点合成,作为未修改的回放(例如,产生子弹时间效果),或者也可以对变形状态进行控制的技术,因此,允许对内容进行新的视点合成和编辑。变形的神经辐射场可以隐式或显式地实现,见图7。
- 隐性地,通过对变形状态的表征(例如,时间输入)调节NeRF
- 显式,通过使用一个单独的变形场,可以从变形空间映射到NeRF被嵌入的典范空间。
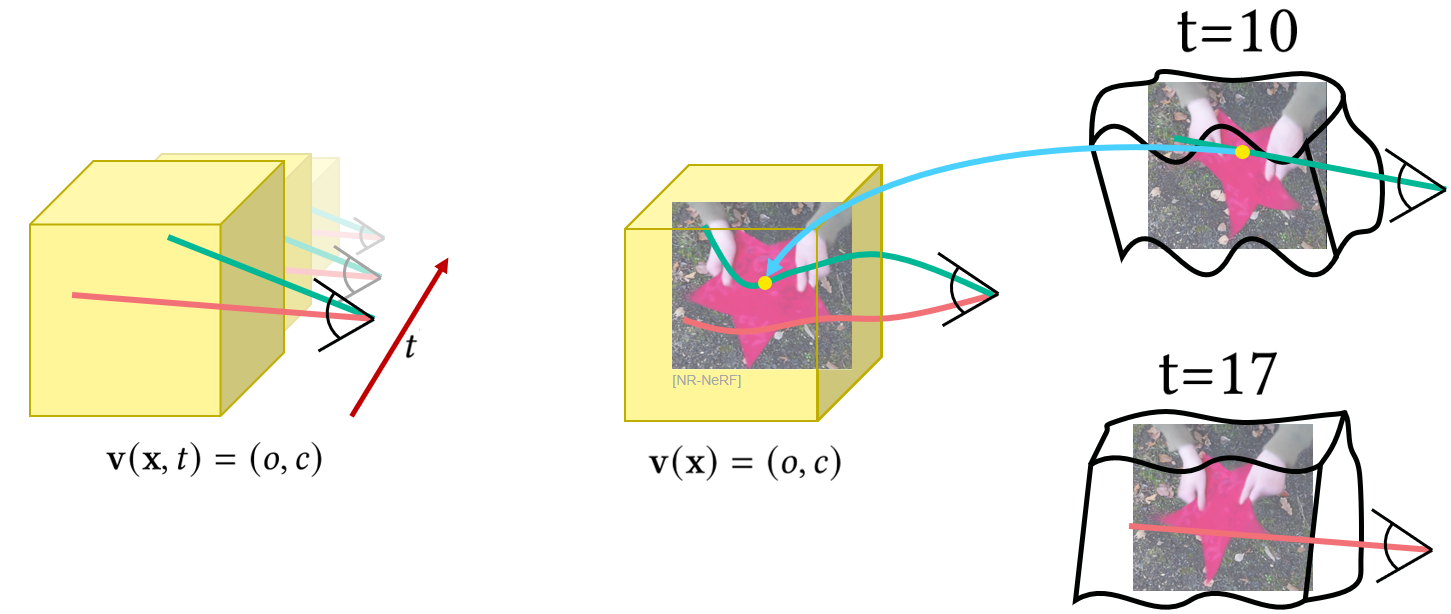
图7:目前用神经辐射场模拟变形的方法分为两类。左边:隐性地,通过对变形(这里:时间)的辐射度场进行调节。右边。明确地,通过使用单独的变形MLP对空间进行扭曲,将偏移量(蓝色箭头)从变形空间(黑色)回归到静态的典型空间(黄色)。这使直射光线弯曲成典范的辐射场。图片改编自[TFT21]。
4.3.1. 时间变化的神经辐射场

图8:Xian等人[XHKK21]的一般可变形场景的输入单眼视频以及通过时空神经辐照度场对其进行的新颖视图渲染。图片改编自[XHKK21]。
时间变化的神经辐射场允许用新的视点播放视频,见图8。由于放弃了控制,这些方法不依赖于特定的运动模型,因此可以处理一般物体和场景。
针对非刚性场景的NeRF的几个扩展也同时被提出。我们首先讨论隐含变形模型的方法[LNSW21, XHKK21, GSKH21, DZY21] 。虽然原始的NeRF是静态的,并且只需要输入一个三维空间点,但它可以以一种直接的方式扩展为时间变化的:体积可以额外地以一个代表变形状态的向量为条件。在目前的方法中,这种条件采取了时间输入(可能是位置编码)的形式[XHKK21, LNSW21, GSKH21, DZY21, PCPMMN21]或每个时间步长自动解码的潜伏代码[PSB21, TTG21, PSH21]。
由于在没有事先了解物体类型或三维形状的情况下处理非刚性场景是一个棘手的问题,这类方法采用了各种几何正则器,并以额外的数据模式作为学习条件。为了鼓励不同时间的反射率和不透明度的一致性,一些方法在时间上相邻的时间步骤之间学习场景流映射[LNSW21, XHKK21, GSKH21, DZY21]。由于这只限于小的时间邻域,无伪影的新视角合成主要表现在与时空输入相机轨迹接近的时空上。场景流映射可以通过重建损失来训练,该损失将场景从其他时间步骤扭曲到当前时间步骤[LNSW21, DZY21],通过鼓励估计的光流和场景流的二维投影之间的一致性[LNSW21, GSKH21],或者通过跟踪三维中的反投影关键点[DZY21]。场景流经常受到额外的正则化损失的约束[LNSW21, XHKK21, GSKH21, DZY21],例如,鼓励空间或时间上的平滑性或前向-后向循环的一致性。与其他提到的方法不同,Du等人[DZY21]的Neural Radiance FLow(NeRFlow)用无穷小的位移来模拟变形,需要与Neural ODE[CRBD18]集成以获得偏移量。 此外,一些方法使用估计的深度图来监督几何估计[LNSW21, XHKK21, GSKH21, DZY21]。这种正则化的一个限制是,重建的准确性取决于单眼深度估计方法的准确性。因此,单眼深度估计方法的伪影在新的视图中是可以识别的[XHKK21]。
最后,静态背景通常被单独处理,使其能够利用跨时间的单眼输入记录的多视图线索。为此,一些方法估计了不以变形为条件的第二个静态体积[LNSW21, GSKH21],或者引入软正则化损失来约束静态场景内容[XHKK21]。Gao等人[GSKH21]是Xian等人的工作[XHKK21]的后续,在二元分割掩码(模型的输入之一,由用户提供)的帮助下,对不包含移动和变形部分的观测结果进行静态NeRF训练。
Guo等人的方法的一个优势是,它在Yoon等人[YKG20]的挑战性数据集上产生了最准确的定量和定性结果(与Tretschk等人[TTG21]和Li等人[LNSW21]相比)。后者的数据集最初被引入,用于从一组相当稀疏的动态场景的输入单眼视图中合成新的视图,摄像机的姿势有适度的变化。该方法的局限性包括对光流的强烈依赖和对任意非刚性变形的处理(与独立刚性运动物体组成的场景相反)。
最后,NeRFlow可以用来对预训练场景的视图进行去噪和超解。作者提到的NeRFlow的局限性包括难以保留静态背景、处理复杂场景(非整体刚性变形和运动)以及在与输入的相机轨迹大不相同的情况下渲染新视图。
到目前为止讨论的方法都是通过对变形的场景表示进行调节来隐含地模拟变形。这使得变形的可控性变得繁琐和困难。其他作品则将变形与几何和外观分离开来:他们在静态典型场景的基础上将变形分解为一个单独的函数,这是实现可控性的关键一步。变形是通过向变形空间发射直线,然后将其弯曲到典型场景中来完成的,通常是通过使用基于坐标的MLP对直线上各点的偏移量进行回归,该MLP是以变形为条件的。这可以被认为是空间扭曲或场景流动。与隐式建模相比,这些方法通过静态典型场景的构建,在不同时间共享几何和外观信息,从而提供不会漂移的硬对应。由于这种硬约束,与隐式方法不同,目前具有显式变形的方法不能处理拓扑变化,只能在运动量明显小于隐式方法的场景中展示结果。
D-NeRF[PCPMMN21]使用非规则化的射线弯曲MLP来模拟从背景中分割出来的单个或多个合成物体的变形,并由虚拟摄像机观察。它假定给定了一组预先定义的多视图图像,尽管在训练时,任何时候都只使用任意选择的单一视图进行监督。因此,D-NeRF可以被认为是多视角监督技术和真正的单眼方法之间的一个中间步骤。
一些作品展示了由移动的单眼相机观察的真实世界场景的结果。Park等人[PSB21]的可变形NeRF的核心应用是创建Nerfies,即自由视角的自拍。可变形的NeRF对每个输入视图的变形和外观进行自动解码的潜在代码。弯曲的射线使用 “尽可能刚性 “项(也被称为弹性能量项)进行规范化,该项对偏离片状刚性场景配置的行为进行惩罚。因此,可变形的NeRF在铰接的场景(例如,握着网球拍的手)和诸如人头的场景(头部相对于躯干移动)上运行良好。不过,由于正则器是软的,小的非刚性变形也能很好地处理(如微笑)。这项工作的另一个重要创新是采用从粗到细的方案,允许首先学习低频成分,避免因过度拟合高频细节而造成局部最小值。 HyperNeRF[PSH21]是Deformable NeRF[PSB21]的一个扩展,使用了一个典型的超空间而不是一个单一的典型框架。这允许处理具有拓扑结构变化的场景,如开口和闭口。在HyperNeRF中,Deformable NeRF的弯曲网络(MLP)被一个环境切片表面网络(同样是MLP)所增强,该网络通过间接调节变形的典范场景,为每个输入的RGB视图选择一个典范子空间。因此,它是一个混合体,结合了显性和隐性的变形建模,这使得它能够通过牺牲硬对应关系来处理拓扑变化。
非刚性NeRF(NR-NeRF)[TTG21]使用每个场景的典型体积、每个场景的刚性标志(一个MLP)和每个帧的光线弯曲算子(一个MLP)对时间变化的场景外观建模。NR-NeRF表明,与[PSB21, XHKK21, LNSW21]相比,处理具有小的非刚性变形和运动的场景不需要额外的监督线索,例如深度图或场景流。此外,观察到的变形被一个发散算子规范化,该算子施加了一个体积保护的约束,并且相对于监督的单眼输入视图稳定了闭塞的区域。在这方面,它与Nerfies的弹性正则器有相似之处,即惩罚偏离片状刚性变形的情况。这种正则化使得新视角的摄像机轨迹有可能与输入的摄像机轨迹大不相同。虽然可控性仍然受到严重限制,但NR-NeRF展示了对所学变形场的几种简单编辑,如运动夸张或去除动态场景内容。
其他作品并不局限于单眼RGB输入视频的情况,而是考虑其他输入。
飞行时间辐射场(TöRF)方法[ALG21]取代了数据驱动的先验,用深度传感器的深度图重建动态内容。与绝大多数计算机视觉作品相比,TöRF使用原始的ToF传感器测量值(所谓的相位),这在处理弱反射区域和现代深度传感器的其他限制(例如,有限的工作深度范围)时带来优势。在NeRF的学习中整合测量到的场景深度,减少了对输入视图数量的要求,从而获得清晰而详细的模型。与NSFF[LNSW21]和时空神经辐照度场[XHKK21]相比,深度线索也能实现卓越的准确性。
神经三维视频合成[LSZ21]使用多视图RGB设置并隐含变形模型。该方法通过首先对关键帧进行训练来利用时间上的平滑性。它还利用了摄像机保持静态以及场景内容主要是静态的特点,通过对射线进行有偏向的采样训练。即使是小的动态内容,其结果也很清晰。
4.3.2.可控制的动态神经辐射场
为了使神经辐射场的变形具有可控性,方法使用特定类别的运动模型作为变形状态的基本代表(例如,人脸的可变形模型或人体的骨骼变形图)。
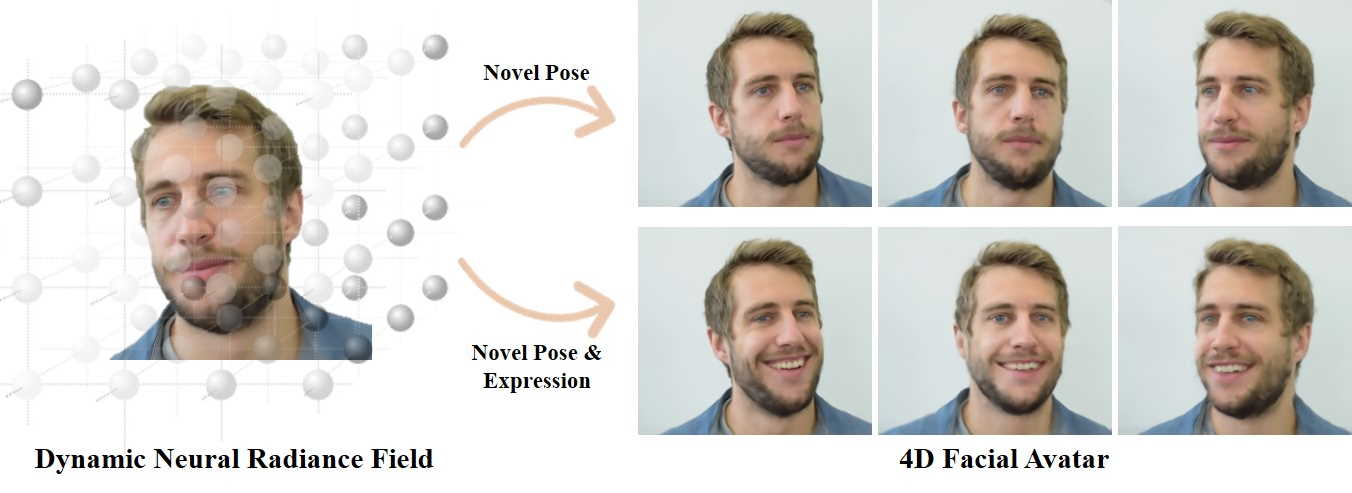
图9:动态神经辐射场来合成人类的新视角和表情。图片改编自[GTZN21]。
NeRFace[GTZN21]是第一个使用可变形模型来隐式控制神经辐射场的方法(见图9)。他们使用人脸跟踪器[TZS16]来重建人脸混合形态参数以及训练视图(单眼视频)中的摄像机姿势。在这些视图中,MLP被训练为混合形状参数和一个可学习的每帧潜伏代码作为条件。此外,他们假设有一个已知的静态背景,这样辐射度场就只储存了关于人脸的信息。潜伏代码被用来补偿丢失的跟踪信息(即人的肩膀)以及跟踪中的错误)。一旦训练完成,辐射场就可以通过blendhape参数进行控制,因此,允许重演和表情编辑。虽然NeRFace使用了基于可变形模型的全局变形代码,但Wang等人[WBL20]产生了局部动画代码。具体来说,他们从多视图输入中提取一个全局动画代码,并使用三维卷积神经网络将其映射到局部代码。这些代码被用来调节精细级别的光芒场,这些光芒场被表示为MLPs。与NeRFace相比,该方法不允许直接控制面部表情,但必须训练一个编码器,例如可以从面部关键点生成动画代码。Guo等人[GCL21]提出了一种音频驱动的神经辐射场(AD-NeRF),其灵感来自NeRFace。但他们没有使用表情系数,而是将使用DeepSpeech[HCC14, TET20]提取的音频特征映射为一个特征,作为代表辐射场的MLP的条件。虽然表情是通过音频信号隐性控制的,但他们对头部的刚性姿势进行了显性控制。为了合成一个人的肖像视图,他们采用了两个独立的辐射场,一个用于头部,一个用于躯干。

图10:神经躯干[PZX21]方法从稀疏的多视角视频中恢复具有精细外观细节的人类3D模型。
虽然上述方法在人像场景中显示了有希望的结果,但它们不适用于高度非刚性的变形,特别是对于从单一视图中捕获的人体的关节运动。因此,方法明确地利用了人体骨架的嵌入。神经铰接辐射场(NARF)[NSLH21]是通过姿势标注的图像进行训练。一个铰接的物体被分解成几个刚性的物体部分,上面有它们的局部坐标系统和全局形状变化。经过收敛的NARF可以通过操纵姿势、估计深度图和执行身体部位分割来渲染新的视图。与NARF相反,A-NeRF[SYZR21]以自我监督的方式从单眼录像中学习特定演员的体积神经身体模型。该方法将动态NeRF体积与关节型人体骨架嵌入的明确可控性结合起来,并以一种通过合成分析的方式重建姿势和辐射场。一旦经过训练,辐射场就可用于新的视点合成以及运动重定向。在Human3.6M数据集[IPOS14]上,他们展示了使用无表面学习模型的好处,该模型在光度重建损失的帮助下提高了单眼视频中人类姿势估计的准确性。虽然A-NeRF是在单眼视频上训练的,但Animatable Neural Radiance Fields(ANRF)[PDW21]是一种骨架驱动的方法,用于从多视角视频中重建人类模型。它的核心部分是一个新的运动表征,即神经混合权重场,它与三维人体骨架相结合,用于生成变形场。与几个一般的非刚性NeRFs[PSB21, TTG21]类似,ANRF保持一个典型的空间,并估计多视角输入和典型框架之间的双向对应关系。重建的可动画化的人体模型可用于自由视角的渲染和新姿势下的重新渲染。通过在离散的典型空间点的体积密度上运行行进方程,也可以从ANRF中提取人的网格。该方法对学习到的人体模型达到了很高的视觉精度,作者建议在未来的工作中可以改进对观察到的表面上复杂的非刚性变形的处理(例如那些由于宽松的衣服引起的变形)。
Peng及其同事[PZX21]的Neural Body方法能够从稀疏的多视图视频(例如,只有四个同步视图)中对人类表演进行新颖的视图合成,见图10的示例性输入和结果。他们的方法使用参数化的人类形状模型SMPL[LMR15]作为形状代理先验。它假定在不同的帧上恢复的神经表征具有相同的锚定在可变形网格上的潜在代码集。通用基线,如刚性NeRF[MST20](按时间戳应用)或NeuralVolumes[LSS19],假定输入图像集更密集,因此,在从少数同步输入图像中渲染移动人类的新视角的能力方面,无法与Neural Body竞争。该方法与PIFuHD[SSSJ20]等人体网状结构重建技术相比也很有优势,后者在精细外观细节(如很少穿戴或独特的服装)的三维重建方面强烈依赖于训练三维数据。与神经身体方法类似,神经演员(NA)[LHR21]使用SMPL模型来表示变形状态。他们利用代理来明确地将周围的三维空间解压缩成一个典型的姿势,其中嵌入了NeRF。为了提高几何和外观的高保真细节的恢复,他们使用了定义在SMPL表面的额外的二维纹理图,这些纹理图被用作NeRF MLP的额外条件。H-NeRF[XAS21]是另一种使用人体模型进行调节的人类时空三维重建的技术。与Neural Body[PZX21]类似,它们需要一组来自同步和校准的相机的稀疏视频。与之相反,H-NeRF使用了一个带有签名距离场的结构化隐性身体模型[AXS21],这使得具有挑战性的主体的渲染更加清晰,几何形状更加完整。
体积基元的混合[LSS21]是一个用于实时渲染动态、可动画的虚拟人的模型。其主要思想是用一组可以动态改变位置和内容的体积基元对场景或物体进行建模。这些基元对场景的组成部分进行建模,就像一个基于部件的模型。每个体积基元都是由一个解码器网络从潜伏代码中产生的体素网格。代码定义了场景的配置(例如,在人脸的情况下,面部表情),解码器网络使用它来产生基元位置和体素值(包含RGB颜色和不透明度)。渲染时,采用光线行进程序,沿每个像素对应的光线累积颜色和不透明度值。与其他动态NeRF方法类似,多视角视频被用来作为训练数据。该方法能够创造出极高质量的实时渲染,即使在具有挑战性的材料上,如头发和衣服,看起来也很真实。
4.4. 组合与编辑
| Method | Required Data |
3D Representation |
Controllable Parameters |
Generative Model |
Code |
|---|---|---|---|---|---|
| Nguyen-Phuoc et al. [NPLT19] | MVI+UIC | V | P,S,T | ✓ | Link |
| Liu et al. [LZZ21] | MVI | V | S,C | ✗ | Link |
| Jang and Agapito [JA21] | UIC | V | P,S,T | ✗ | Link |
| Ost et al. [OMT21] | VID | V-O | P,S,T,O | ✓ | Link |
| Zhang et al. [JXX21] | MV-VID | V-O | S,C | ✓ | Link |
| Niemeyer and Geiger [NG21b] | UIC | NFF | P,S,T | ✓ | Link |
表4:第4.4节中介绍的编辑和场景构成的部分方法。VID:单眼视频,MV-VID:同步的多视角视频,MVI:多视图图像集,UIC:非结构化的二维图像集。V:神经体积,V-O:每个物体+背景的神经容积,NFF:神经特征场。P:相机姿势,S:形状,T:纹理/外观,O:不透明度,C:颜色。
迄今为止所讨论的方法允许重建静态或动态场景的体积表征,并渲染它们的新视图,也许是来自几张输入图像。除了比较直接的修改(例如,去除前景),它们保持观察到的场景不变。最近的一些方法还允许编辑重建的三维场景,即重新排列和仿生变换物体,改变它们的结构和外观。在表4中,我们对所讨论的方法进行了概述。
有条件的NeRF[LZZ21]可以改变在二维图像中观察到的刚性物体的颜色和形状,这些物体来自于用户的手动编辑(例如,有可能删除一些物体的部分)。这一功能是由一个在同一类别的多个物体实例上训练的NeRF实现的。在编辑过程中,网络参数被调整以匹配新观察到的实例的形状和颜色。这项工作的贡献之一是找到了一个可调整参数的子集,它可以成功地传播用户的编辑,以生成新的视图。这就避免了对整个网络进行昂贵的修改。CodeNeRF[JA21]表示整个物体类别的形状和纹理变化。与pixelNeRF类似,CodeNeRF可以合成未见过的物体的新视图。它为形状和纹理学习了两种不同的嵌入。在测试时,它从一张图像中估计出物体的相机姿态、三维形状和纹理,并且两者都可以通过改变它们的潜伏代码而不断修改。CodeNeRF实现了与以前的单图像三维重建方法相当的性能,同时不假设已知的相机姿势。

神经场景图(NSG)[OMT21]是一种最新的方法,用于从驾驶时记录的单眼视频(自我车辆视图)进行新的视图合成。这种技术将具有多个独立的刚性移动物体的动态场景分解为一个学习的场景图,该图对单个物体的变换和辐射进行编码。因此,每个物体和背景是由不同的神经网络编码的。此外,为了提高效率,静态节点的采样被限制在分层平面上(与图像平面平行),即2.5D表示。NSG需要在输入帧集合上对每个感兴趣的刚性移动物体进行注释跟踪数据,每个物体类别(如汽车或公共汽车)共享一个体积先验。然后,神经场景图可以用来渲染相同(即观察到的)或编辑(即通过重新安排物体)场景的新观点。NSG的应用包括背景-前景分解,丰富汽车感知的训练数据集,以及改进物体检测和场景理解(见图11)。
Zhang等人[JXX21]介绍了另一种用于可编辑的自由视点视频的分层表示。他们的空间和时间一致的NeRF(ST-NeRF)依赖于所有独立移动和衔接的物体的边界框,从而产生了多个层次,并将它们的位置、变形和外观拆分开来。ST-NeRF的输入是一组16个同步视频,这些视频来自以固定间隔放置在一个半圆上的摄像机,以及人类背景的分割面具。该方法的名称表明,时空一致性约束反映在其结构中,即作为一个时空变形模块和一个典型空间的NeRF模块。ST-NeRF也接受时间戳以说明外观在时间上的演变。在渲染新的视图时,采样光线通过多个场景层投射,这导致了密度和颜色的累积。ST-NeRF可用于神经场景的编辑,如重新缩放、移位、复制或删除表演者,以及时间上的重新安排。作为未来工作的有希望的方向,作者提到了减少输入视图的数量和实现非刚性的场景编辑。
请注意,第4.2节中讨论的一些方法[NG21b, NPLT19]也可以用于场景编辑。例如,GIFARRE可以旋转在单个单眼图像中观察到的已知类别的物体,改变其外观并沿深度通道进行平移。本节讨论的方法的比较见表4。
4.5. 重新打光和材料编辑
| Method | Required Data | 3D Representation | Controllable Parameters | Models Light Visibility | Models Indirect Illumination | Code |
|---|---|---|---|---|---|---|
| Bi et al. [BXS20] | I+L | V | L+M | ✓ | ✗ | ✗ |
| Zhang et al. [ZLW21] | I+M | S | L+M | ✗ | ✗ | Link |
| Boss et al. [BBJ21] | I+M | V | L+M | ✗ | ✗ | Link |
| Srinivasan et al. [SDZ21] | I+L | V | L+M | ✓ | ✓ | ✗ |
| Zhang et al. [ZSD21] | I | V | L+M | ✓ | ✗ | Link |
| Xiang et al. [XXH21] | I+M | V | T | N/A | N/A | ✗ |
表5:第4.5节中提出的重光照的选定的方法。I:图像,L:输入图像的照明参数,M:物体掩码。V:神经体积,S:神经SDF。L:照明,M:材料,T:纹理图。
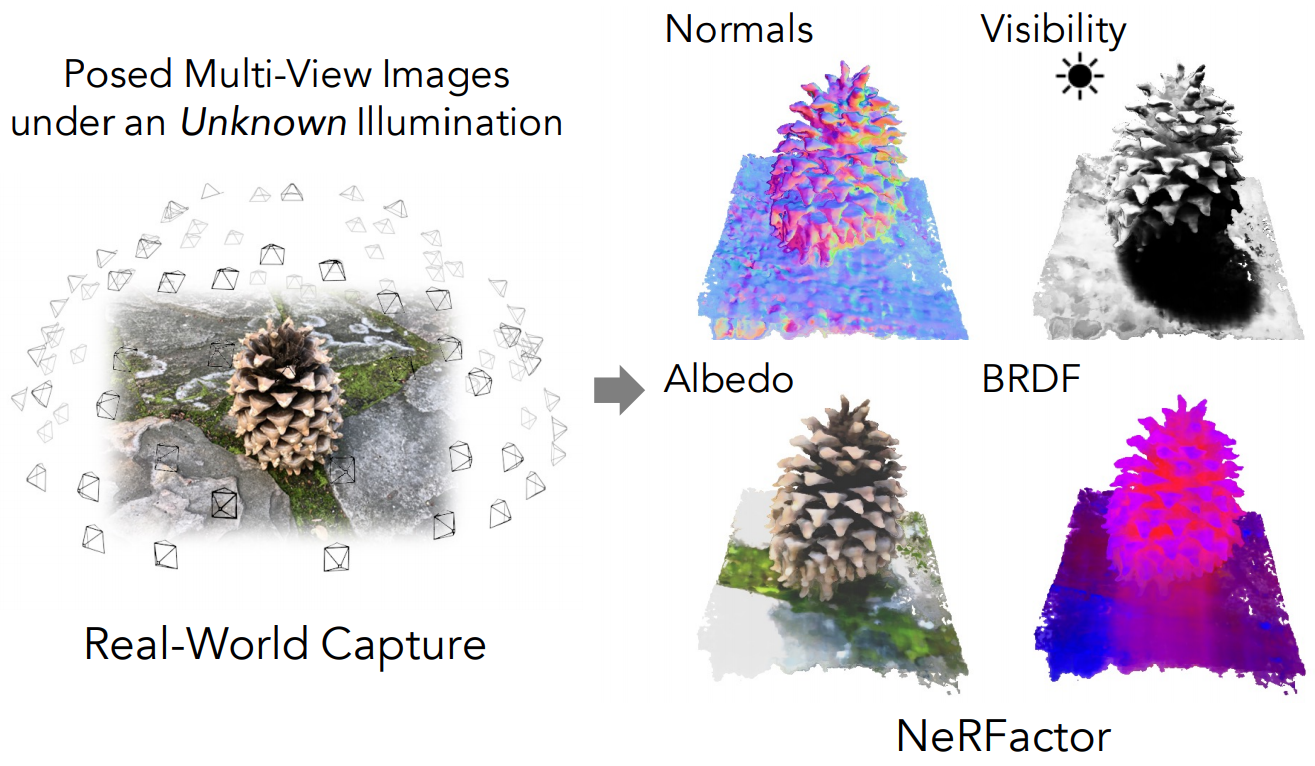
图12:NeRFactor[ZSD21]将在未知光照下拍摄的场景分解为表面法线、反照率、BRDF和阴影的三维神经场。这使得自由视点的重新照明和材料编辑成为可能。图片改编自[ZSD21]。
到目前为止,我们所介绍的应用都是基于第3.2.2节所讨论的简化的吸收-发射体积渲染模型,其中场景被建模为阻挡和发射光线的粒子体积。虽然这个模型足以从新的视角渲染场景的图像,但它无法渲染不同照明条件下的场景图像。启用重新照明需要一个能够模拟光线在体积中的传输的场景表示法,包括具有不同材料特性的粒子对光线的散射。在表5中,我们对所讨论的方法进行了概述。
神经反射场[BXS20]提出了NeRF的第一个扩展,以实现再照明。在NeRF中,神经反射场不是将场景表示为一个体积密度和与视图相关的发射辐射的场,而是将场景表示为一个体积密度、表面法线和双向反射分布函数(BRDFs)的场。这允许在任意的照明条件下渲染场景,使用预测的表面法线和每个三维位置的BRDFs来评估该位置的粒子向摄像机反射了多少入射光。然而,对于神经体积渲染模型来说,评估从沿摄像机光线的每一点到每一个光源的可见度是非常密集的计算。即使只考虑直接光照,MLP也必须在沿摄像机光线的每一点和每个光源之间的密集采样位置进行评估,以便计算出渲染该光线的入射光。神经反射场避开了这个问题,它只用与相机同处一地的单点光照亮的物体图像进行训练,因此MLP只需要沿着相机光线进行评估。
最近其他恢复可重燃模型的工作,通过简单地忽略自包含物并假设任何表面上方半球的所有光源都是完全可见的,从而避免了计算光源可见性的困难。PhySG[ZLW21]和NeRD[BBJ21]都假设光源完全可见,并通过将环境照明和场景BRDFs表示为球面高斯的混合物来进一步加速渲染,这使得入射光线乘以BRDF的半球积分可以以封闭形式计算。假设光源完全可见,对于大部分是凸面的物体来说效果很好,但这种策略无法模拟诸如投射阴影的效果,这些阴影是由于光源被场景的几何形状遮挡而造成的。
神经反射和可见度场[SDZ21](NeRV)训练一个MLP,以近似计算任何输入3D位置和2D入射光线方向的光源可见度。与沿每条光线密集采样的点查询MLP不同,可见度MLP只需要对每个入射光线方向进行一次查询。这使得NeRV能够从具有明显阴影和自闭效应的图像中恢复可重照的场景模型。
NeRFactor[ZSD21]没有像之前讨论的方法那样从头开始优化可重现的表示,而是从一个预先训练好的NeRF模型开始。然后,NeRFactor通过将预训练的NeRF的体积几何简化为一个表面模型,优化MLP来表示光源的可见性和表面任何一点的法线,最后优化环境照明和任何表面点的BRDF的表示,来恢复一个可重现的模型;见图12的分解示例。这导致了一个可再照明的模型,在渲染图像时更有效率,因为体积几何已经被简化为一个单一的表面,任何一点的光源可见度都可以通过一个MLP查询来计算。
上述的可重现模型将场景材料表示为连续的三维BRDFs场。这使得一些基本的材料编辑成为可能,因为恢复的BRDFs可以在渲染前被改变。NeuTex[XXH21]通过引入一个表面参数化网络,学习从体积中的3D坐标到2D纹理坐标的映射,实现了更直观的材料编辑。在恢复了场景的NeuTex模型后,可以很容易地编辑或替换2D纹理。
4.6. 光场
体积渲染、球体追踪和其他三维渲染前向模型可以产生照片般真实的结果。然而,对于一个给定的光线,它们都需要在该光线第一次与场景的几何形状相交的任何三维坐标上对底层三维场景表示进行采样。由于这个相交点并不是事先就知道的,所以射线行进算法首先必须发现这个表面点。最终,这产生了一个时间和内存的复杂性,它随着场景的几何复杂性的增加而增加,越来越多的点必须被采样以渲染越来越复杂的场景。在实践中,每条射线有数百甚至数千个点。此外,准确地渲染反射和二阶光照效果需要多反弹光线追踪,这样,对于每个像素,必须追踪许多光线,而不是只有一条。这就产生了一个很高的计算负担。虽然在重建单一场景(过拟合)的制度中,这可以通过智能数据结构、散列和专家的低级工程来规避,但在重建三维场景的制度中,如果仅有少数观测值,甚至仅有一张图像,这种数据结构会阻碍学习型重建算法的应用,例如使用卷积神经网络从单一图像推断出三维场景的参数。
一对同时进行的工作[SRF21, LLYX21]因此引入了通过基于坐标的网络来解析光场的想法。具体来说,光场网络[SRF21]不是通过其三维辐射度场来参数化三维场景,而是通过其360度的光场,即一个将每条定向光线直接映射到该光线观察到的颜色的函数。同时,Liu等人[LLYX21]提出将用于前向场景的新型视图合成的前向平行光场参数化为一个神经场。通过光场来表示一个场景,就不需要进行光线行进,因为要渲染一个像素,光场可以被相应的摄像机光线所采样,并直接得到像素的颜色。它进一步消除了对多反弹光线追踪的需要,因为反射也同样被光场吸收了。反过来说,这就失去了多视图一致性的保证:三维渲染器保证将单一的三维坐标映射为单一的值,而神经光场可能将击中场景中同一点的两条光线映射为两种不同的颜色。这必须通过额外的手段来解决。
Sitzmann等人[SRF 21]提出通过对潜伏代码的神经光场进行调节来实现跨场景的泛化,从而学习一个多视图一致的光场空间,但是由于他们使用了全局调节,因此受限于简单场景。Sajjadi等人[SMP 21]沿用了基于先验的推理方法,并使用一个变换器对场景的360度光场进行参数化,这些光场是从少数图像观测中推断出来的,为复杂的真实世界场景实现了新的视图合成。Attal等人[AHZ21]、Ost等人[OLN21]、Liu等人[LLYX21]和Suhail等人[SESM21]则研究了与NeRF相同的范式,即单个三维场景的重建和新颖视图合成。为了确保多视图的一致性,Suhail等人[SESM21]利用了PixelNeRF[YYTK21]中的像素对齐的CNN特征,用于沿射线的3D点,这些点用变换器进行累积。这比NeRF有了明显的改进,但仍然需要在三维中取样,而且速度要慢几倍。Ost等人[OLN21]依靠点云形式的三维场景的粗略的三维重建来确定点状光场的参数。Attal等人[AHZ21]依靠在体素网格中存储特征,其中每个特征对与该体素相交的光线的局部光场进行参数化,并通过体积渲染进行渲染。Liu等人[LLYX21]利用正则化来确保多视图的一致性。
4.7. 工程框架
对于从业者来说,使用神经渲染模型的工作带来了工程上的挑战:大量的图像和视频数据必须以高度非连续的方式进行处理,而且这些模型往往需要对大型复杂的计算图进行区分。在本节中,我们将讨论有助于克服这些问题的工具的最新进展。
4.7.1.存储
用数据来饱和GPU,特别是用于神经渲染的数据是具有挑战性的:通常,图像或视频的每个像素都被当作一个单独的数据点。方法需要在数据集中的整个像素池上进行随机迭代,在时间重建的情况下,往往是在单个批次的整个序列上进行。灵活的存储解决方案应该考虑到这一点。
英伟达AIStore[AMB19]是一个通用的存储解决方案,它允许监测每个驱动器的吞吐量,并为加载和洗牌实现分层架构,同时将这些层级从用户那里抽象出来。独立于存储后端,分片具有巨大的优势,因为1)允许在内存中洗数据,同时2)在分片中主要使用顺序读取。Tensorflow[AAB15]通过tfrecord文件格式内置支持分片存储,而webdataset为PyTorch[PGM19]提供了类似的便利功能。
4.7.2. 超参数搜索和实验
由于运行时间长,配置层次复杂,神经渲染实验需要良好的实验管理和超参数搜索技术。Hydra [Yad19]擅长配置最复杂的实验,并为超参数搜索提供综合支持,例如使用AX自适应实验框架。然而,运行所有的实验进行扫描直到收敛,即使是使用贝叶斯超参数搜索巧妙地挑选参数,也可能太耗时了。Ray tune [LLN18]有ASHA [LJR20]和Hyperband [LJRT18]等算法的实现,这些算法可以动态地将计算和时间预算分配给实验,以加快超参数搜索。
4.7.3. 微分渲染和自动求导
神经渲染对可导性有很高的要求:需要建立复杂的计算图,并且根据应用,要么对大量的输入矢量执行(宏观AD–简洁地说,我们在本节中将自动区分称为AD),要么对大量的小输入执行(微观AD)。根据不同的应用,AD包可能需要在低级别的(如CUDA)或高级别的(如Python)中使用。一个强大的C++的AD库是STAN [CHB15]。我们参考所附的论文,以了解在其2015年出版之前对AD库的全面概述和评估,这超出了本文的范围。一个值得注意的较新的C++17的AD包是autodiff 包。Enzyme AD[MC]正在采取一种特别通用的低级AD方法:它利用了整个LLVM生态系统。这特别强大,因为有前台、LLVM IR和后台的概念。概括地说,LLVM前台将一种语言,例如C++,翻译成LLVM中间表示法(IR)。这种表示法是一种抽象的、与语言无关的低级命令表示法,它对所有前台都是一样的。这就是Enzyme的作用:它是一个扩展,可以在这个IR中创建函数的衍生物。这意味着它适用于LLVM支持的所有语言。LLVM后端从IR发出代码:这可能是X86、ARM或GPU处理器。这意味着,Enzyme支持各种处理器,包括GPU。另一个专门用于处理图像和图形的C++包是Halide [LGA18]。它最突出的特点是对像素的并行处理进行灵活的调度。
Difftaichi [HAL20]为物理模拟提供了Python中的可微分编程,并应用于渲染。Enoki[Jak19]是一个非常通用的高性能AD组件,用于基于物理的可微分渲染,是Mitsuba 2渲染器的核心组件[NDVZJ19]。Jax [BFH18]是一个用于可微分和加速线性代数的Python框架,具有针对GPU和TPU的编译选项。JaxNeRF是一个使用Jax的NeRF参考实现。Swift编程语言提供了AD作为第一类用例,并被大量用于开发Tensorflow集成。
4.7.4. 光线投射和渲染
目前有几个软件包可以提供高级别渲染和聚合基元。NVIDIA OptiX是一个用于光线投射和光线相交的高性能库,它提供了迄今为止在NVIDIA RTX硬件上使用硬件加速进行光线相交的唯一可能性。Teg [BMM21]是一种可微分编程语言,它提供了优化具有不连续积分的积分的基元,这在渲染中经常发现。Redner[LADL18b]是一个可微分光线追踪的框架;Mitsuba 2[NDVZJ19]为基于物理的可微分渲染和路径追踪提供了一个更通用的框架。psdr-cuda[LZBD21]通过使用更好的梯度计算技术和采样策略对Redner进行了改进。PyTorch3D [RRN20]围绕可微分渲染和图形提供了一套广泛的工具,与PyTorch紧密结合。Tensorflow Graphics [VKP19]对Tensorflow有类似的目标。
5. 开放挑战
在涵盖了可以成功应用神经体积表征的各种计算机图形和视觉问题之后,我们现在来看看那些只使用了经典表征的问题。因此,未来的研究有各种途径。我们进一步讨论该领域的多个开放性挑战。下面讨论的许多观点是相互关联的。
无缝集成和使用。半个多世纪以来开发的大多数计算机图形算法和技术都假定网格或点云是用于渲染和编辑的三维场景表示法。相比之下,神经渲染是一个非常年轻的领域,这个概念在几年前的2018年才被首次使用[ERB18]。因此,不可避免的是,在可以操作经典三维表征的可用方法谱系和适用于神经表征的方法谱系之间仍然存在差距。此外,有许多方法可以编辑经典表征,例如,广泛使用的工具,如Blender[Com18]和Maya[Aut]支持网格和纹理图,而它们的对应的神经表征必须从头开发。另一方面,可以预见的是,随着该领域的进一步改进以及神经表征越来越广泛的采用和整合,这一差距将会缩小。此外,现代硬件加速器是为经典的计算机图形设计的,将来也可以为神经表征进行类似的定制。
另一个相关的挑战是所学表征的可解释性,这涉及到一般的深度学习。因此,学习到的神经网络权重是出了名的难以用目标量(例如三维空间中的点颜色和不透明度)来解释。同时,他们的目标是取代图形管道,而图形管道是很好理解的,并依赖于分析得出的步骤。最终,为了提高可控性,并使学习到的体积模型与计算机图形工具无缝集成,我们希望能够修改场景参数化,使场景向所需方向变化。虽然这对于由全局MLPs参数化的任意场景来说可能是不可行的,但由局部神经表征组成的完整场景可能会使其具有可操作性,因为它开启了重新引入经典图形的有趣可能性。

图13:iMAP[SLOD21]获得的带有关键帧的房间的三维重建。iMAP是一个实时的SLAM系统,用于单个手持RGB-D相机,可以有效地填补被遮挡的区域。尽管迈出了成功的第一步,为大规模场景学习神经表征仍有许多开放的挑战。图片改编自[SLOD21]。
可扩展性。大多数关于体积神经渲染的工作都集中在单个物体和相对简单的复合场景(例如,一个人和一个背景,在同一环境中的几个人,有移动车辆的街道),或没有背景。学习大规模场景的神经表征–这些场景在每个输入帧中只能被部分观察到–仍然是一个挑战。尽管在这个方向上已经迈出了成功的、令人印象深刻的第一步(我们这里指的是Nerf in the Wild[MBRS21]和神经SLAM系统iMAP[SLOD21],见图13),但仍有许多开放的挑战。例如,为单个物体开发的场景编辑、重新打光和合成的方法不能直接扩展到处理大规模场景。此外,从某种场景大小开始,大规模环境的全局表示就变得不可行了,即使是在应用空间分割策略时,如PlenOctrees[YLT21]中使用的策略。因此,需要按照VoxelHashing[NZIS13]对TSDF的思路,为大规模场景的高效神经模型开发出新一代的存储和检索技术。首先,它们应该使场景的完成更加有效(即不需要不断地从头开始重新计算整个模型),其次,能够方便地检索部分内容。这两点都与上面讨论的可解释性的公开挑战有关。
可推广性。目前只有少数初步的但有希望的方法用于可通用的和可实例化的体积神经表征。例如,StereoNeRF[CBLPM21]仅使用十几个分散的视图来生成刚性场景的新视图,其视觉精度在微调后可与原始NeRF[MST20]相媲美,而pixelNeRF[YYTK21]仅从一张图像就能推断出训练时未见过的刚性场景的体积计量模型。这类方法是数据驱动的,需要有足够宽的基线的大规模多视图数据集。因此,如果数据集提供足够的视点覆盖,这些方法可以在任意的新视点上产生视图。减少这种强烈的依赖性是未来工作的一个令人兴奋的方向。另一个开放的挑战是可实例化的方法对非刚性变形的场景的可推广性。输入可以是稀疏的时空观测数据集,甚至是极端的单幅图像(在这种情况下,任务变成了从单幅图像出发的场景动画)。这种技术的一个直接方向是依靠可变形场景的多视图数据集,这可能会使所需的数据集大小增加很多。另一个可能的方法是将变形模式和场景的形状以及静止时的外观分开。此外,虽然有一些关于生成神经场景表征的工作(例如,使用超网络[SRF21]),但在设计将神经场景表征作为输入以对其进行处理的神经算子方面进展较少,例如,完成一个部分场景或为现有表征回归语义标签。目前还没有类似于网格的网格卷积或体素网格的三维卷积的算子。这样的算子最好只训练一次,然后就能普遍适用。 多模式学习。多模式学习意味着超越视觉信号,并纳入其他数据类型,如语义、文本描述和声音。例如,远程呈现和增强现实将高度受益于一种方法,该方法不仅可以呈现动态互动和交谈的人类的新观点,还可以合成相应的新声音;例如,现有的工作可以从单声道音频输入合成立体声[RMG21]。合成文本描述和场景的语义(例如,语义分割标签)对基于体积神经表征的下游应用非常有用。虽然之前的一些工作解决了这个目标[KSW20, ZLLD21],但这仍然是一个开放的挑战。更加详细和针对具体场景的建模可以考虑诸如相机捕获系统(例如,如TöRF[ALG21]中已经显示的深度相机)、相机是否使用滚动或全局快门,或者输入图像中是否存在运动模糊等信息。其他传感器,如IMU、激光雷达或事件流,都有可能以一种连续的方式建模。(超声波和X射线可以以任意的分辨率连续建模,用于医学成像)。还可以想象,对某些不容易测量的捕捉属性进行优化,如多视角捕捉设置的颜色校准。这也延伸到了一般的物理模拟,神经场景表示提供了一个令人兴奋的场所,通过纳入可微分的物理模拟器来 “少学多知”;例如,对于物理上的变形模型或物理上正确的光传输。
其他问题。我们能提高质量吗?重建具有许多高频细节、阴影和取决于视图的外观的物体仍然是一个基本未解决的问题。我们能减少训练时间吗?尽管在测试时对新的视图合成的非常快速的推理方面已经取得了进展,但改善训练时间仍然是一个很大的挑战。较少的输入图像是否足够?较少的输入视图可能足以达到与需要数百个视图的完全收敛模型类似的视觉保真度。目前,部分观察(例如,只在图像子集中观察到的场景的一部分)往往比场景的其他部分更模糊。
除了AR/VR的直接用例之外,在机器人等其他背景下使用神经场景表征的研究很少,但实时SLAM系统iMAP[SLOD21]是个明显的例外(见图13)。我们怎样才能获得、纳入和预测物体的承受力或其他注释,如温度?使用神经场景表征进行运动预测或规划是否有优势?
本节讨论的未来方向清单并不以完整为目的。我们期望在不久的将来看到基于坐标的神经体积表征的更多方面的改进。
6. 社会影响
在这份SOTA中讨论的神经方法对合成的新观点实现了非常高的真实性。该领域的快速发展已经影响并将继续以许多积极和潜在的消极方式影响社会,我们在本节中讨论。
研究和工业。受到新的体积神经表征明显影响的领域是计算机视觉、计算机图形学以及增强和虚拟现实,它们可以从渲染环境的照片真实性的提高中受益。事实上,最先进的体积计量模型依赖于被充分理解和优雅的原理,这降低了摄影测量和三维重建研究的准入门槛。此外,这些方法的易用性和公开可用的代码库和数据集也放大了这种效果。由于神经渲染仍未成熟和被充分理解,像Blender这样的终端用户工具还不存在,这使得这些新颖的方法目前对3D爱好者和工业界来说都遥不可及。然而,对该技术更广泛的理解不可避免地影响到开发的产品和应用。因此,我们可以预见,在游戏内容创作和电影特效方面的努力将会减少。与现有技术相比,用几张输入图像渲染照片般逼真的场景的可能性是一个显著的优势。这有可能重塑视觉效果(VFX)行业中使用的整个既定的内容设计管道。
可信度。然而,与此同时,照片的真实性创造了滥用技术的可能性,并创造了恶意行为者可能虚假地声称是真实的合成内容,特别是当神经渲染方法专注于人脸时[TZS16, TZN19, GTZN21]。为了应对这些潜在的滥用,研究界正在开发自动检测这种虚假内容的方法[CRT21, RCV19],并且正在探索包括加密和区块链措施的安全措施。而且还有其他一些可以探索的缓解措施,以尽量减少这些风险。例如,虽然在有些情况下,我们希望用户不反对看到合成的真实照片内容(如看电影时),但合成内容可以被贴上标签或以其他方式确定为合成内容,以告知用户。进一步的用户研究可以调查人们在不同情况下对合成内容进行标记的必要性的判断。在收集方面,人们可以提供明确和知情的同意,他们的身份可以被用来在特定的环境中创建合成内容。
环境。由于目前的神经体积场景表征是基于深度学习的,用于训练它们的GPU会消耗相当多的能量。由于越来越多的实验室在研究神经渲染,高端和多GPU系统的使用相应增加。如果制造资源和操作GPU集群的电力不是主要来自可再生资源,那么从长远来看,训练体积神经表示法会对环境和全球气候产生负面影响。为了软化对计算资源的需求,进而软化对电力和硬件的需求,有许多架构在训练时需要的计算能力比基于NeRF的方法更少。最后但并非最不重要的是,对GPU的高需求可能意味着并非所有的小组都能在平等的基础上做出贡献,因为实验体积表征并不是最轻便的任务。
7. 结论
在这份SOTA中,我们回顾了神经渲染技术的最新趋势。所涉及的方法是基于二维观察作为训练输入来学习三维神经场景表征,并能够通过控制不同的场景参数来合成照片般真实的图像。在过去几年中,神经渲染领域取得了快速进展,并继续快速增长。其应用范围包括从刚性和非刚性场景的自由视角视频到形状和材料编辑、重新照明和人类化身生成等。这些应用已在本报告中进行了详细讨论。
同时,我们认为,神经渲染仍然是一个新兴的领域,有许多开放的挑战可以解决。为此,我们确定并讨论了未来研究的多个方向。此外,我们还讨论了社会影响,这些影响来自于神经渲染的民主化,以及它合成照片般真实的图像内容的能力。总的来说,我们的结论是,神经渲染是一个令人兴奋的领域,它激励着许多社区的数千名研究人员去解决计算机图形学的一些最困难的问题,我们期待着看到该主题的进一步发展。