
本文为英伟达2022GTC大会上的黄仁勋主题演讲主要内容翻译和整理。
原视频链接: [Youtube] [Bilibili 双语字幕]
文章链接:
[TOC]
Opening
如今,医生只需要几个小时就可以完成人类 DNA 的测序工作并根据氨基酸序列预测 DNA 的三维结构;研究人员可以使用计算机来生成新的候选药物并且通过计算机,完成新药物对目标疾病的疗效测试;AI 正在学习生物学和化学,正如 AI 已经学习了理解图像、声音和语言。在 AI 进入计算机领域后,药物研发领域也将迎来一场新的革命,正如我们在其他受 AI 影响的领域所见证的一样。这些功能在十年前是遥不可及的数据中心规模的加速计算与机器学习相结合,可以将计算速度提高百万倍。加速计算已经使像 Transformer 这样的革命性 AI 模型和自监督学习成为可能。
AI 已从根本上改变了软件的能力以及开发软件的方式。各公司都在处理和完善自己的数据、开发 AI 软件并使自己成为智能的生产商,他们的数据中心正在逐步演变为 AI 工厂。
第一波 AI 学习的是感知和推理,例如图像识别、语音理解、推荐视频或者商品。下一波 AI 的发展方向是机器人,也就是使用 AI 规划行动。数字机器人、虚拟形象和实体机器人将完成感知、规划并采取行动。
如同 TensorFlow 和 PyTorch 等 AI 框架已经成为 AI 软件中不可或缺的一部分,Omniverse 也将成为制作机器人软件时必不可少的工具。Omniverse 将掀起一波新的 AI 浪潮。在本届 GTC 大会上,我们将探讨下一个百万倍加速,以及其他塑造我们所在行业的动态。在过去十年中,NVIDIA 加速计算在 AI 领域中实现了百万倍的加速,并引发了现代 AI 革命。
如今,AI 将会为所有行业带来翻天覆地的变化,这些 CUDA 库和 NVIDIA SDK 是加速计算的核心。伴随着每一个新的 SDK,新的科学领域、新的应用和行业都可以利用到 NVIDIA 强大的计算能力。这些 SDK 解决了计算、算法和科学交叉领域中极其复杂的问题。NVIDIA 的全栈方法产生的复合效应,实现了百万倍的加速 如今,NVIDIA 帮助数百万开发者以及数以万计的成熟公司和初创企业实现了飞速发展,GTC 大会是你们所有人的盛会。当看到领先的计算机科学家、AI 研究人员、机器人专家和自动驾驶汽车设计师在 GTC 上展示他们的成果时,我们总会倍受鼓舞。从新加入的与会者和演讲中,我们可以看到 AI 和加速计算的覆盖范围和影响正在不断扩大。
今年,我们看到了百思买、家得宝、沃尔玛、克罗格和劳氏公司如何使用 AI 来进行工作;LinkedIn、Snap、Salesforce、DoorDash、Pinterest、ServiceNow、美国运通和Visa将分享大规模使用 AI 的经验;在这里你同样能够看到医疗健康公司葛兰素史克、阿斯利康、默克、百时美施贵宝,梅奥医院、麦克森和礼来的演讲。2022 年 GTC 大会将会非常精彩。
GPU 使 AI 发生了革命性的转变。现在,基于 GPU 的 AI 正在革新各个行业和科学领域,其中对人类最有影响力之一的便是气候科学。科学家们预测,要想有效地模拟区域气候变化需要一台比现在大十亿倍的超级计算机。但我们现在就必须对工业决策的影响以及减缓和适应策略的有效性作出预测。NVIDIA 将使用我们的首台 AI 数字孪生超级计算机 Earth-2 来应对这一巨大挑战。通过发明新的 AI 和计算技术,来让我们获得十亿倍的算力支持,并及时采取行动,早期的证据表明我们能够成功。来自 NVIDIA、加州理工学院、伯克利实验室、普渡大学、密歇根大学和莱斯大学的研究人员开发了一个名为 FourCastNet 的天气预报 AI 模型。FourCastNet 是一种基于物理信息的深度学习模型,可以预测飓风、大气河以及极端降水等天气事件。FourCastNet 以欧洲中期天气预报中心 (ECMWF) 长达 40 年的模拟增强型真值数据为基础学会了如何预测天气。深度学习模型首次在降水预测方面达到了比先进的数值模型更高的准确率和技能并使预测速度提高了 4 到 5 个数量级。也就是说传统的数值模拟需要一年的时间,而现在只需要几分钟。
视频介绍
大气河是天空中巨大的水汽河流,每条河流的水量都比亚马逊河的还要多。它们一方面为美国西部提供了关键的降水来源,但另一方面,这些巨大的强风暴也会导致灾难性的洪灾和暴雪。NVIDIA 创建了 Physics-ML 模型,该模型可以模拟全球天气模式的动态变化,以超乎想象的速度和准确性预测大气河等极端天气事件。此 GPU 加速的 AI 数字孪生模型名为 FourCastNet,由傅里叶神经算子提供动力支持,基于 10 TB 的地球系统数据进行训练。依托这些数据,以及 NVIDIA Modulus 和 Omniverse,我们能够提前一周预测灾难性大气河的精确路线。在一个 NVIDIA GPU 的助力下,FourCastNet 只需几分之一秒即可完成预测
凭借如此快的速度,我们可以生成数千个模拟场景,探索所有可能的结果。与以往相比,我们能够更加自信地量化灾难性洪灾的风险。NVIDIA 是加速计算的先驱,这个领域需要全栈专业知识。
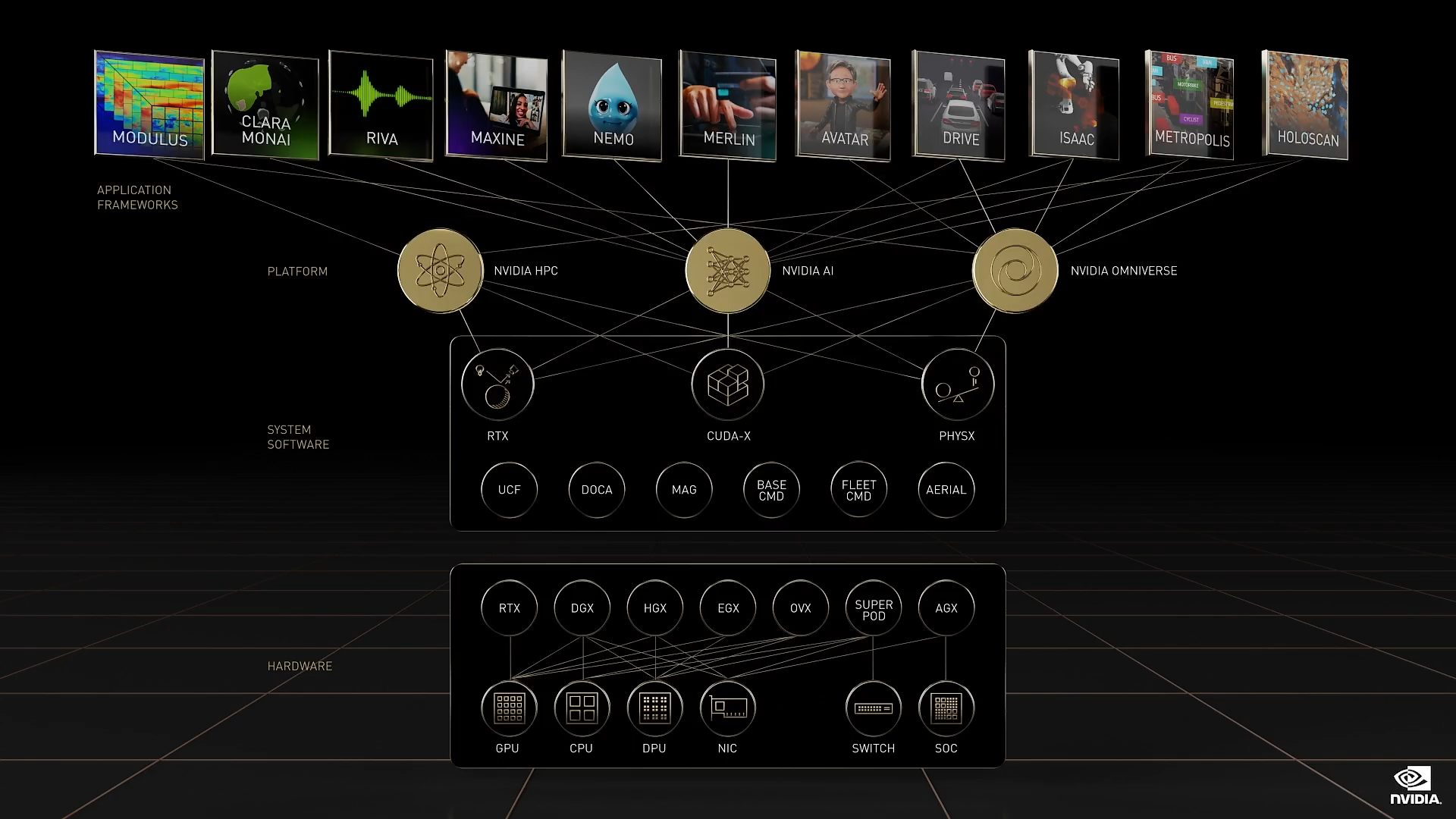
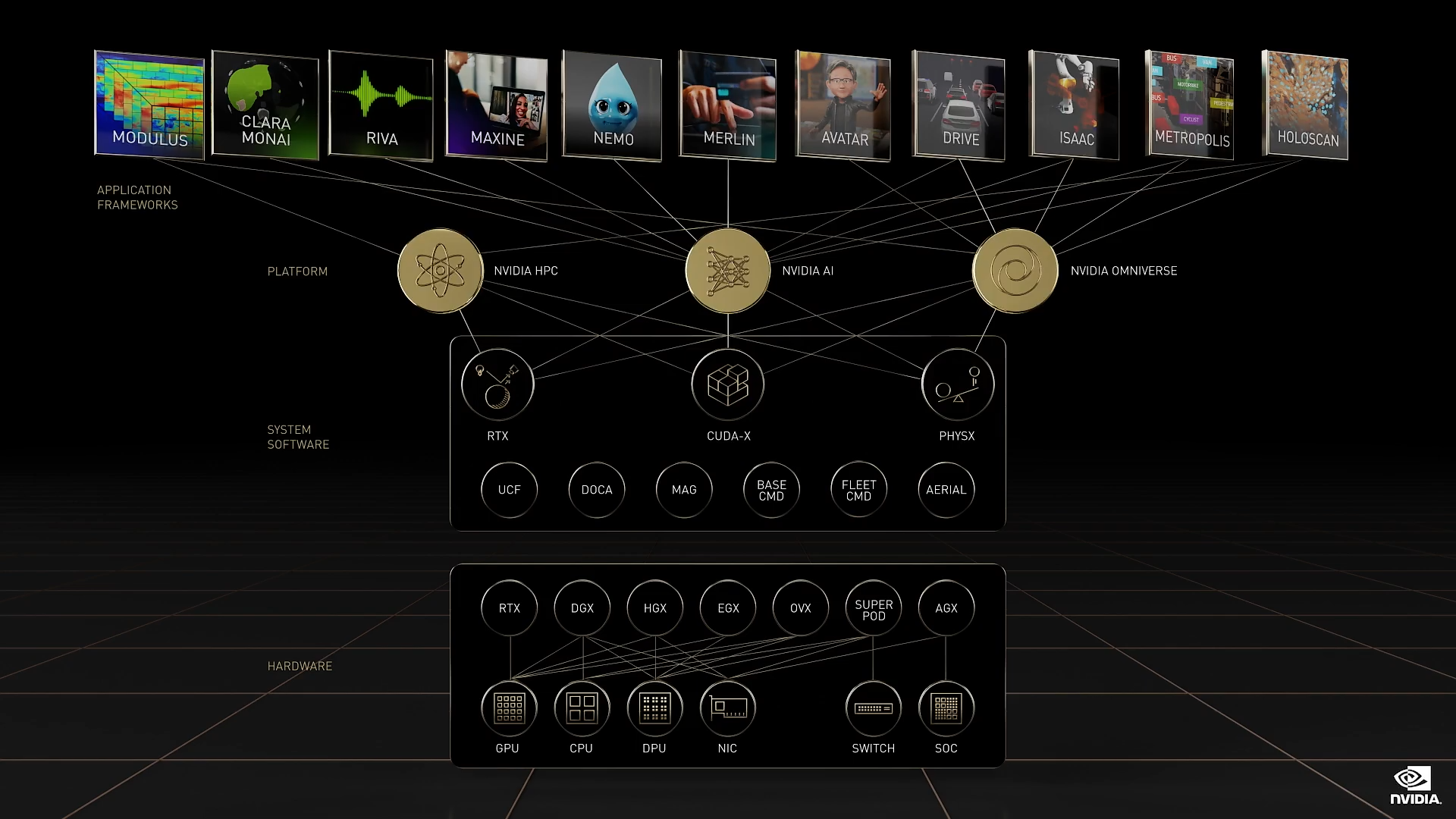
类似于一个计算堆栈或神经网络,我们从四个层级来构建 NVIDIA:硬件、系统软件、平台软件和应用。每一层都对计算机制造商、服务提供商和开发者开放,让他们以更适合的方式集成到其产品当中。今天,我将在每一层级都宣布对应的新产品,让我们开始吧。
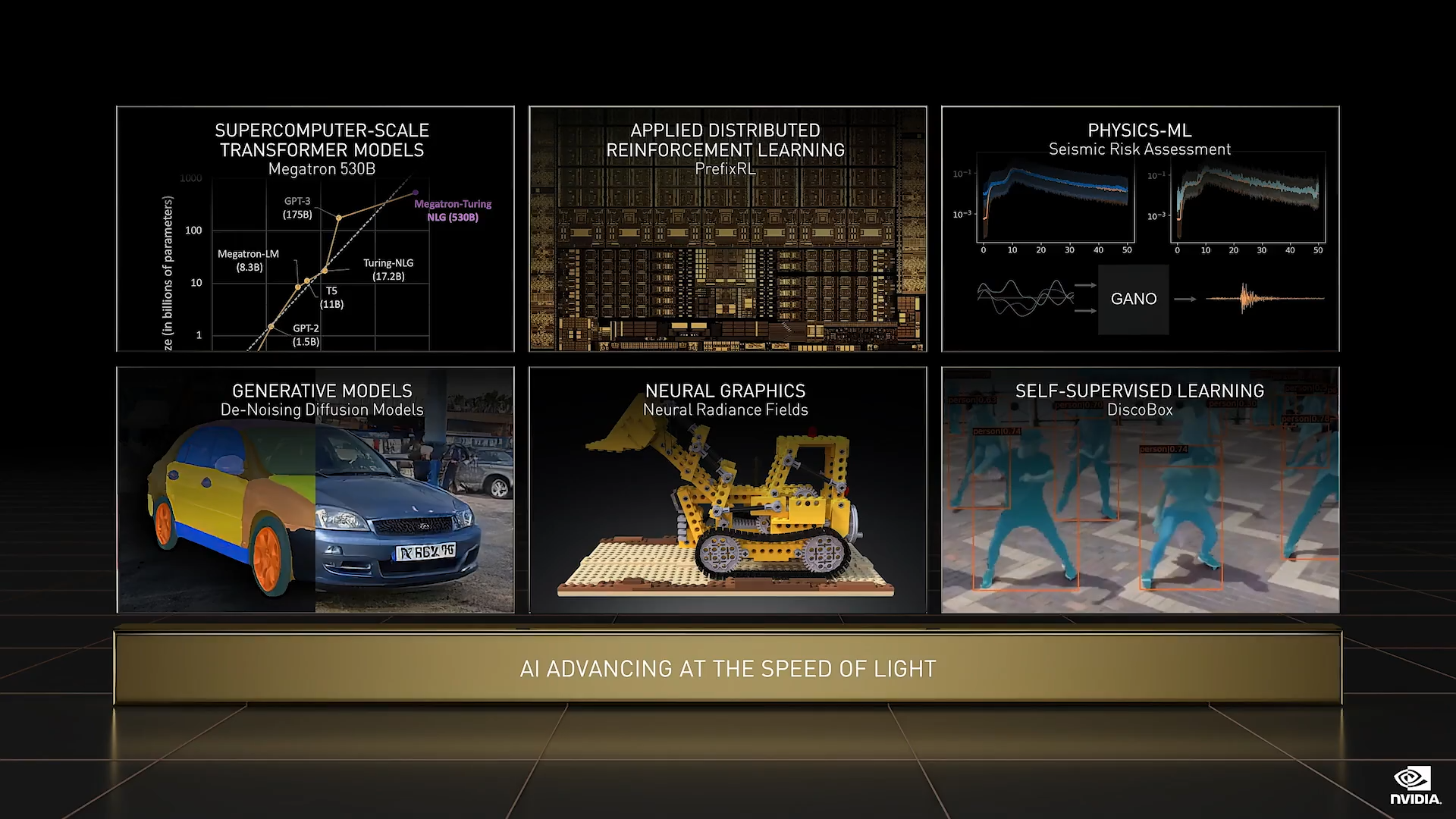
AI 的进步令人惊叹,Transformer 模型开启了自监督学习,并解除了人工标记数据的需求。因此我们可以使用庞大的训练集来训练 Transformer 模型学习更充分且可靠的特征。得益于 Transformer,模型和数据的规模皆已扩大增长,而模型技能和准确性也因此快速提升。用于语言理解的 Google BERT,用于药物研发的 NVIDIA MegaMolBart,以及 DeepMind 的 AlphaFold都是基于 Transformer 模型的突破性成果。
Transformer 让自监督学习成为可能,也令 AI 飞速发展。自然语言理解模型可以从大量的文本中学习,无需监督,然后通过少量的人工标记数据来进行细化以发展其在翻译、问答、摘要、写作等方面的优秀技能。具备语言监督的多模态学习已为计算机视觉开拓了新维度。像 NVIDIA NVCell 这样的强化学习模型正在执行芯片布局,其也就表示 AI 正在构建芯片
如同 FourCastNet 和 Orbnet,Physics-ML模型也正在学习物理学和量子物理学,这些是取得重大科学突破的首要条件;生成模型正在改变创意设计、帮助构建虚拟世界,并将革新通信方式;如同 NeRF,从 2D 图像中学习 3D 表征的神经图形网络,将扩大摄影应用场景,并帮助我们创造属于我们世界的数字孪生。

AI 正在各个方向加速发展,包括新的架构、新的学习策略、更大和更可靠的模型,新的科学、新的应用、新的行业,所有这些都在同时进行。
接下来我展示一个令人惊叹的示例,这个 AI 驱动的动画角色是基于物理规则的强化学习模型制作的,一起来看一下。
视频介绍
我们正在利用强化学习开发更加栩栩如生、反应灵敏的物理模拟角色。我们的角色通过模仿人类的动作数据,来学习执行逼真的动作例如行走、跑动和挥剑。我们的角色在模拟环境中经过了长达 10 年的强化训练。借助 NVIDIA GPU 驱动的大规模并行模拟器,这种训练在真实世界中只需花费 3 天即可完成。这些虚拟角色随后会学习执行各种运动技能。经过训练的虚拟角色可以利用这些技能来执行更复杂的任务。现在,一个训练过的虚拟角色正跑向目标对象并将其击倒。我们还可以引导它沿着不同的方向行走,就像您操控游戏角色那样。基于我们的模型,虚拟角色可以在新环境中自动生成自然而连贯的行为。我们还可以使用自然语言控制它。例如,我们可以指示角色进行盾击或者挥剑。我们希望这项技术最终能让基于虚拟角色的动画制作变得简单、流畅,就像和真实演员说话一样。
NVIDIA AI 是驱动这些创新的引擎,我们正在全力推动该平台的发展,解决新问题,使其得到更广泛的应用,让 AI 触手可及。NVIDIA AI 是一套涵盖整个 AI 工作流程的库,从数据处理和 ETL 特征工程,到图形、经典机器学习、深度学习模型训练及大规模推理。NVIDIA DALI、RAPIDS、cuDNN、Triton 和 Magnum IO 是其中最热门的库。我们使用这些库来创建专用 AI 框架,包括先进的预训练模型和数据管道,使其易于横向扩展。
我们先了解一下 GTC 大会的更新内容
AI Suite of Libraries
NVIDIA Triton
网上交互每天多达数千亿,例如搜索、购物和社交,产生了数万亿的机器学习模型推理。NVIDIA Triton 是一款开源的、超大规模的模型推理服务器,是 AI 部署的“中央车站”。Triton 支持在每一代 NVIDIA GPU、x86 和 Arm CPU 上部署模型,并具备支持 AWS Inferentia 等加速器的接口。Triton 支持各类模型:CNN、RNN、Transformer、GNN、决策树,还支持各类框架:TensorFlow、PyTorch、Python、ONNX、XGBoost。Triton 支持各类查询类型:实时、离线、批处理,或串流视频和音频。Triton 支持各类机器学习平台:AWS,Azure,Google,阿里巴巴,VMWare,Domino Data Lab,OctoML 等。Triton 可以在各个地方运行:云、本地、边缘或嵌入式设备。Amazon Shopping 正在使用 Triton 进行实时拼写检查。而微软正藉由 Triton 为翻译服务提供支持。Triton 已被 25000 位客户下载超过 100 万次。
NVIDIA Riva
NVIDIA Riva 是一种先进且基于深度学习的端到端语音 AI。 Riva 可以自定义调整优化。Riva 已经过预训练,具有世界一流的识别率,客户可以使用定制数据调优,使其学习行业,国家和地区,或公司的特定话术。Riva 是对话式 AI 服务的理想选择。Snap、RingCentral、Kore.ai 等众多公司都在使用 Riva.今天,我们正式宣布 Riva 全面发行,2.0 版的 Riva 支持识别 7 种语言,可将神经文本转换为不同性别发声的语音并可以通过我们的 TAO 迁移学习工具包进行自定义调优.
Riva 可以在各类云上运行,也可以在各类有 NVIDIA GPU 的地方运行,几乎无所不在.
NVIDIA Maxine
Maxine 是集合最先进 AI 算法的 SDK,它为重塑通讯方式而生。 视频会议系统需要对图像和声音进行编码、传输和解码操作。计算机视觉(Computer Vision)将取代传统图像编码,而计算机图形(Computer Graphics)将取代传统图像解码,语音识别(Speech Recognition)将取代传统音频编码,并且语音合成(Speech Synthesis)将取代传统音频解码。 在 AT&T 在纽约世博会上演示了可视电话之后的 55 年后,AI 将为视频会议带来革新。远程工作将常态化。我们对虚拟实时交互的需求已远超从前。Maxine 是一个 AI 模型工具包,开发者可以使用它来重塑通信和协作方式。Maxine 目前已拥有 30 个模型。本次 GTC 发布的版本增加了用于回声消除和音频超分辨率的新模型。我们来看看 Maxine 可以做什么。
视频介绍
NVIDIA Maxine 利用 AI 的强大功能重塑了实时视频通信。 借助 Maxine,我们现在可以更好地倾听和看到彼此,增加包容感和亲密度, 即使不同语言是障碍。 为了与观众保持互动,Maxine 可以帮我与会议上的所有人保持眼神交流。 不管是面对一个人,还是一百个人;即使我正在读稿。 如何借助 Maxine 克服语言障碍? 虽然我不会说西班牙语,但借助 Maxine,我现在可以了。 现在,我可以用自己的声音说出您的语言。还不错吧? 现在,我可以用自己的声音说出您的语言。还不错吧? 太出色了。 太棒了。但是,Maxine 能否翻译多种语言呢? 当然可以。 借助 Maxine,我还可以讲法语,还有更多语言。 下次 GTC 时,我们将向您介绍 Maxine 更多强大的功能。 请持续关注,以免错过精彩内容。 非常棒!我将会出席。
NVIDIA Merlin
推荐系统是个性化引擎。互联网上有着上万亿的内容并且日新月异,例如新闻、社交视频、新产品信息等。
我们怎么能够从这些海量信息中找到需要的内容呢?推荐系统学习物品的特征、您的显性或隐形偏好,然后为您推荐可能感兴趣的内容,这就是个性化互联网。先进的推荐引擎推动着全球消费互联网服务的发展,未来,它还将推动金融服务、医疗健康服务、旅游等行业的发展。NVIDIA Merlin 是用于推荐系统的 AI 框架。Merlin 由推荐系统流程的端到端组件组成,包括特征转换、召回和模型排序。通过 NVIDIA Merlin,公司可以快速构建、部署和扩展先进的深度学习推荐系统。

Snap 使用 Merlin 来改善广告和内容推荐,在降低 50% 成本的同时,服务延迟也缩短了一半。腾讯微信基于 Merlin 将短视频推荐延迟缩短为原来的四分之一,并将吞吐量提升了十倍。从 CPU 迁移到 GPU,腾讯在该业务上的成本减少了一半。在这次 GTC,我们将正式发布 Merlin 的 1.0 版本。
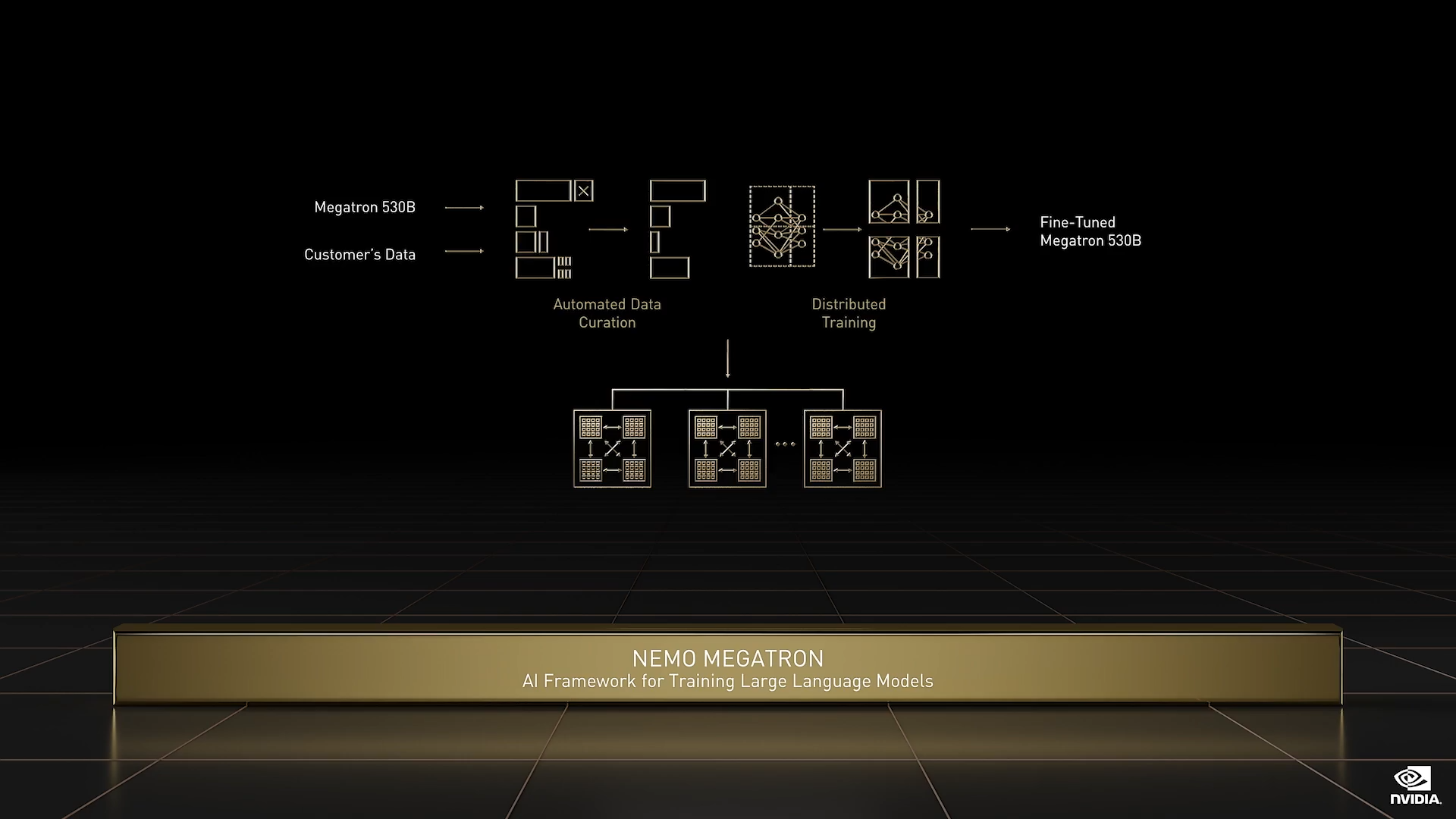
Nemo Megatron
Transformer 彻底革新了自然语言处理。训练大型语言模型需要极大的勇气,因为这是一项巨大的计算机科学挑战。OpenAI 的 GPT-3 有 1750 亿个参数。NVIDIA Megatron 有 5300 亿个;Google 的新版 Switch Transformer 有 1.6 万亿个参数。 Nemo Megatron 是一款专门用于训练大型语言模型的 AI 框架,其支持的参数规模可高达数万亿。为了在目标基础架构上实现最佳性能,Nemo Megatron 可以自动执行数据、张量及流水线并行、编排和调度,并且自动适应不同精度。Nemo Megatron 现已支持各类 NVIDIA 系统,自动超参数调优,针对您的目标基础架构。Nemo Megatron 也是云原生的框架,现已支持 Azure,很快会支持 AWS。
NVIDIA AI Accelerated Program
NVIDIA H100, Hopper and Grace
AI 是智能的创造和生产者,这是一项具有重大意义的事业,涉及计算的方方面面和每个行业。NVIDIA AI 库和 SDK 将加速整个 AI 生态系统中的软件、平台和服务。即使拥有出色的工具和库,开发者和 NVIDIA 也必须投入大量的开发工程来确保其性能、可扩展性、可靠性和安全性。因此,我们创建了 NVIDIA AI 加速计划,通过与 AI 生态系统中的开发者合作开发工程化解决方案,确保客户放心部署。
NVIDIA AI 使 AI 实现普及,让各个行业和公司都可以应用 AI 自我重塑。其中,数字生物学的革命尤为引人瞩目:AI 加速了 DNA 测序、蛋白质结构预测、新型药物合成和虚拟药物测试。在过去几年中,AI 药物研发初创公司获得了超过 400 亿美元的投资。Insilico Medicine 刚刚将其首个由 AI 研发的药物送入人体临床试验阶段。发现新药和靶点仅用了不到 18 个月的时间,比之前快了数年。数字生物学革命的条件已经成熟,这将是 NVIDIA AI 迄今为止最伟大的使命。
语音、对话、客户服务和推荐系统等 AI 应用正在推动数据中心设计的根本性变化。AI 数据中心会处理大量的连续数据来训练和完善 AI 模型。原始数据进入其中,经过提炼,最终得到智能结果。
NVIDIA H100
许多公司都致力于制造智能和运营大型 AI 工厂。工厂需要 24 小时不停歇的持续密集运作,质量上的细微改进会使客户参与度和公司利润得到显著提高。世界各地的公司中正在不断出现一个名为 MLOps 的新组织。该组织的基本使命是高效、可靠地将数据转化为预测模型,也就是将其转化为智能。它们处理的数据会呈指数级增长,这是因为模型的预测能力越强,参与服务的客户就越多,收集的数据也会随之增长。计算基础架构是 MLOps 的基石,其引擎是采用 Ampere 架构的 A100。
今天,我们将发布新一代产品,这是全球 AI 计算基础架构引擎的巨大飞跃。隆重推出 NVIDIA H100。

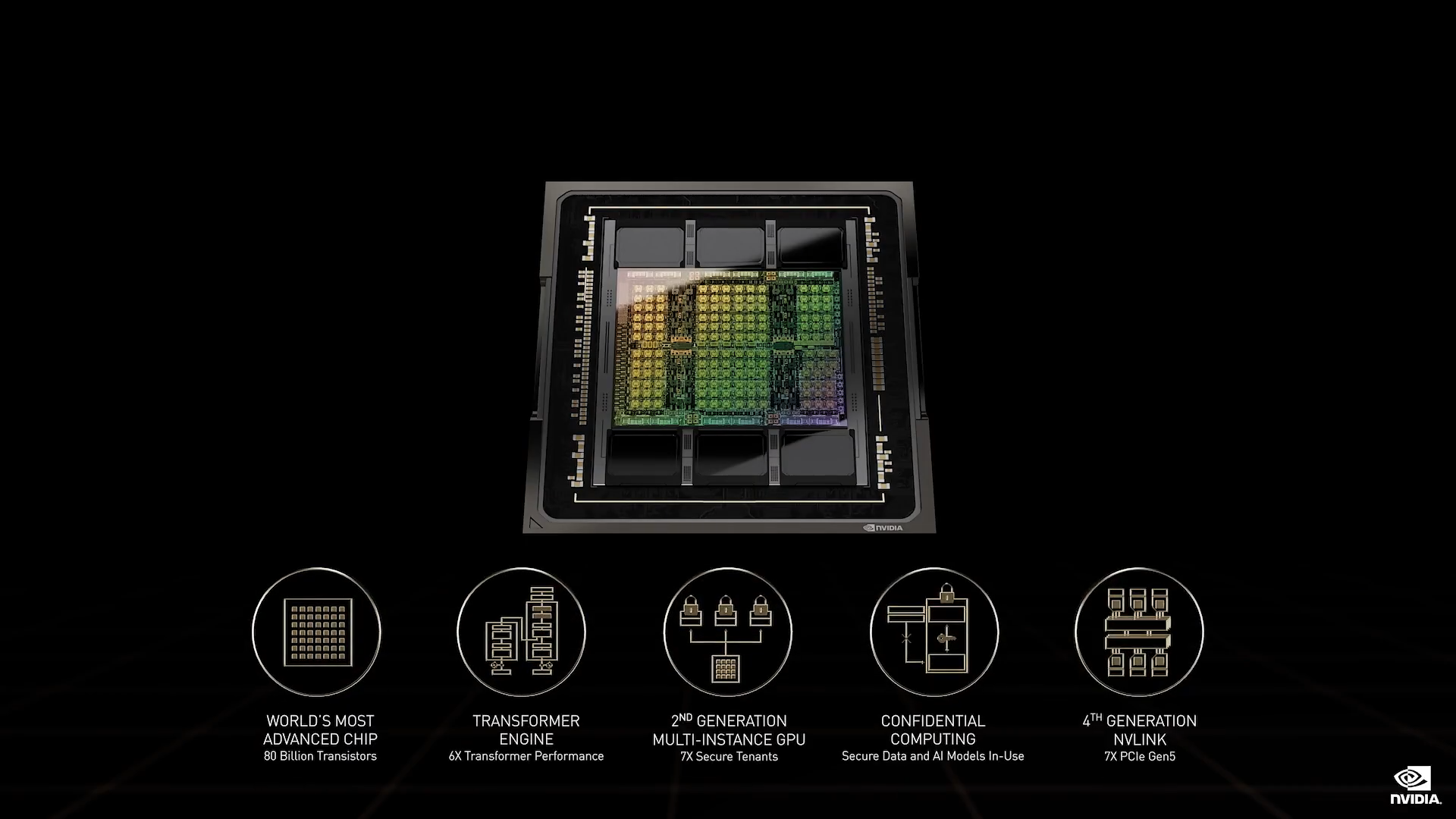
H100 是一款超大的芯片,采用 TSMC 4N 工艺,具有 800 亿个晶体管。我们设计 H100 是为了用于纵向扩展和横向扩展,因此带宽,也就是内存、网络以及 NVLink 芯片之间的数据速率尤为重要。H100 是首款支持 PCIe 5.0 标准的 GPU,也是首款采用HBM3标准的 GPU。单个 H100 可支持 40 Tb/s 的 IO 带宽。从另一个角度来说,20 块 H100 GPU 便可承托相当于全球互联网的流量。Hopper 架构较之前一代 Ampere 架构,是一个巨大的飞跃。
我来着重介绍 5 项突破性的创新。
首先,H100 拥有强大的性能。新的 Tensor 处理格式:FP8。H100 具备以下运算能力:
- 4 PetaFLOPS 的 FP8
- 2 PetaFLOPS 的 FP16
- 1 PetaFLOPS 的 TF32
- 60 TeraFLOPS 的 FP64 和 FP32
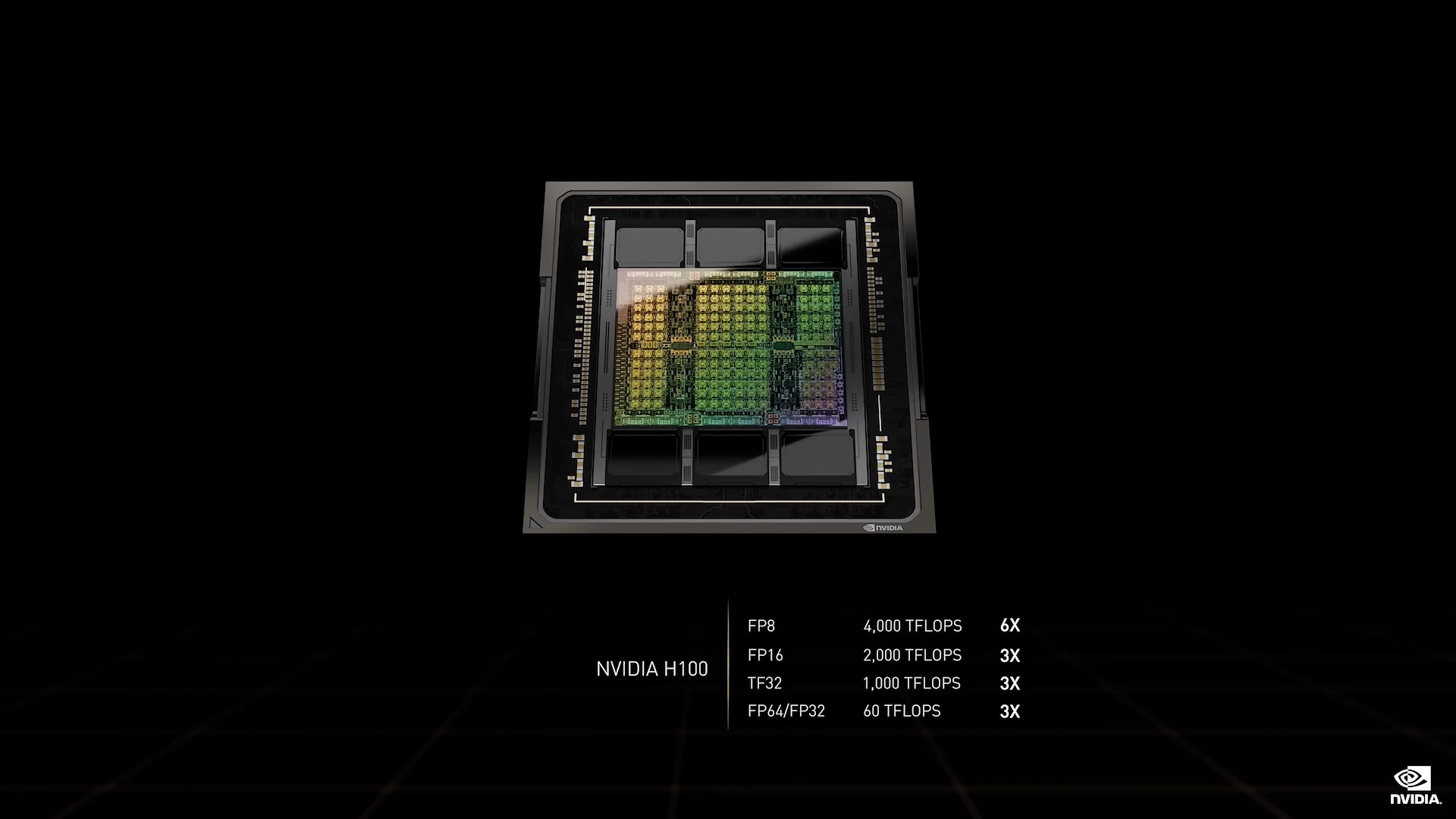
H100 采用风冷和液冷设计,是首个实现性能扩展至 700 瓦的 GPU。在过去六年里,通过 Pascal、Volta、Ampere 和现在的 Hopper 架构,我们相继开发了使用 FP32、FP16和现在的 FP8 进行训练的技术。在 AI 处理方面,Hopper H100 FP8 的 4 PetaFLOPS 性能是 Ampere A100 FP16 的 6 倍,这是一次巨大的代际飞跃。
![]()
Transformer 无疑是最重要的深度学习模型。Hopper 引入了Transformer 引擎,Hopper Transformer 引擎将新的 Tensor Core 与能使用 FP8 和 FP16 数字格式的软件结合,动态处理 Transformer 网络的各个层,Transformer 模型训练时间可从数周缩短至数天。
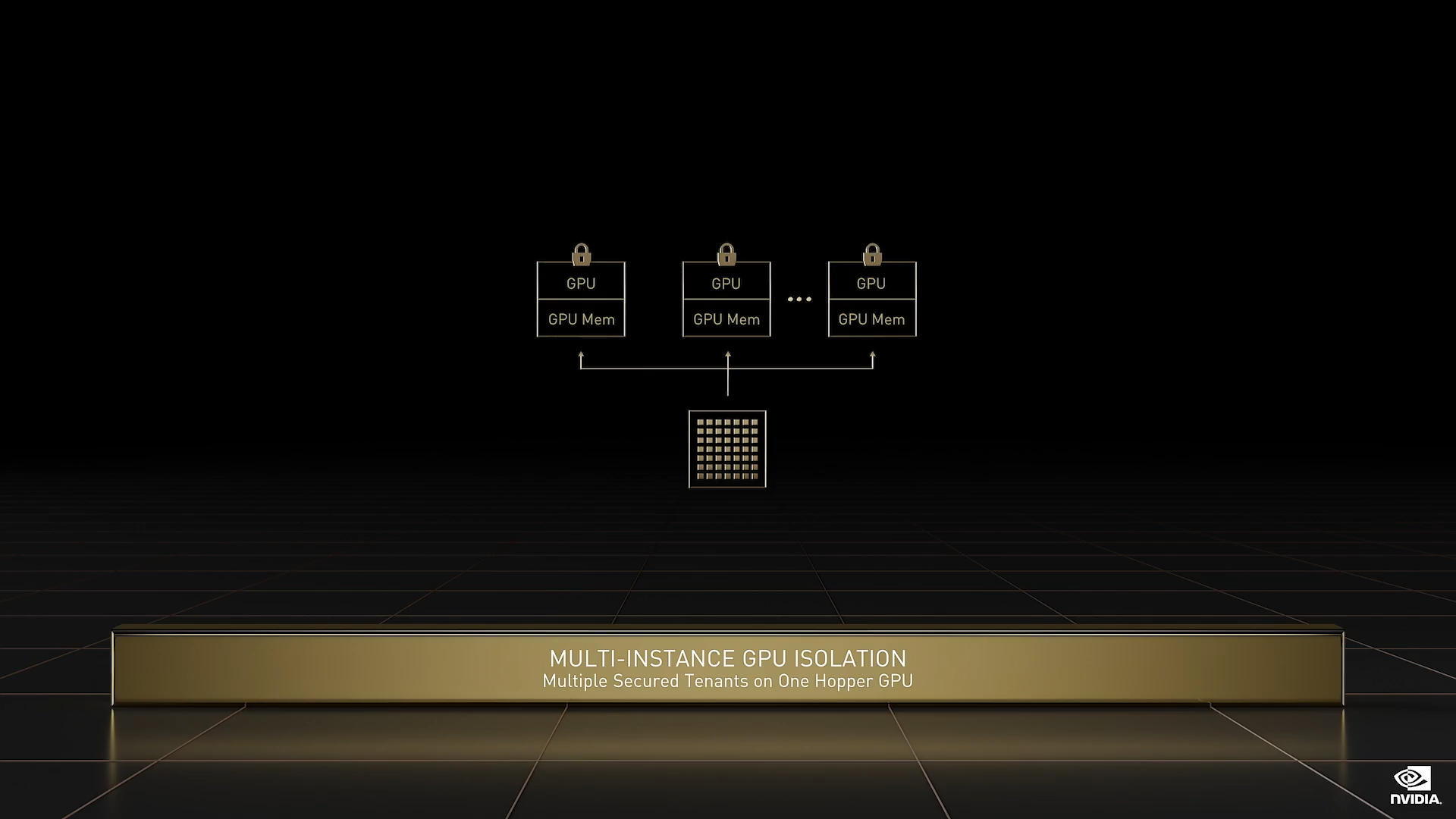
在云计算方面,多租户基础架构能够直接转化为收益和服务成本。一项服务可将 H100 划分为多达 7 个实例,Ampere 也可实现此操作。但是,Hopper 新增了完整的每实例隔离和每实例 IO 虚拟化,便于支持云端的多租户。H100 能够托管七个云租户,而 A100 仅能托管一个。每个 H100 实例的性能相当于两个完整的 T4 GPU(我们非常热门的云推理 GPU)。
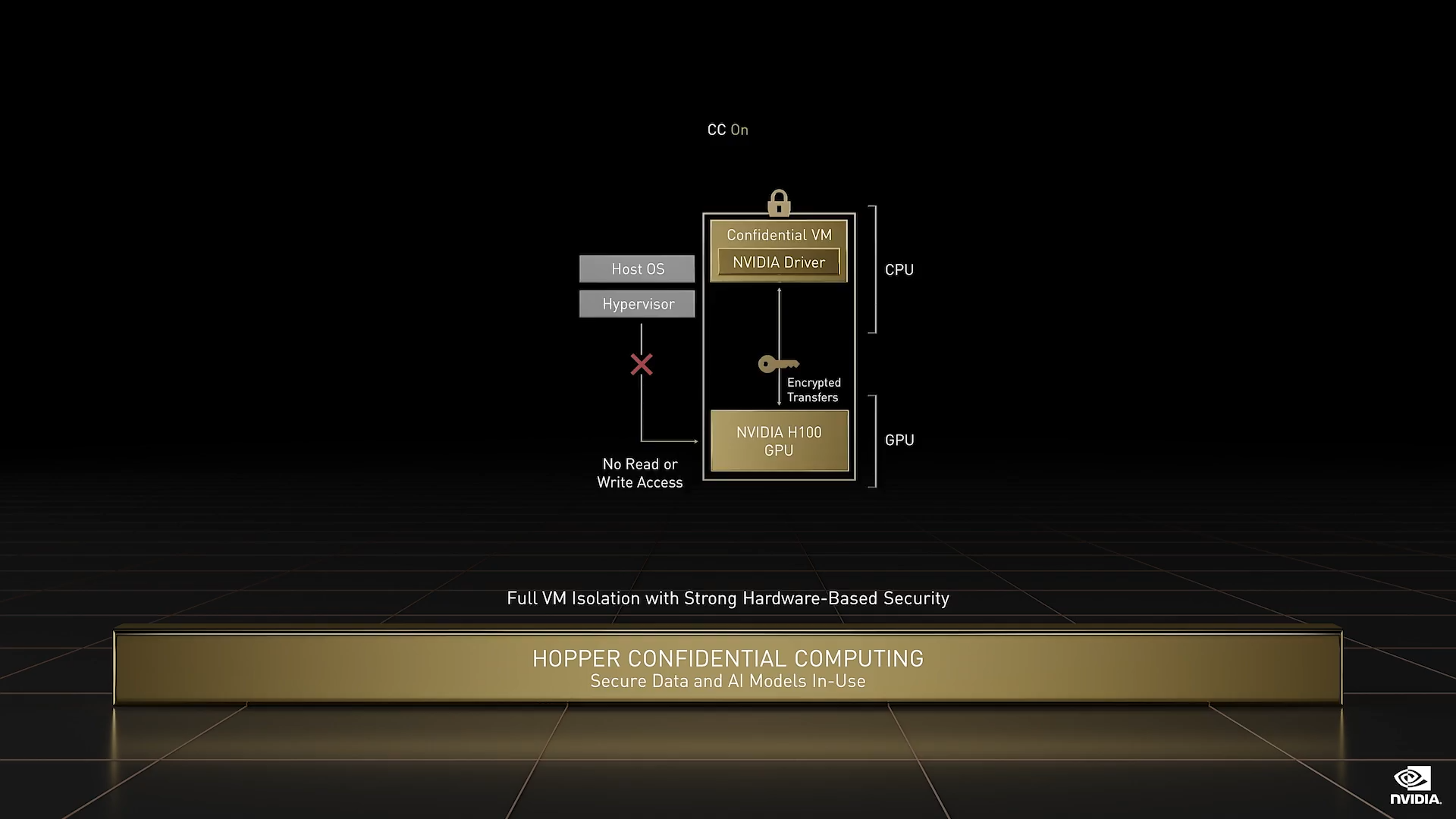
每个 Hopper 实例都支持在受信任执行环境中进行机密计算。通常,敏感数据处于静态以及在网络中传输时会进行加密,但在使用期间却不受保护。此类数据可以是一个 AI 模型,依托数百万美元的投资打造而成,基于多年的领域知识或公司专有数据进行了训练,并且具有价值或机密性。Hopper 机密计算是处理器架构和软件的结合,能够通过保护正在使用的数据和应用,弥合这一差距。目前,机密计算只能基于 CPU,Hopper 实现了首个 GPU 机密计算。Hopper 机密计算能够保护所有者的 AI 模型和算法的机密性和完整性。软件开发者和服务提供商现可在共享或远程基础架构上分发和部署宝贵的专有 AI 模型,保护其知识产权并扩展业务模式。

此外,还有更多强大功能:Hopper 引入了一组名为 DPX 的新指令集,旨在加速动态编程算法。许多实际算法的组合复杂性或指数复杂性在不断的增长,比如:
- 著名的旅行商优化问题,能够进行最短路径优化,
- 在绘图中使用的 Floyd-Warshall 算法。
- 通过模式匹配进行基因测序和蛋白质折叠计算的 Smith-Waterman 算法。
- 许多图优化算法。
动态编程能够将复杂问题分解为可递归式解决的更简单的子问题,从而将复杂性和计算时间缩减至多项式计算的级别。Hopper DPX 指令集会使这些算法的速度加快多达 40 倍。

H100 是 AI 基础架构的最新引擎,H100 采用 TSMC CoWoS 2.5D 封装,搭 载了 HBM3 显存,并与电压调节集成至名为 SXM 的超级芯片模组中。
NVIDIA DGX H100, NVLinkd Switch, DGX POD, DGX SuperPOD, EOS
现在,我来向大家展示如何构建先进的 AI 计算基础架构: 8 个 H100 SXM 模组通过 HGX 主板上的4 个 NVLink Switch 芯片相连,这 4 个超高速 NVSwitch 芯片各具有3.6 TFLOPS的 SHARP 网络计算性能。

SHARP 技术最早在 Mellanox Quantum InfiniBand 交换机中被率先发明,对于广泛用于深度学习和科学计算的 all-to-all reductions 计算,SHARP 能够有效将带宽提高 3 倍。
CPU 子系统由两个第 5 代 CPU 和两个网络模组组成,两个模组各配备四个 400 Gbps 的 ConnectX-7 InfiniBand 或 400 Gbps 的以太网网络芯片。ConnectX-7 拥有 80 亿个晶体管,是全球最先进的网络芯片。总计 640 亿个晶体管能够实现 3.2 Tb/s 的网络传输。

隆重发布 DGX H100 - 我们全新的 AI 计算系统。 DGX 取得了令人瞩目的成功,在《财富》10 强企业和 100 强企业中,分别有 8 家和 44 家企业使用 DGX 作为 AI 基础架构。
借助 NVLink 连接,DGX 使八块 H100 成为了一个巨型 GPU:
- 6400 亿个晶体管
- 32 PetaFLOPS 的 AI 性能
- 640 GB HBM3 显存
- 24 TB/s 的显存带宽

DGX H100 实现了巨大的飞跃,此外,还有更多强大功能!
我们采用全新方式扩展 DGX:我们可以借助 NVLink 连接多达 32 个 DGX。 现在,我们宣布推出 NVIDIA NVLink Switch 系统。

对于 AI 工厂而言,DGX 是最小的计算单元。借助 NVLink Switch 系统,我们可以将其扩展为一个巨大的拥有 32 个节点、256 个 GPU 的 DGX POD。并且 HBM3 显存高达 20.5 TB,显存带宽高达 768 TB/s。768 TB/s,可谓超高速!相比之下,整个互联网不过只有 100 TB/s。每个 DGX 都可借助 4 端口光学收发器连接到 NVLink Switch,每个端口都有 8 个 100G-PAM4 通道,每秒能够传输 100 GB。32 个 NVLink 收发器连接到 1 个机架单元的 NVLink Switch 系统。本质上,H100 DGX POD 是一款令人振奋的 GPU:
- 1 ExaFLOPS 的 AI 计算能力
- 20 TB 的 HBM3 显存
- 192 TF 的 SHARP 网络计算性能
- 在 GPU 之间移动数据的对分带宽惊人,高达70 TB/s

多个 H100 DGX POD 连接到我们新的 Quantum-2 400 Gbps InfiniBand 交换机,具有 SHARP 网络内计算技术,性能隔离和拥塞控制等功能特性,可扩展到具有数千个 H100 GPU 的 DGX SuperPOD。Quantum-2 交换机的芯片拥有 570 亿个晶体管,进而能够提供 64 个 400 Gbps 端口。
DGX SuperPOD 是现代 AI 工厂。

我们正在建造 EOS,这是 NVIDIA 打造的首个 Hopper AI 工厂,她将艳惊四座:
- 18 个 DGX POD
- 576 台 DGX
- 4608 个 H100 GPU

在传统的科学计算领域,EOS 的速度是 275 PetaFLOPS,若与 A100 驱动的美国速度最快的科学计算机 Summit 相比要快 1.4 倍。在 AI 方面,EOS 的 AI 处理速度是 18.4 ExaFLOPS,若与全球最大的超级计算机 – 日本的 Fugaku 相比要快 4 倍。我们期待 EOS 成为全球运行速度最快的 AI 计算机系统。
对于我们的 OEM 和云合作伙伴而言,EOS 将会是先进 AI 基础架构的蓝图,合作伙伴可以整体采用 H100 DGX SuperPOD,或采用我们平台中四个层的任意一层的技术组件。
我们已在着手打造 EOS,将于数月后推出。
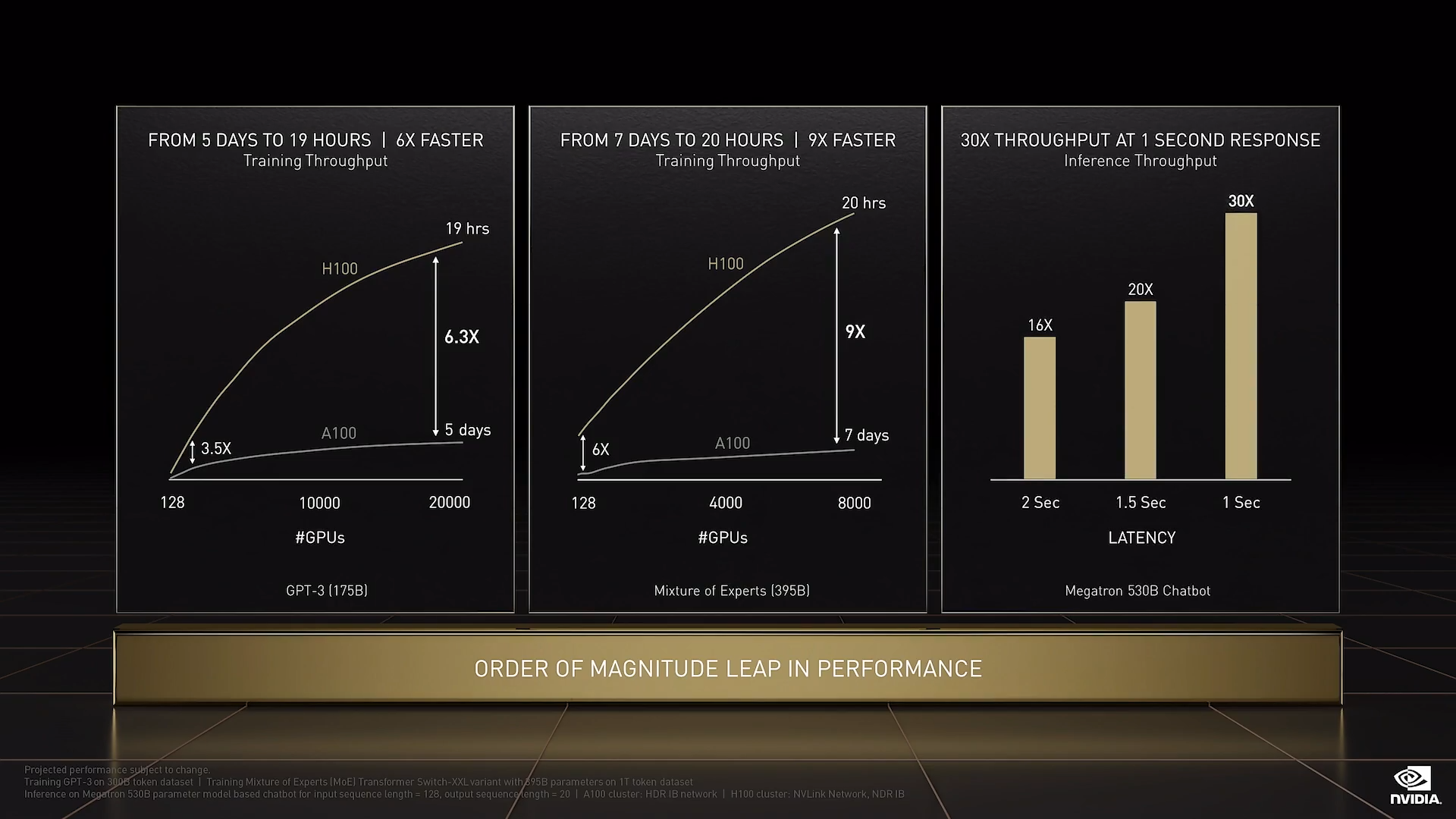
我们来看看 Hopper 的性能:与 Ampere 相比,Hopper 的性能提升令人惊艳。 训练 Transformer 的模型、结合 Hopper 的原始性能,具有 FP8 Tensor Core 的 Hopper Transformer 引擎,采用 SHARP 网络计算技术的 NVLink、可连接 256 个 GPU 的 NVLink Switch、Quantum-2 InfiniBand以及我们所有的软件,这些综合效益共同成就了 9 倍的速度提升!计算时间从数周缩短至几天。
在推理大型语言模型方面,H100 的吞吐量比 A100 高 30 倍。
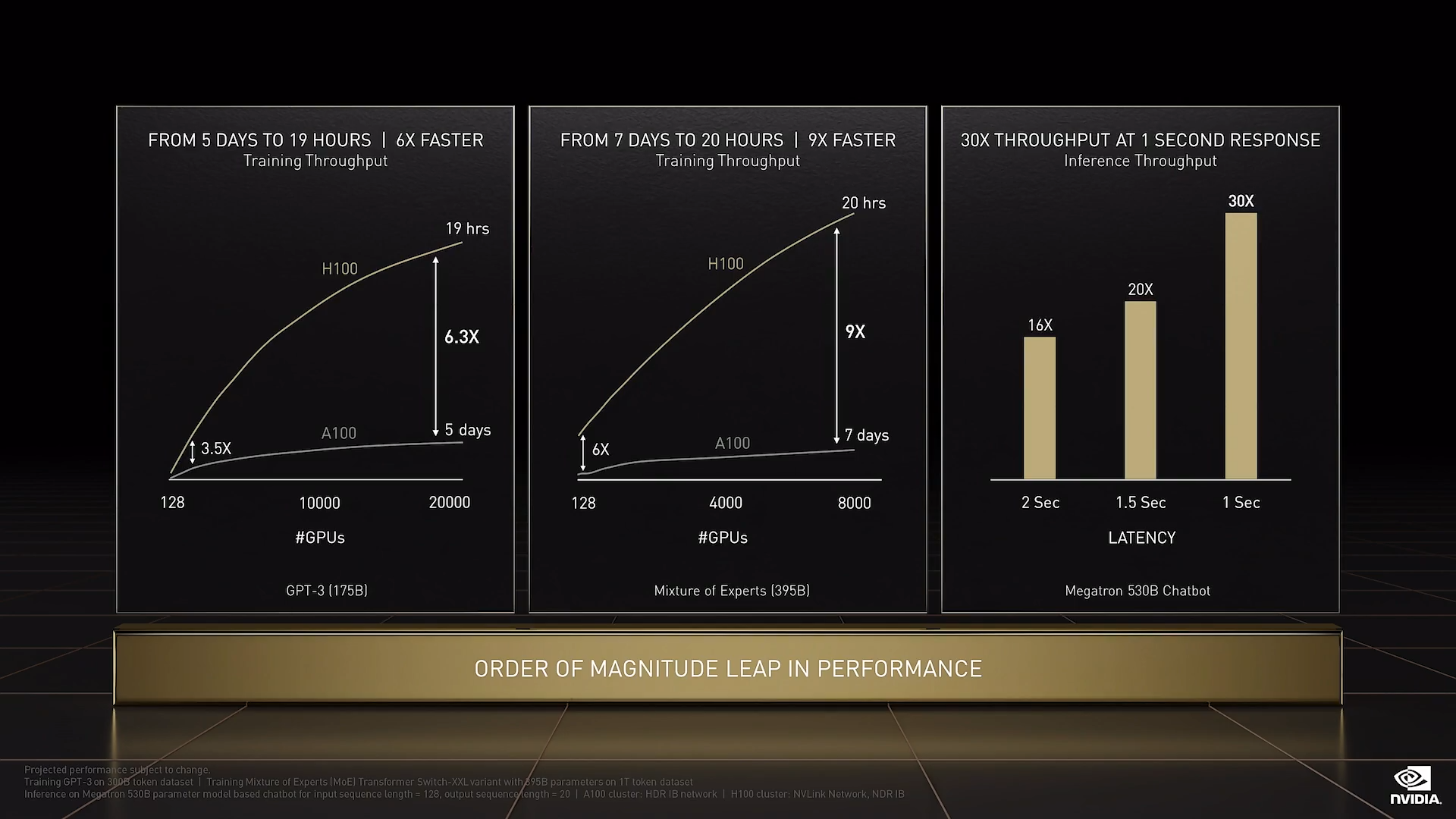
H100 是我们实现的巨大飞跃。
NVIDIA H100 是全球 AI 基础架构的新引擎,Hopper 也将成为主流系统游戏规则的改变者。正如您在 Hopper HGX 和 DGX 中看到的一样,网络和互连产品对于计算至关重要。
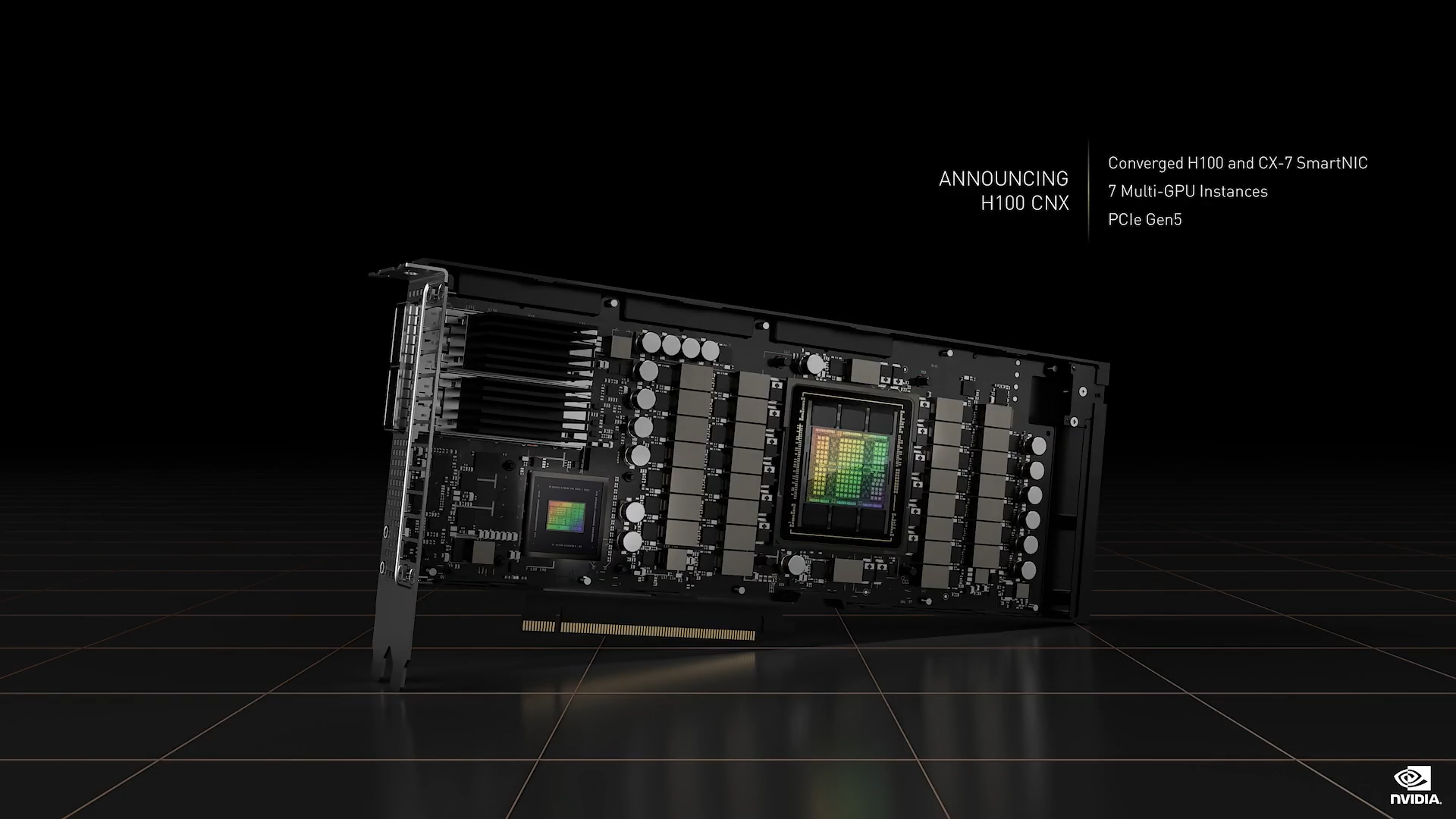
移动数据以保持超快速的 GPU 数据馈送值得高度关注。那么,我们如何将 Hopper 强大的计算能力引入主流服务器?在传统服务器中移动数据会使 CPU 和系统内存过载,并受到 PCIe 的限制。解决方案是将网络直接与 GPU 相连,这就是 H100 CNX。
它将先进的 GPU 和强大的网络处理器 ConnectX-7融合至一个模组中。网络数据通过 DMA 以 50 GB/s 的速度直接传输至 H100,从而避免 CPU系统内存和 PCIe 等多个通道的限制。H100 CNX 能够避免带宽瓶颈,同时释放 CPU 和系统内存,以便处理应用的其他部分,在一个为主流服务器设计的小巧封装中包含了大量令人难以置信的技术。
Hopper H100 支持各种规模的系统,包括用于主流服务器的 PCIe 加速器以及 DGX、DGX POD 和 DGX SuperPOD。
这些系统能够运行 NVIDIA HPC、NVIDIA AI 以及 CUDA 库的丰富生态系统。

下面我来介绍一下 Grace 的最新进展,这是我们的首款数据中心 CPU。 我很高兴地宣布,Grace 进展飞速,有望明年供货。
Grace 专为处理海量数据而设计,它将成为 AI 工厂的理想 CPU,这就是 Grace-Hopper。它是单一超级芯片模组,能够在 CPU 和 GPU 之间进行芯片间的直接连接。Grace-Hopper 的关键驱动技术之一是内存一致性芯片之间的 NVLink 互连,每个链路的速度达 900 GB/s!

但前面我只讲了一半的故事,Grace 的一切都令人赞叹。
Grace CPU 也可以是由两个通过芯片之间的 NVLink 连接,保证一致性的 CPU 芯片组成的超级芯片。 Grace 超级芯片拥有 144 个 CPU 核心!而且,内存带宽高达 1 TB/s,速度之快着实惊人,是尚未发布的第 5 代顶级 CPU 的 2 到 3 倍。我们预估 Grace 超级芯片的 SPECint 2017 得分为 740,目前几乎没有任何产品可与之媲美。

令人惊叹的是,整个模组(包括 1 TB 内存)的功率仅为 500 瓦。我们预计 Grace 超级芯片届时将是最强大的 CPU,拥有最高性能和两倍能效。Grace 将在 AI、数据分析、科学计算和超大规模计算领域有着惊人的表现,Grace 还将得到 NVIDIA 所有软件平台(NVIDIA RTX、HPC、NVIDIA AI 和 Omniverse)的支持。

Grace-Hopper 和 Grace 超级芯片的推动因素是超节能、低延迟、高速内存一致性 NVLink 芯片到芯片链路。借助从裸片之间、芯片之间以及系统之间的 NVLink 扩展,我们可以配置 Grace 和 Hopper,以便处理各种工作负载,我们可以通过 Grace 和 Hopper 打造不同的系统:
- 2 个 Grace CPU 组成的超级芯片
- 1 个 Grace 加 1 个 Hopper 组成的超级芯片
- 1 个 Grace 加 2 个 Hopper 的超级芯片
- 搭载 2 个 Grace 和 2 个 Hopper 的系统
- 2 个 Grace 加 4 个 Hopper 组成的系统
- 2 个 Grace 加 8 个 Hopper 组成的系统
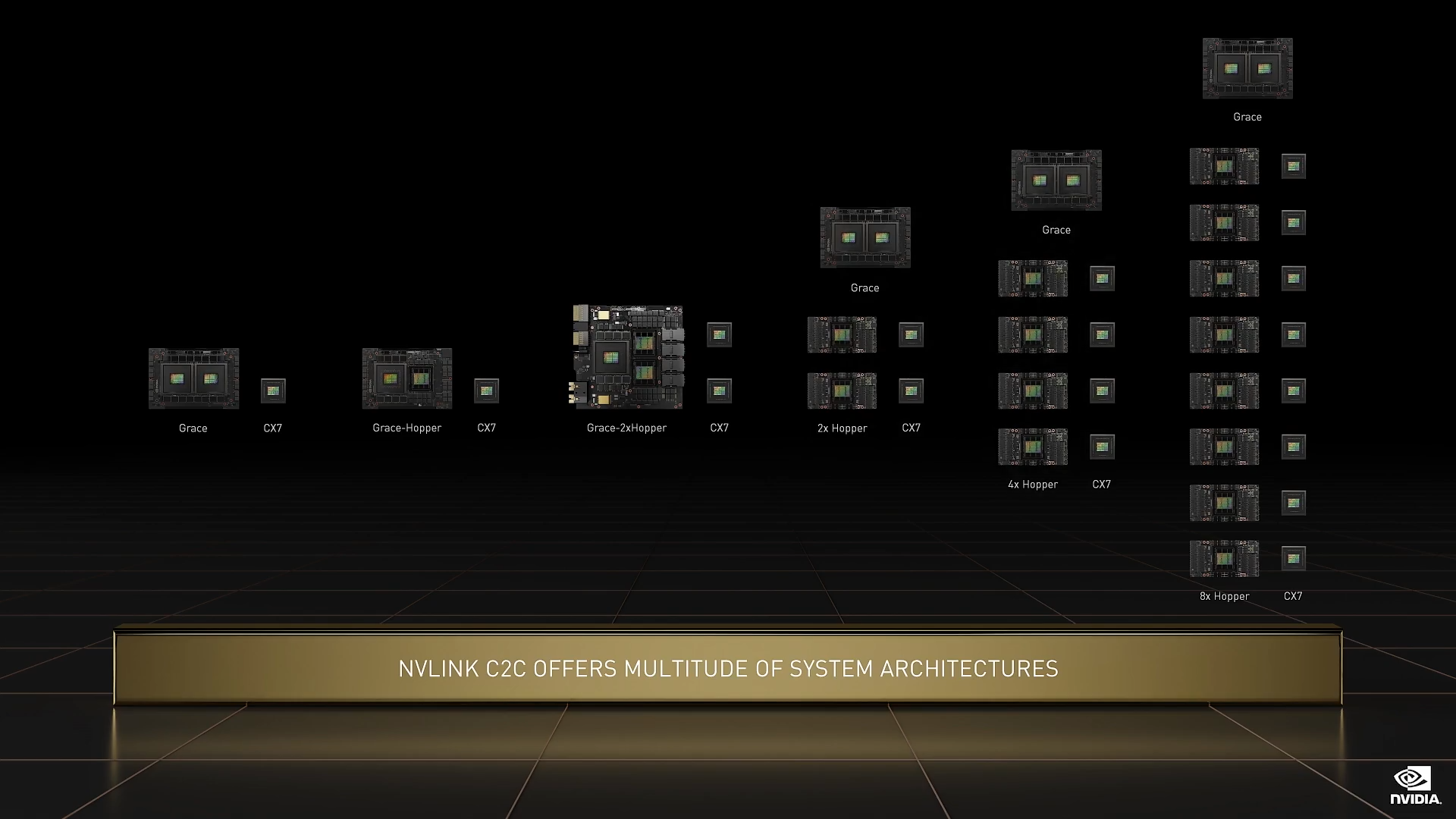
Grace 和 Hopper 的 NVLink 以及 ConnectX-7 中的 PCIe 5.0 交换机组合,能够为我们提供大量方法,解决客户的各种计算需求。未来的 NVIDIA 芯片,如 CPU、GPU、DPU、NIC 和 SOC,将像 Grace 和 Hopper 一样集成 NVLink。
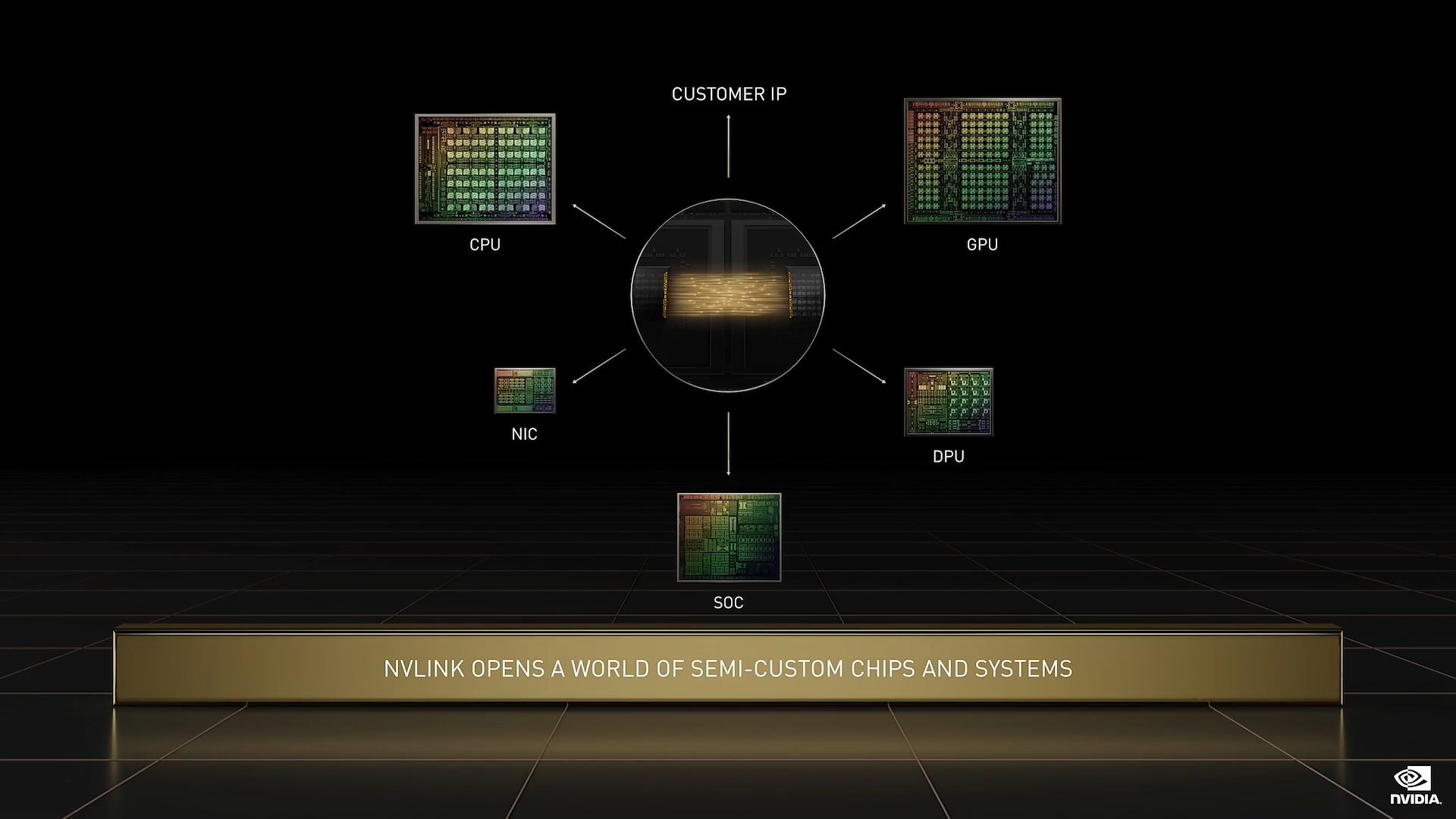
我们拥有十分出色的 SERDES 技术,凭借多年的高速显存位宽、NVLink 和网络交换机设计经验,NVIDIA 在高速 SERDES 方面掌握了出色的专业知识。NVIDIA 正在为那些希望采用连接到 NVIDIA 平台的定制芯片客户和合作伙伴提供 NVLink 和 SERDES。这些高速链路为通过 NVIDIA 计算构建半定制芯片和系统开辟了一个新的世界。
Nvidia SDK
过去十年,NVIDIA 通过 GPU 加速算法、全栈优化和整个数据中心的扩展,使计算速度实现了 Million-X 百万倍加速。计算机科学和工程在 NVIDIA SDK 中体现,具备 CUDA 库的 NVIDIA SDK 是加速计算的核心和灵魂。NVIDIA SDK 将我们与科学领域的新挑战和业界新机遇紧密相连。
RAPIDS
RAPIDS 是一套 SDK,可供数据科学家将热门 Python API 用于 DataFrame、SQL、数组,机器学习和图分析。RAPIDS 是 NVIDIA 备受欢迎的 NVIDIA SDK 之一,仅次于用于深度学习的 cuDNN。RAPIDS 的下载次数已达 200 万次,同比增长了 3 倍。它已在超过 5000 个 GitHub 项目和 2000 多个 Kaggle notebooks 中使用,并集成至 35 个商业软件包中。

NVIDIA RAPIDS for Spark 是用于加速 Apache Spark 的插件。Spark 是先进的数据处理引擎,80% 的《财富》500 强公司都在使用,Spark 用户可以透明地加速 Spark data-frame 和 SQL,原本需要数小时完成的操作现在只需数分钟即可完成。
cuOpt
NVIDIA cuOpt(之前称为 ReOpt)是一款 SDK,能够优化多代理、多约束的路线规划,用于仓库内的交付服务或自主移动机器人。借助 NVIDIA cuOpt,企业第一次可以在数秒内完成上千个包裹到上千个地点的实时规划,并且具备超高准确率。超过 175 家公司正在测试 NVIDIA cuOpt。

DGL
图是表示真实世界数据(如地图、社交网络、Web、蛋白质和分子以及金融交易)的常用数据结构之一。NVIDIA DGL 容器支持跨多个 GPU 和节点训练大型图神经网络。
Morpheus
NVIDIA Morpheus 是用于网络安全的深度学习框架。Morpheus 能够帮助网络安全开发者构建和扩展解决方案,这些解决方案使用深度学习技术,以前所未有的方式来识别、捕捉威胁并对威胁采取行动。每家公司都需要改用零信任架构,NVIDIA 无疑可使用 Morpheus。
cuQuantum
cuQuantum 是一种用于加速量子电路仿真器的 SDK,可让研究人员开发未来的量子算法(目前在量子计算机上无法探索这些算法)。
cuQuantum 能加速多种先进的 QC 仿真器,包括 Google Cirq、IBM Qiskit、Xanadu 的 Pennylane、Quantinuum TKET 和橡树岭国家实验室的 ORNL ExaTN,DGX 上的 cuQuantum 是非常适合量子计算的开发系统。

Aerial
Aerial 是一款适用于 CUDA 加速的软件定义的 5G 无线网络的 SDK。借助 Aerial,无论是数据中心、云、本地,还是边缘,均可成为 5G 无线网络,并可为无 WIFI 服务的地方提供 5G AI 服务。6G 标准将于 2026 年左右问世,6G 是大势所趋 – 数以千亿计的机器和机器人将成为网络用户中的主力军。6G 正围绕一些基础技术逐步形成雏形;与网络一样,6G 将很大程度上由软件定义。网络将由 AI 驱动,基于光线追踪和 AI 的数字孪生将有助于优化网络。NVIDIA 可以在这些领域做出贡献。
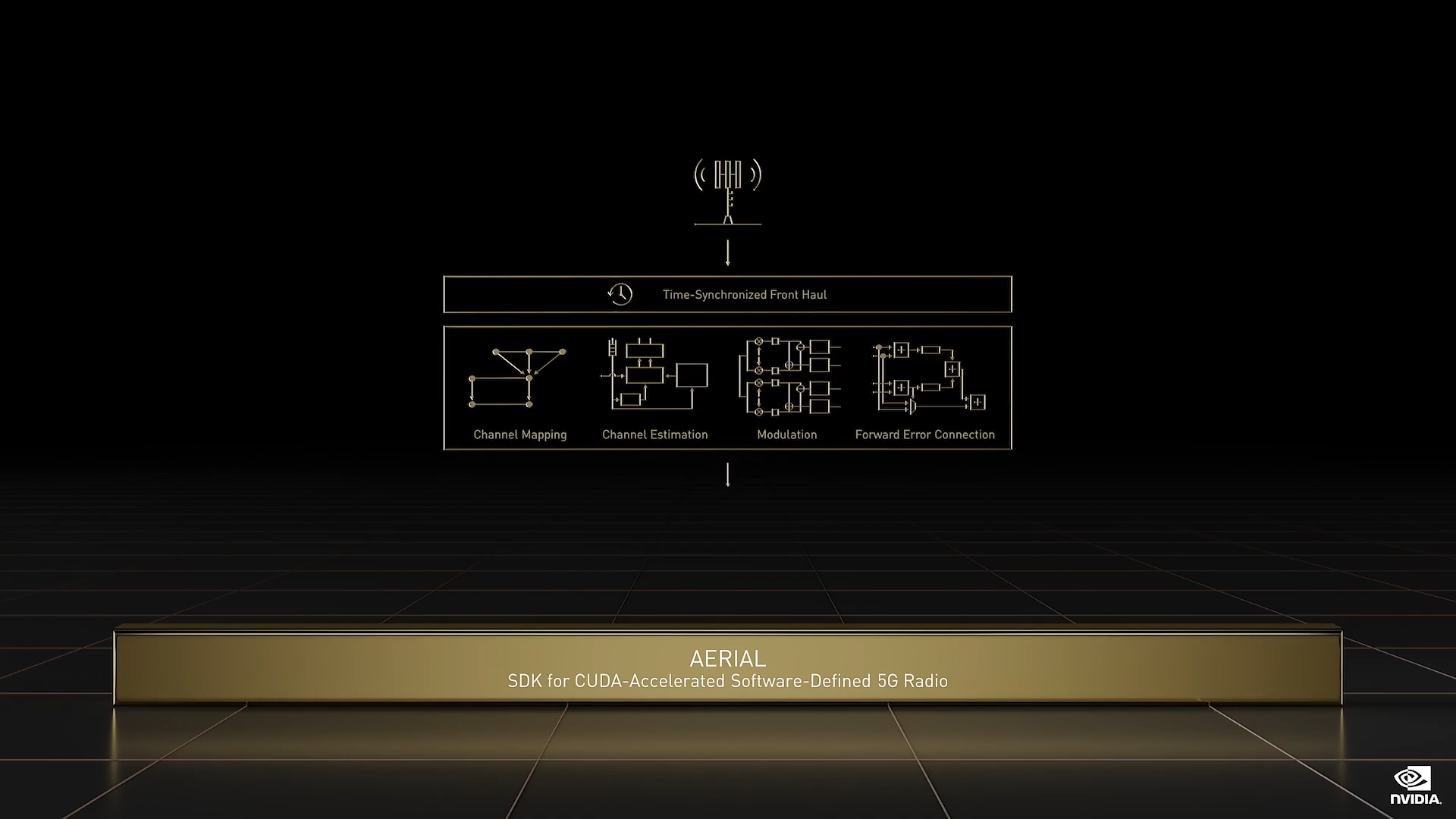
我们很高兴地宣布推出新框架 Sionna,它是一种用于 6G 通信研究的 AI 框架
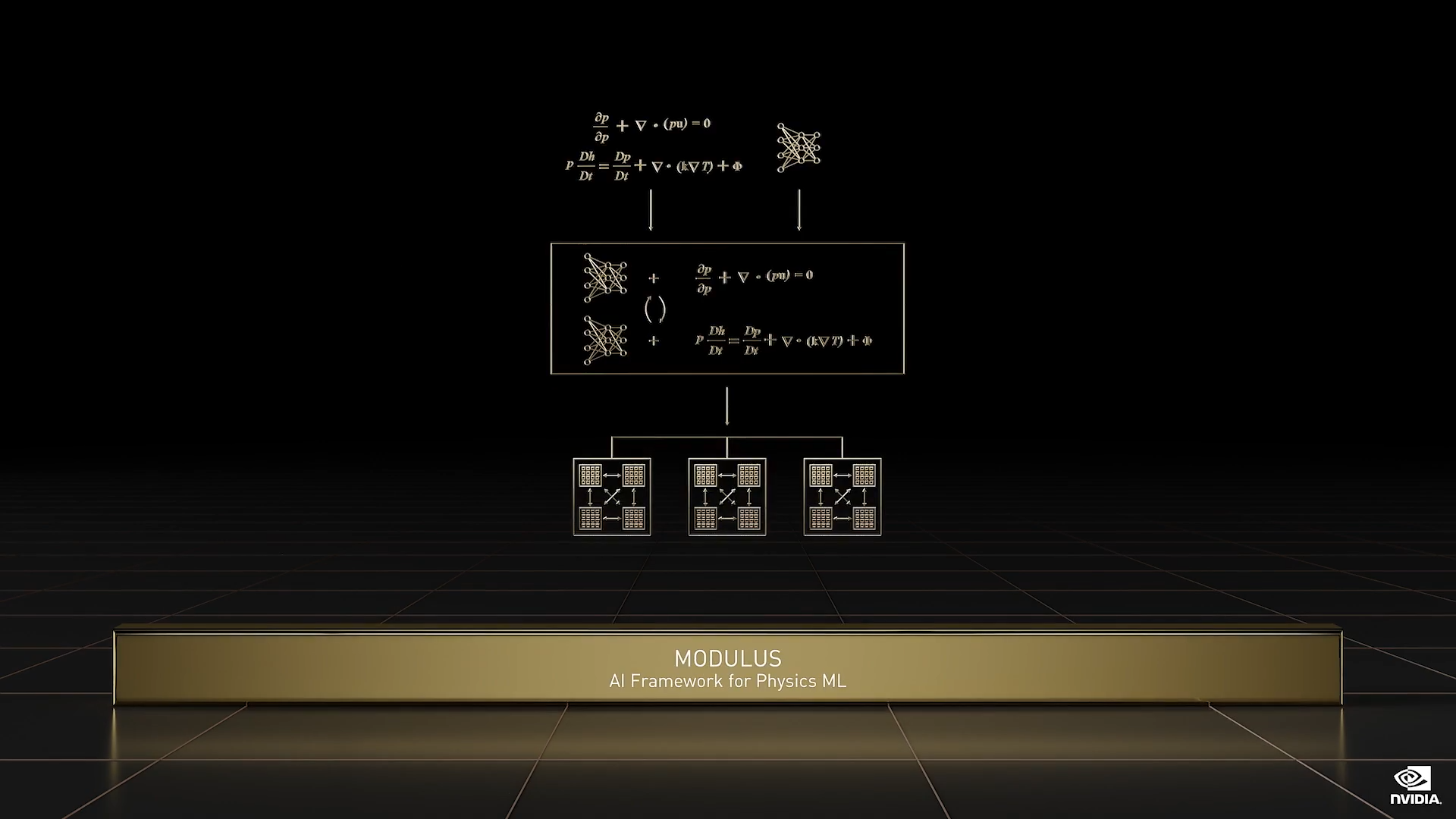
Modulus
Modulus 是用于开发 Physics–ML 模型的 AI 框架,这些深度神经网络模型可以学习物理学,并做出符合物理定律的预测,速度比数值方法快许多个数量级。
我们正使用 Modulus 构建 Earth-2 数字孪生。
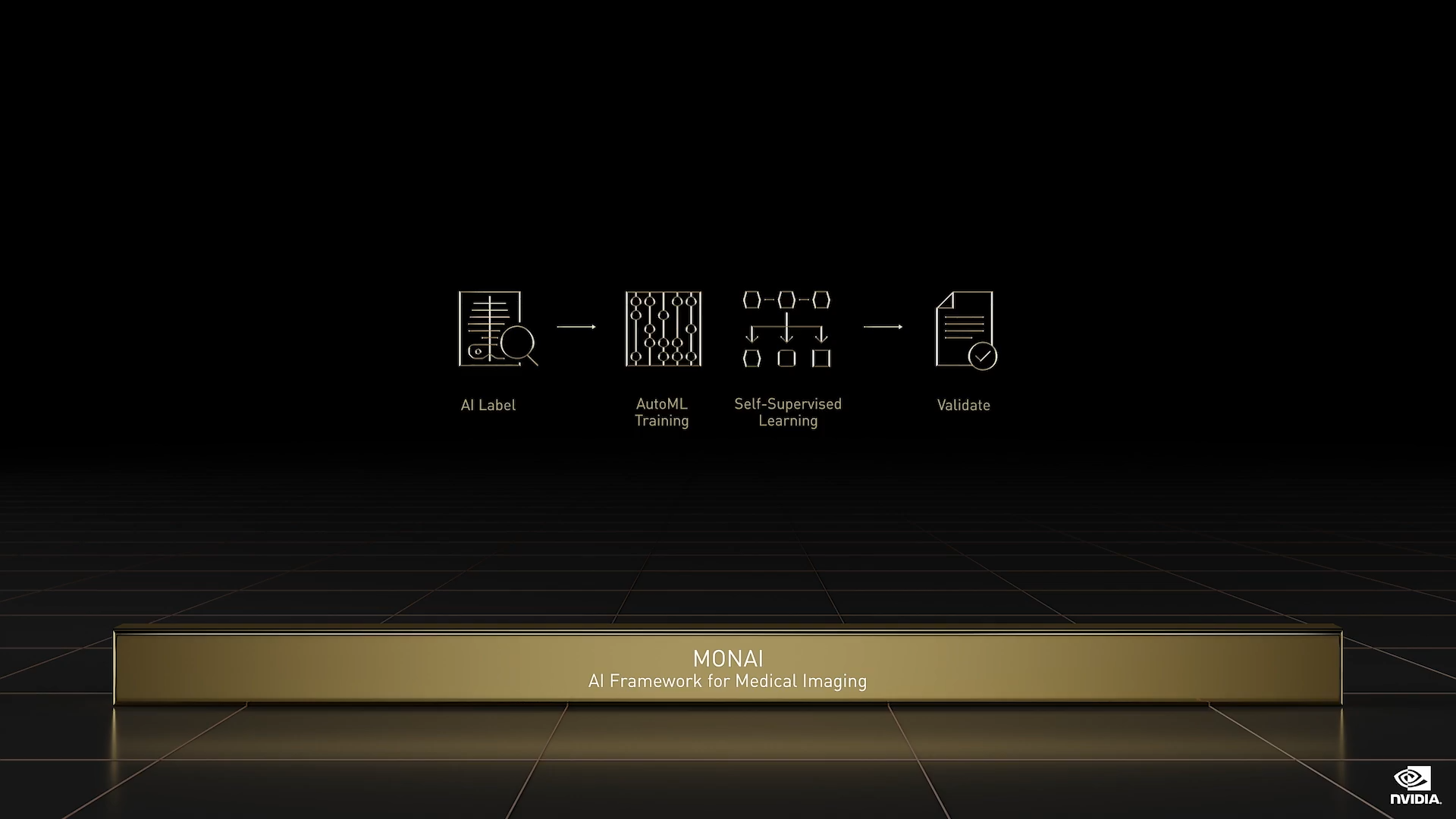
MONAI
MONAI 是一个用于医疗影像的开源 AI 框架。NVIDIA MONAI 容器包含 2D 和 3D 模型的 AI 辅助标注、迁移学习和 AutoML 训练,可通过 DICOM 轻松部署。世界排名前 30 的学术医疗中心正在使用 MONAI,下载超过 25 万次。
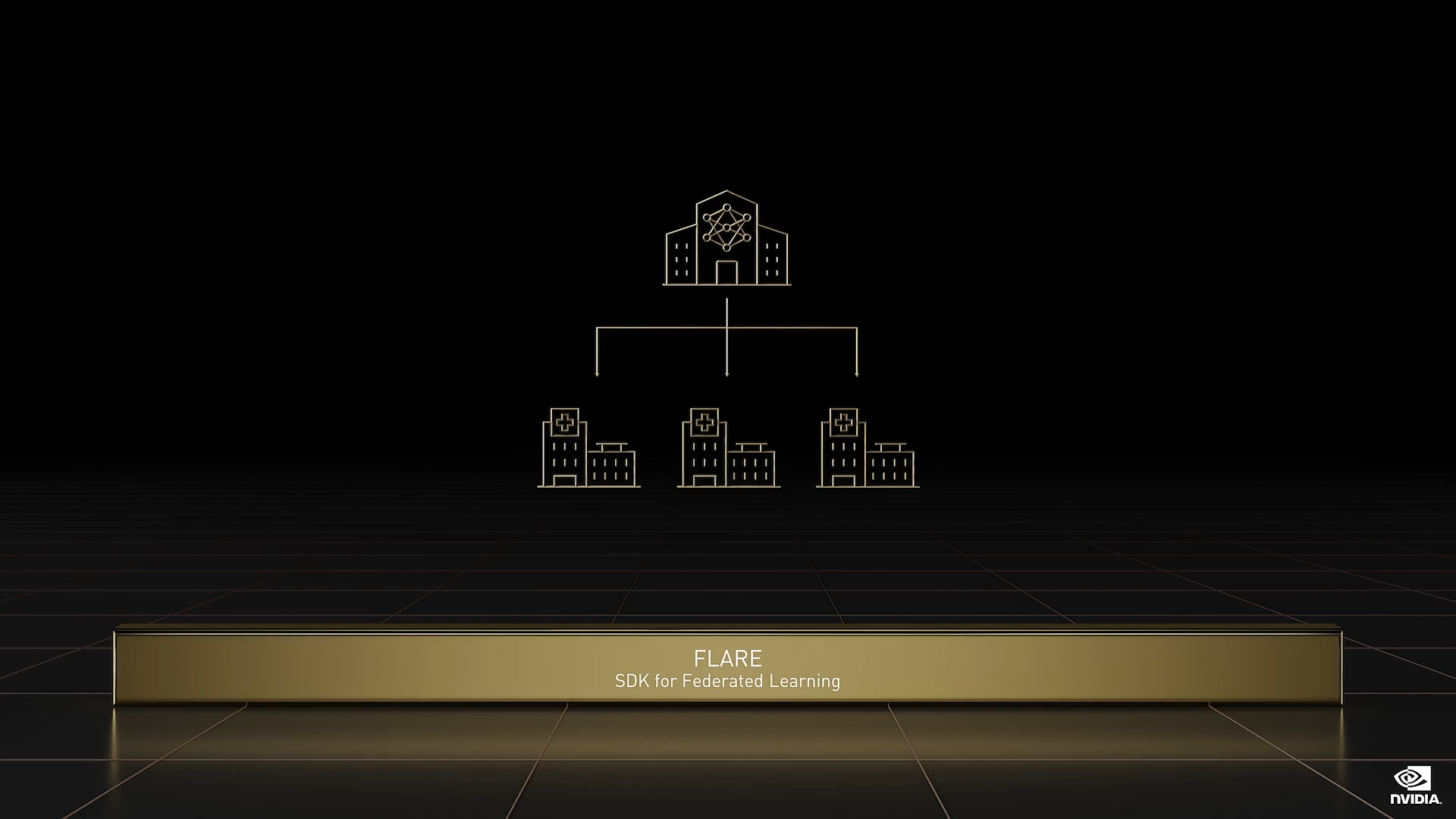
FLARE
FLARE 是用于联邦学习的 NVIDIA 开源 SDK,使研究人员能够以一种保护隐私的方式(即共享模型而非数据)开展协作。
数百万开发者和成千上万的公司使用 NVIDIA SDK 来加速处理工作负载。在本次 GTC 上我们更新了 60 个 SDK,加入了更多功能和加速技术,现有的 NVIDIA 系统变得更快。进行运筹学研究、量子算法研究、6G 研究或图分析的科学家将能首次使用 NVIDIA 加速技术。对于从事计算机辅助设计或工程的公司,他们所依赖的软件工具(由 Ansys、Altair、Siemens、Synopsys、Cadence 等公司开发)将获得大幅的速度提升。
亲身感受这些技术对工程技术实践带来的改变,请前往 NGC (NVIDIA GPU Cloud),下载经过全栈优化并提供数据中心级加速能力的SDK 和框架。
Omniverse
当某条电线发生故障导致两个氧气罐中的一个发生爆炸时,阿波罗 13 号的船员与地球相距 136000 英里。NASA 在无线电中听到了至今羞于提及的一句话 –“休斯顿,我们遇到问题了。”。为了“解决问题”,NASA 工程师在奥德赛号宇宙飞船的复制品上测试了氧气保存和开关机循环程序。如果没有在地球上建造的全功能复制品,阿波罗 13 号将会遭受灭顶之灾,这是一个重要时刻。NASA 意识到了复制模拟的力量,但并非所有事物都能具有实体孪生。因此,NASA 创造了术语“数字孪生”,用实时存在的虚拟物来表征物理实体。当扩展到极致时,数字孪生是一个与物理世界相连的虚拟世界。而在互联网背景下,它带来了下一次演进 这正是 NVIDIA Omniverse 的作用 – 数字孪生、虚拟世界以及互联网的下一次演进。20 多年来,NVIDIA 在图形、物理学、仿真、AI 和计算技术领域深耕不辍,最终打造出 Omniverse模拟这个世界是一项终极挑战。
- Omniverse 是虚拟世界的仿真引擎
- Omniverse 世界具备物理精准的特点,并且遵守物理学定律
- Omniverse 在宏大的维度上运行
- Omniverse 可共享,能将设计师、观看者、AI 和机器人连接起来
那么,Omniverse 有哪些应用场景?今天,我将重点介绍几个直接用例:
- 使用不同工具的设计师之间的远程协作
- 供 AI 和机器人学习的 Sim2Real Gym
- 工业数字孪生
不过,首先让我展示一些造就 Omniverse 的基础技术,Omniverse 技术将改变您的创作方式!
OVX
Omniverse 可从 RTX PC 扩展到大型系统,连接到托管 Omniverse Nucleus 的用户的 RTX PC 在性能上足以进行创意协作。然而,工业数字孪生需要一种专门构建的新型计算机。
数字孪生仿真涉及多个自主系统在同一时空内进行交互。
数据中心在尽可能短的时间内而不是按照精确的时间处理数据,对于数字孪生,Omniverse 软件和计算机必须具备可扩展、低延迟和支持精确时间的特点。
我们需要建造同步的数据中心(synchronized datacenter)。
正如我们为 AI 提供 DGX 一样,我们现在为 Omniverse 提供 OVX。
第一代 NVIDIA OVX Omniverse 计算机由8 个 NVIDIA A40 RTX GPU、3 个 ConnectX-6 200 Gbps 网卡 NIC和 2 个 Intel Ice Lake CPU 组成。

利用 NVIDIA Spectrum-3 200 Gbps 交换机连接 32 台 OVX 服务器就构成了 OVX SuperPOD。

最重要的是,网络和计算机使用精准时间协议进行同步,而且 RDMA 可更大程度降低数据包传输延迟。现在,全球各大计算机制造商纷纷推出 OVX 服务器。对于想在 OVX 上试用 Omniverse 的客户,NVIDIA 在全球各地提供了 LaunchPad 计划。第一代 OVX 正由 NVIDIA 和早期客户运行。
我们正在构建第二代 OVX – 从骨干网络开始。
今天,我们宣布推出 Spectrum-4 交换机:带宽高达 51.2 Tbps 且具有 1000 亿个晶体管的 Spectrum-4 将成为非常先进的交换机。
Spectrum-4 可在所有端口之间公平分配带宽,并提供自适应路由和拥塞控制功能,能显著提升数据中心的整体吞吐量。

凭借 ConnectX-7 和 BlueField-3 适配器以及 DOCA 数据中心基础架构软件,它们将组成世界上首个 400 Gbps 端到端网络平台。与典型数据中心数毫秒的抖动相比,Spectrum-4 可以实现纳秒级计时精度 – 即 5 到 6 个数量级的改进。
超大规模计算将享受到更高的吞吐量、更好的服务质量和更高的安全性,同时能降低功耗和成本。Spectrum-4 催生了一种新型计算机,用于在云和边缘数据中心支持 Omniverse 数字孪生。
NVIDIA Spectrum-4 是世界领先的以太网网络平台,也是 Omniverse 计算机的骨干网络。
样机将在第 4 季度末发布。
Omniverse 是一个连接虚拟世界的“网络中的网络”,当不同的生态系统通过 Omniverse 连接成一个统一的工作流程时,这张网络的价值就会放大。
自去年举行 GTC 以来,我们的连接软件数量从 8 个增加到 82 个,与我们连接的包括:Chaos Vray、Autodesk Arnold 和 Blender以及 Adobe 的 3D Substance Painter、Epic 的虚幻引擎 5 和 Maxon 的 Cinema 4D。
许多开发者希望 OEM 将 Omniverse 直接连接到他们的软件套件。Bentley Systems 是先进的基础架构设计、施工和管理平台。他们将 Omniverse 集成到他们的 LumenRT 平台中,对大型基础架构数字孪生进行交互式、工程级、精确到毫米级的 4D 可视化。
Bentley 现已推出集成了 Omniverse 的 LumenRT。
我们将在 GTC 上发布一个主要版本:
- 用于构建 Omniverse 扩展程序、应用和微服务的 Omniverse Kit
- 我们将发布 26 个制造业行业的格式转换器,以将工业工作流程连接到 Omniverse
- DeepSearch 是一个 AI 搜索引擎,可使用自然语言或图像来搜索未标记的大型 3D 素材库
- Omniverse Replicator 框架用于生成物理属性准确的合成数据,以训练和测试 AI 模型
- Omnigraph 是多 GPU、多节点的计算引擎,用于运行数据中心级 Omniverse 应用
- Omniverse Avatar 是一个非常大型的项目,提供用于构建虚拟形象或数字人的框架
Toy Jensen
让我欢迎 Toy Jensen 归来,这是我们用 Omniverse Avatar 构建的应用。请注意,Toy Jensen 并非录像。他是完全实时的,他能进行眼神交流和对话,而且完全动画化。
TJ 互动
嘿,TJ!我想问你几个问题 好的!有问必答 什么是合成生物学? 合成生物学是指在多个层级设计生物系统,包括单个分子、整个细胞甚至是组织和器官等多细胞组合,以执行特定功能,它也被称为 SynBio,代表“合成生命” 能否举几个例子? 合成生物学目前的一些用途包括制作生物燃料;研制具有天然生物体所没有的实用特性的细菌;开发能够检测环境细菌的生物传感器;生产生物制药;通过发酵(而不是石油化工)制造化学品。 在医疗领域有哪些应用? 合成生物学在医学领域应用广泛。例如,合成生物学用于研发新疫苗、新抗生素和癌症新疗法。 TJ,这真的太棒了!能否说说你是如何制作出来的? Avatar 是一个基于 Omniverse 平台构建的框架,使用此框架,您可以快速构建和部署像我一样的虚拟形象,以用于各种用途。首先从我的声音开始。它完全由 Riva 的文本转语音 RADTTS 合成,而且可用于通过 Omniverse Audio2Face 驱动我的面部动画。接下来,Omniverse 动画的动画图形用于定义并控制我的动作,包括手和手臂的动作,以及细微的头部和身体运动。NVIDIA 的开源材质定义语言 (MDL) 可增加触感,让我炫酷的夹克看起来就像合成皮革,而不仅仅是塑料,而 RTX 渲染器能实时以高保真度呈现我的形象。最后,得益于 Riva 中的最新对话式 AI 技术和 Megatron 530B NLP 模型(我们训练过的最大语言模型之一),我可以听你讲,也可以跟你聊天。Megatron 帮我回答了 Jensen 问我的所有难题。同样令人兴奋的是,我可以从云、数据中心或其他任何分解系统运行,这都要归功于 Tokkio。 Tokkio 是一款使用 Omniverse Avatar 构建的应用,它将客户服务 AI 引入零售店、快餐餐厅,甚至网络。它使用计算机视觉、Riva 语音 AI 和 NVIDIA NeMO 等 NVIDIA AI 模型和技术打造而成。而且,由于 Tokkio 在我们的统一计算框架(或 UCF)上运行,因此可以从云端横向扩展,当客户需要像我一样实用的虚拟形象时,满足他们的需求,并且 Tokkio 具有非常敏锐且响应灵敏的感知力,最重要的是,非常自然。下面请大家欣赏关于我的制作过程的简短视频。黄先生,您继续!
DRIVE
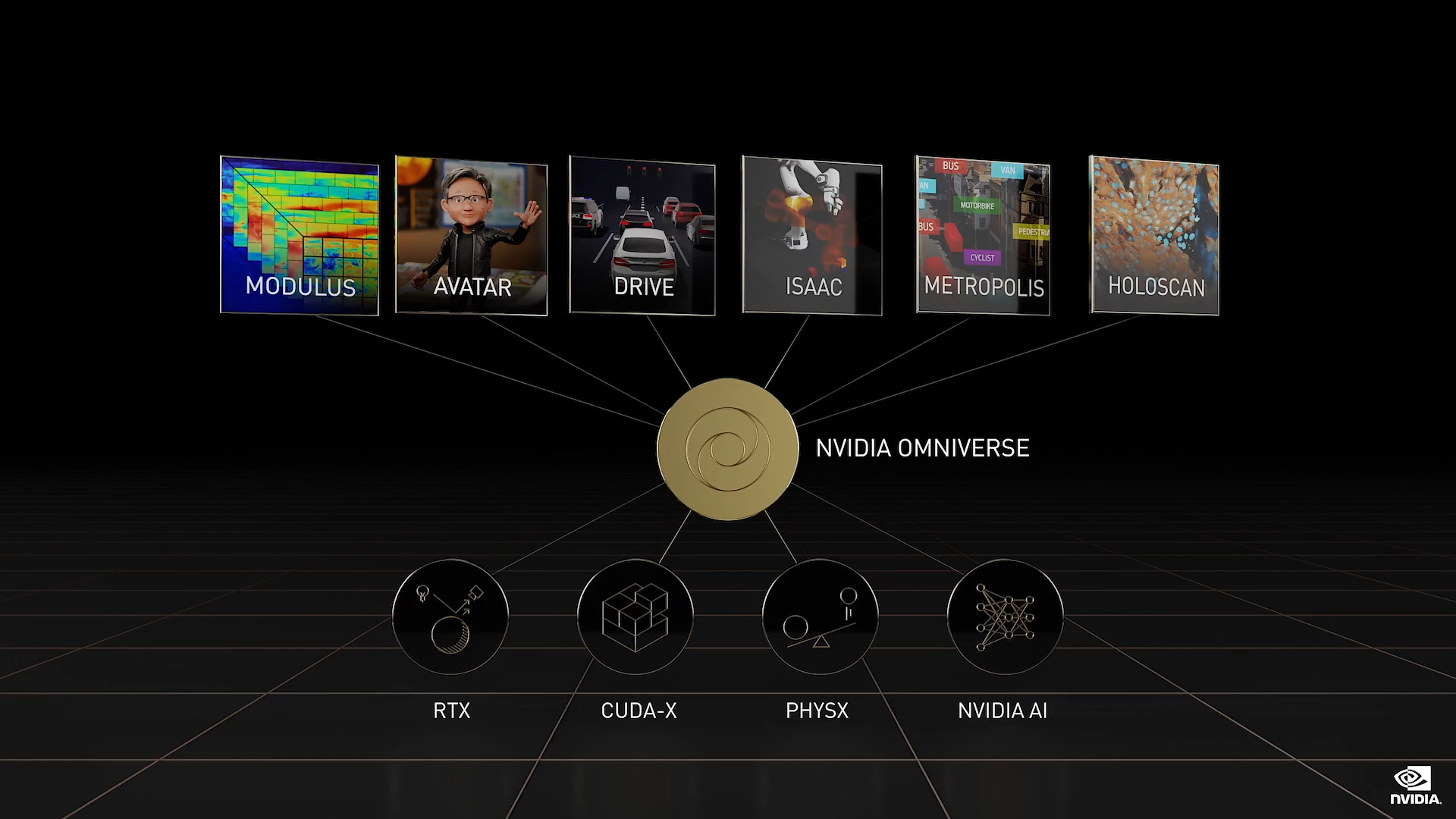
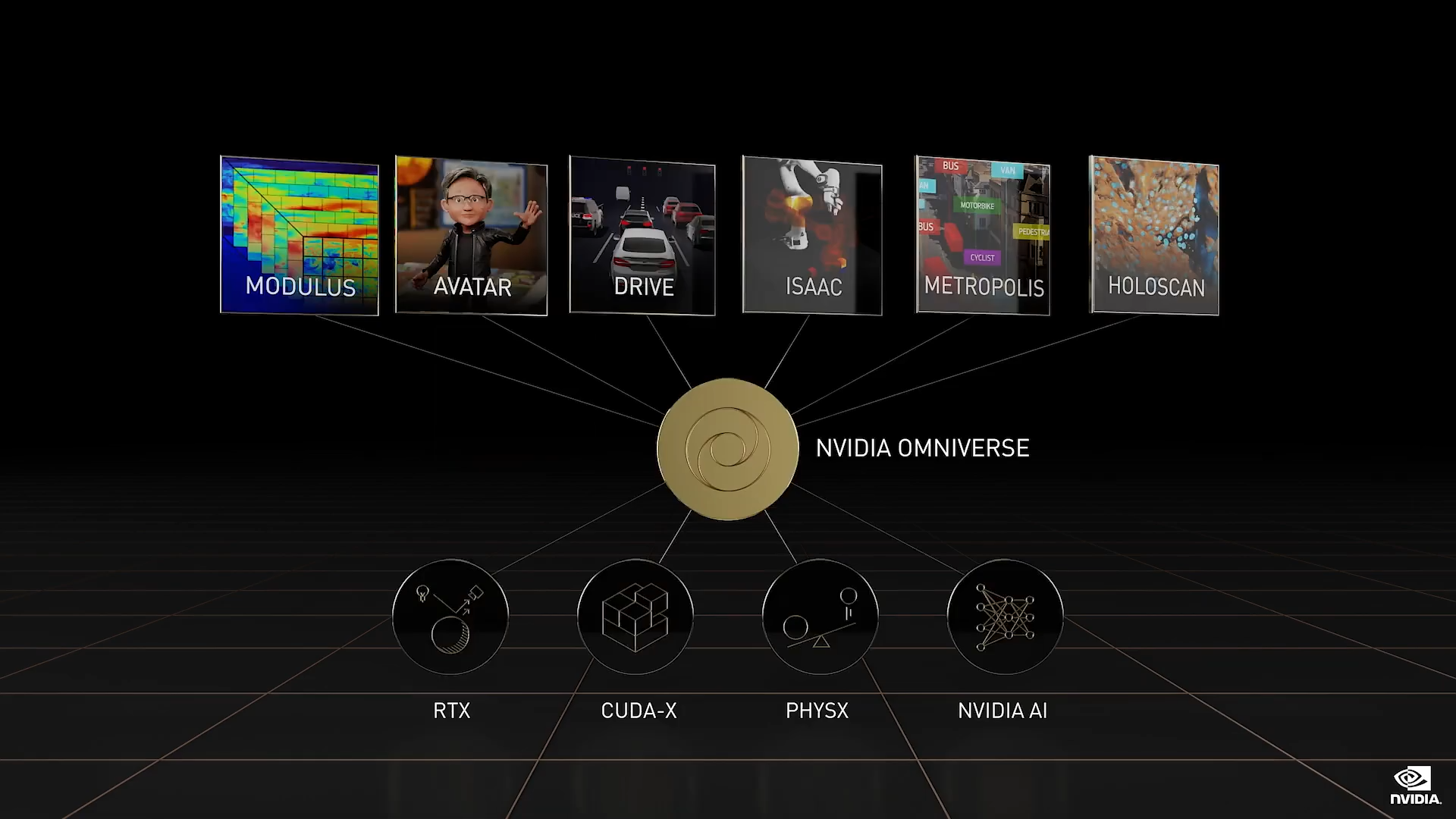
如今的 AI 以感知和模式识别为中心,例如图像识别、语音理解、推荐视频节目或商品。 下一波 AI 浪潮是机器人,AI 也有相应的计划和行动。NVIDIA 正在构建多个机器人平台
- 用于自动驾驶汽车的 DRIVE
- 用于操纵和控制系统的 Isaac
- 用于自主式基础架构的 Metropolis
- 用于机器人医疗器械的 Holoscan
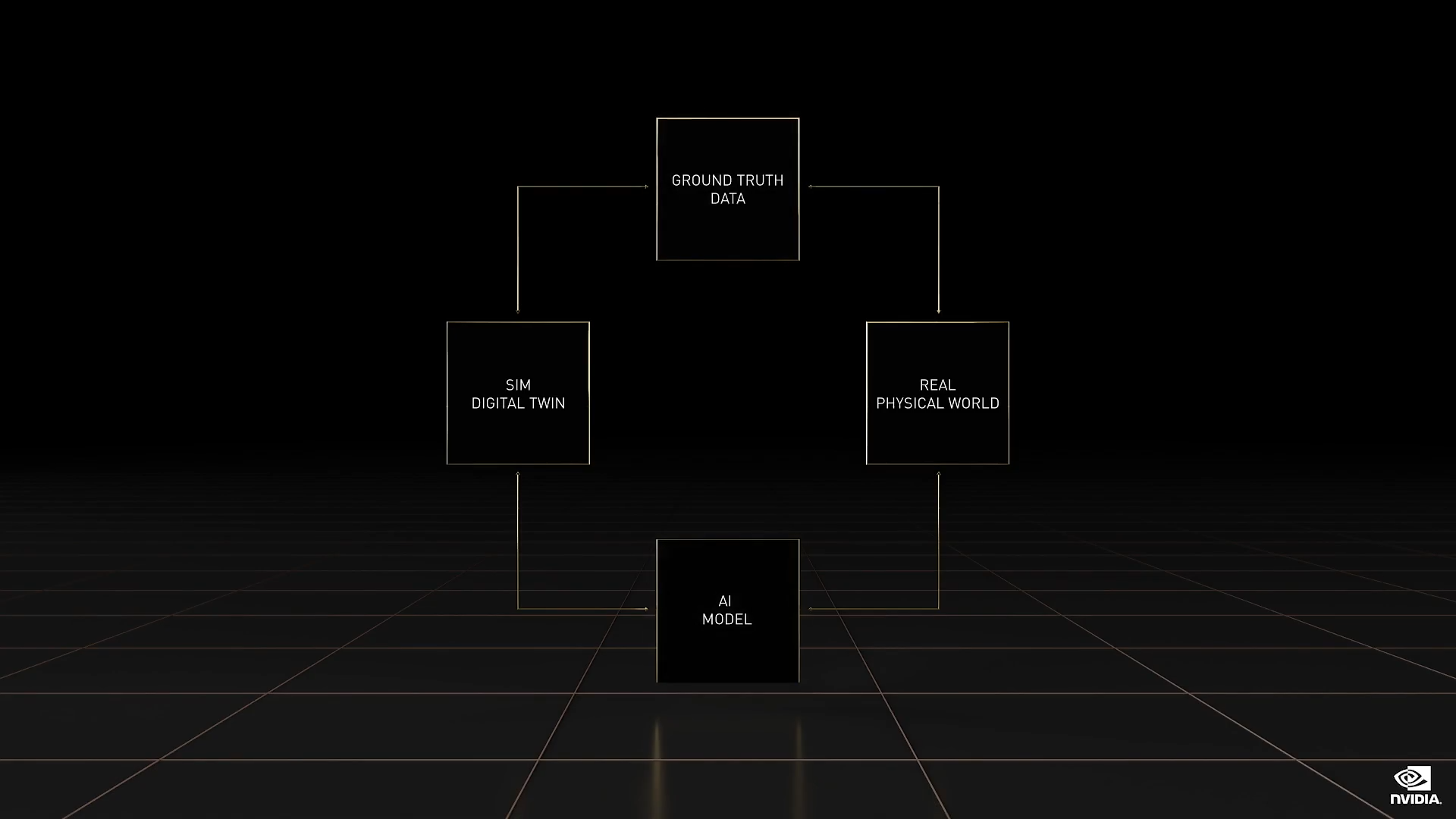
正如 NASA 认识到的,我们需要数字孪生来操作远处的机器人舰队。机器人系统的工作流程很复杂。我将它简化为四个支柱:
- 收集和生成真值数据(Ground Truth Data)
- 创建 AI 模型(AI Model)
- 使用数字孪生进行仿真(Sim Digital Twin)
- 操作机器人(Real Physical World)
Omniverse 是整个工作流程的核心。

DRIVE 是我们的自动驾驶汽车系统,本质上是 AI 司机。与我们所有的平台一样,NVIDIA DRIVE 是全栈的端到端平台,并且对开发者开放,让他们既可使用整个平台,也可使用其中的一部分。
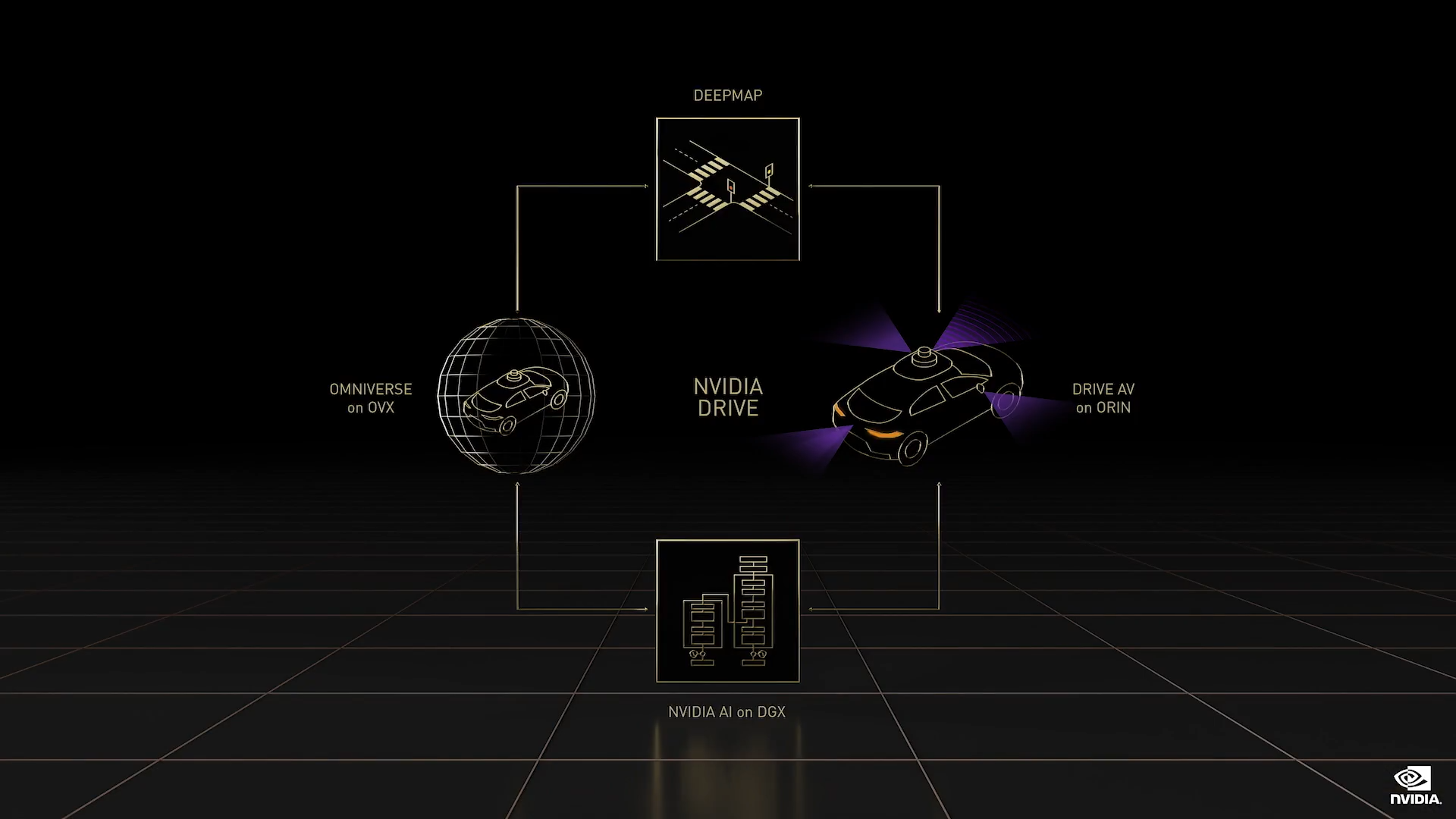
- 对于真值数据,我们使用 DeepMap 高精地图、人工标记数据和 Omniverse Replicator
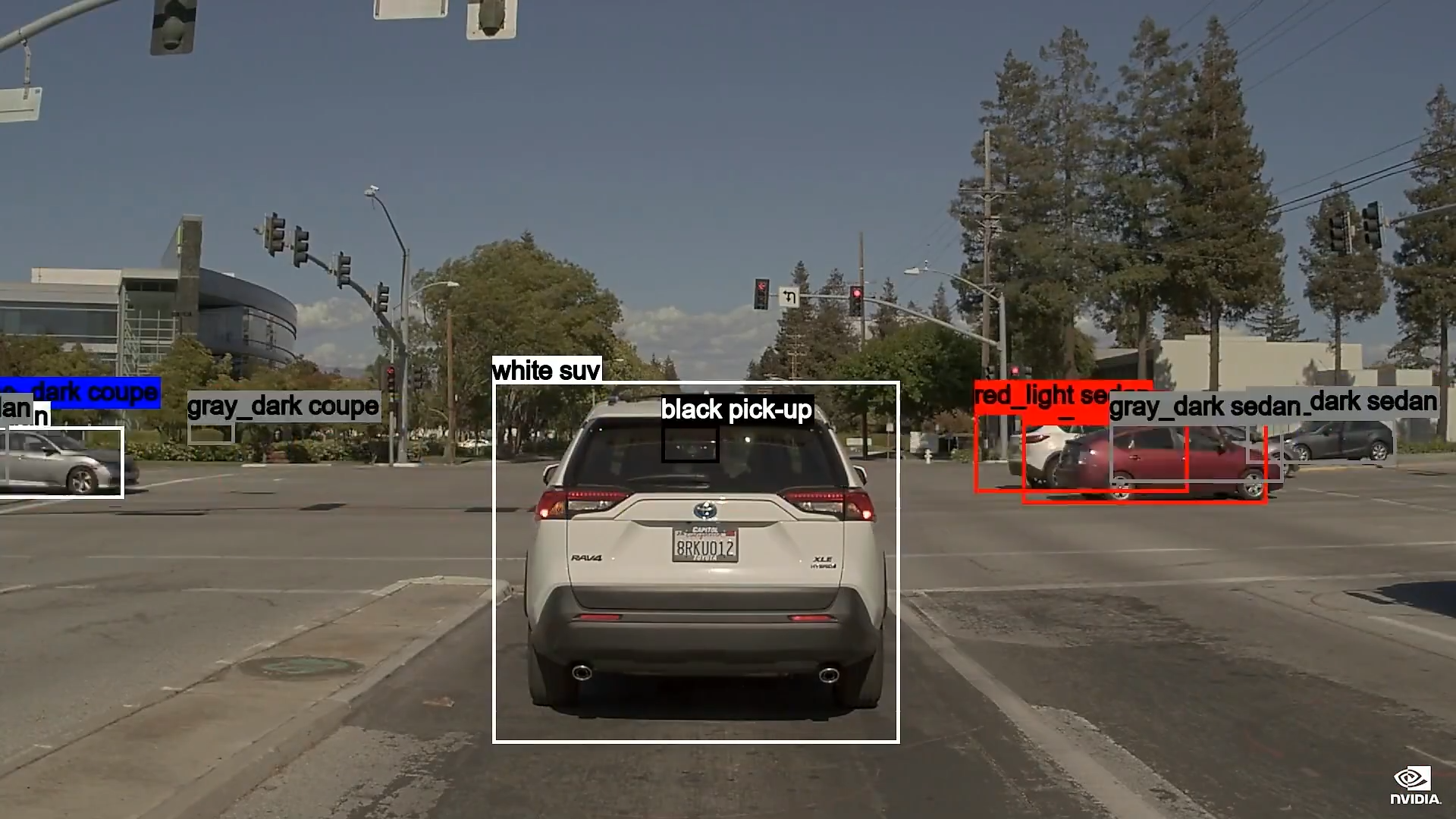

- 为了训练 AI 模型,我们使用 NVIDIA AI 和 DGX
- Omniverse 中的 DRIVE Sim 在 OVX 上运行,是数字孪生
- DRIVE AV 是一款运行在车载 Orin 计算平台上的自动驾驶应用
让我们通过最新版 NVIDIA Drive 来享受驾驶吧。我们将带您沿着圣何塞的高速公路和市区路线行驶。

您可以在可信度渲染视图中看到汽车看见的场景。

我们将在复杂场景中驾驶,例如拥挤的交叉路口。
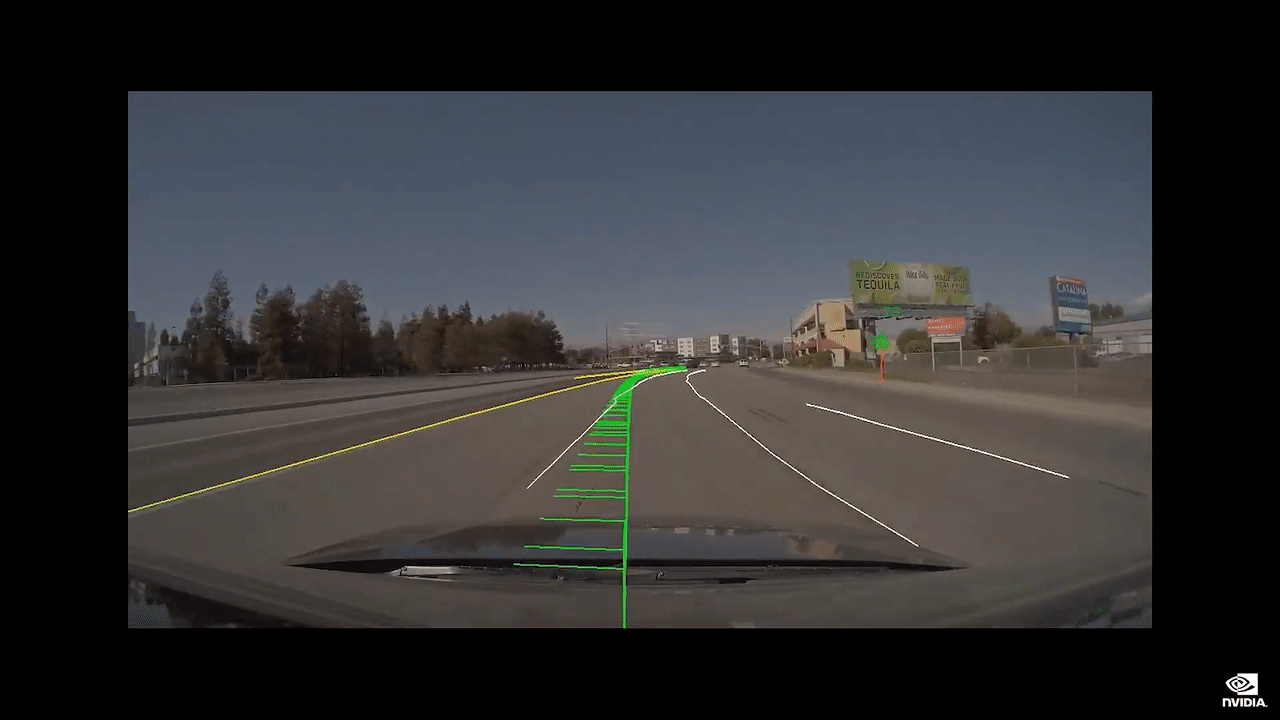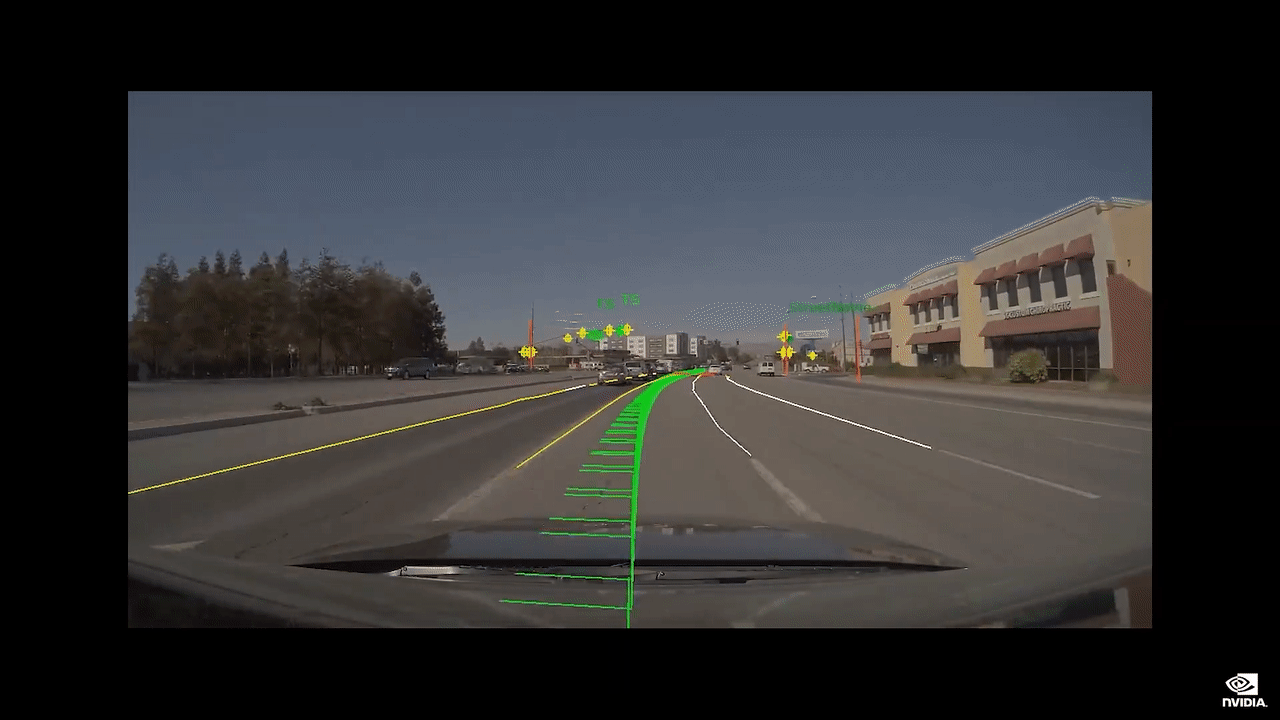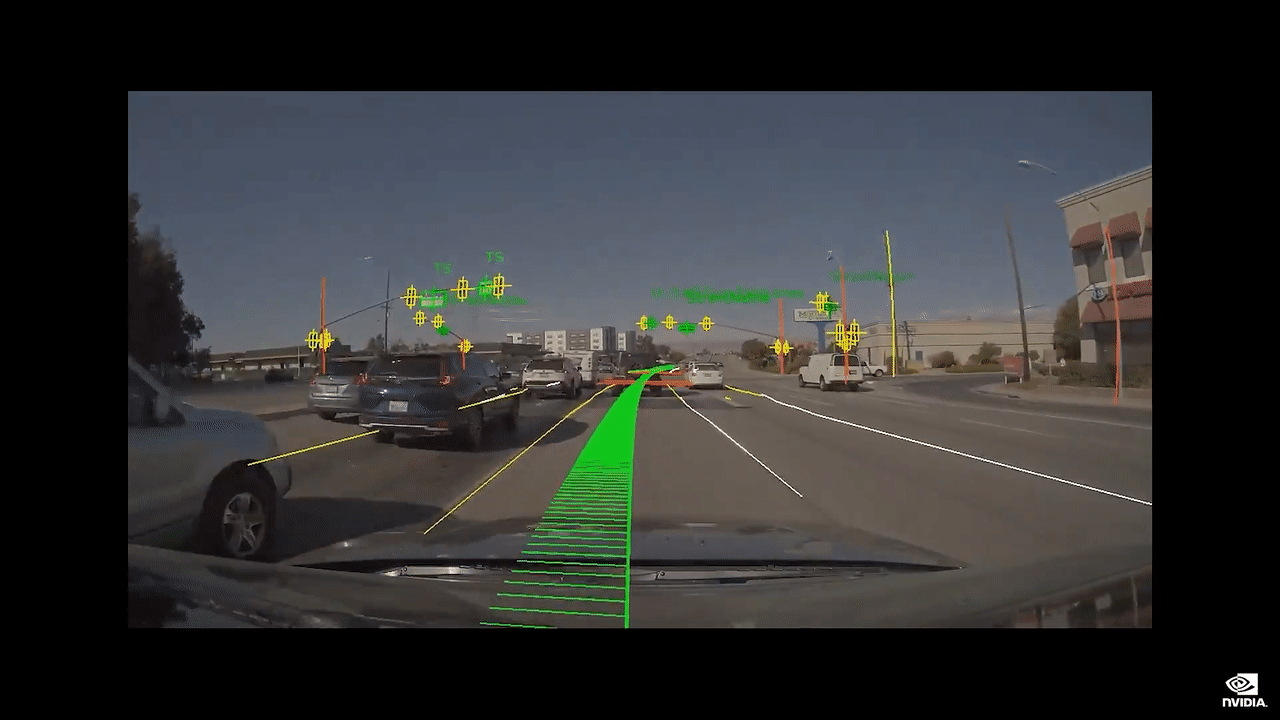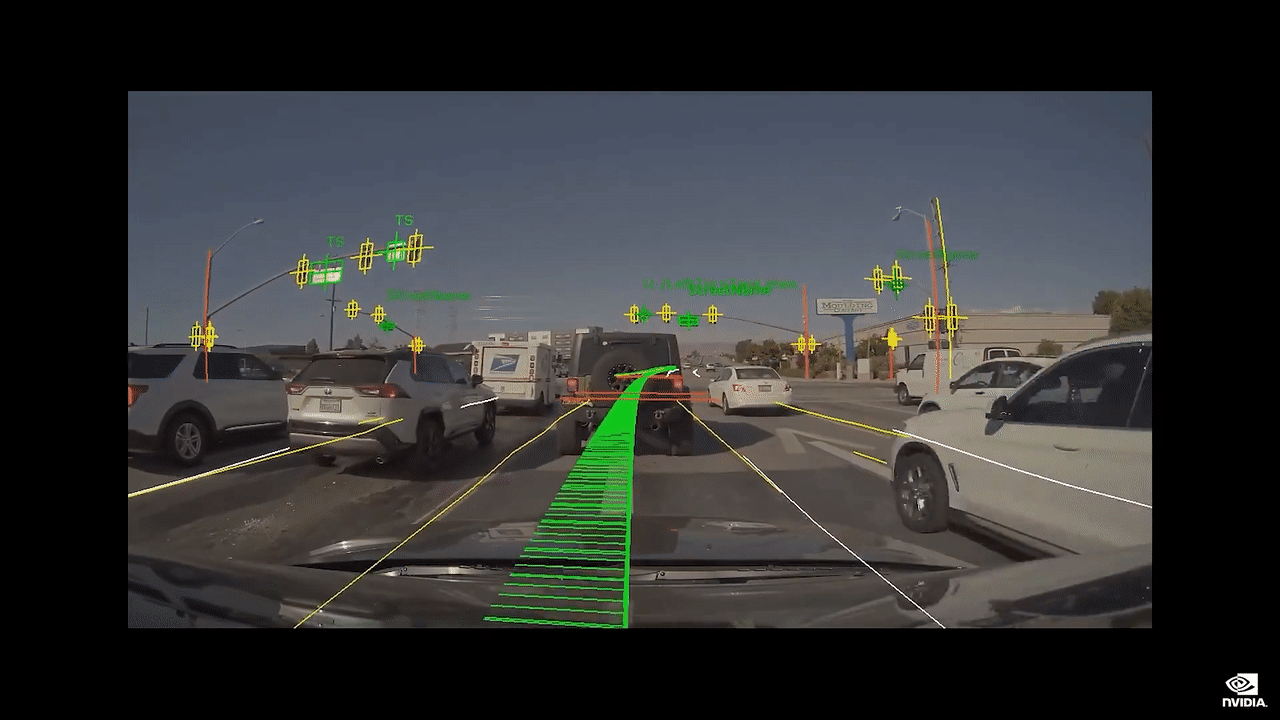
AI 司机将会是您友善的驾驶伙伴
DRIVE 演示
欢迎 Daniel。我看到 Hubert 发来一条短信。 “你能在圣何塞市中心接我吗?” 要我带您去吗? 是的,谢谢。 好的,带您去圣何塞市中心。 启动 DRIVE Pilot。 好的,启动 DRIVE Pilot。 能否告诉 Hubert 我们已在路上? 当然,我会给他发条短信。 我看到 Hubert 了。 能带我去 Rivermark Hotel 吗? 好的,带您去 Rivermark Hotel。 谢谢你来接我! 好的。启动 DRIVE Pilot。 好的,启动 DRIVE Pilot。 那里是什么建筑? 那是圣何塞表演艺术中心。 那里在上演什么节目? 今晚演出的节目是《猫》。 可以给我买两张星期六晚上的票吗? 好的。 您已抵达目的地。 请停车。 好的,找到停车位。
Hyperion
Hyperion 8 是我们自动驾驶汽车的硬件架构,同时它也是整个 DRIVE 平台的构建基础。 它由以下硬件组成:
- 多个传感器、多个网络

- 两台司机自动驾驶计算机
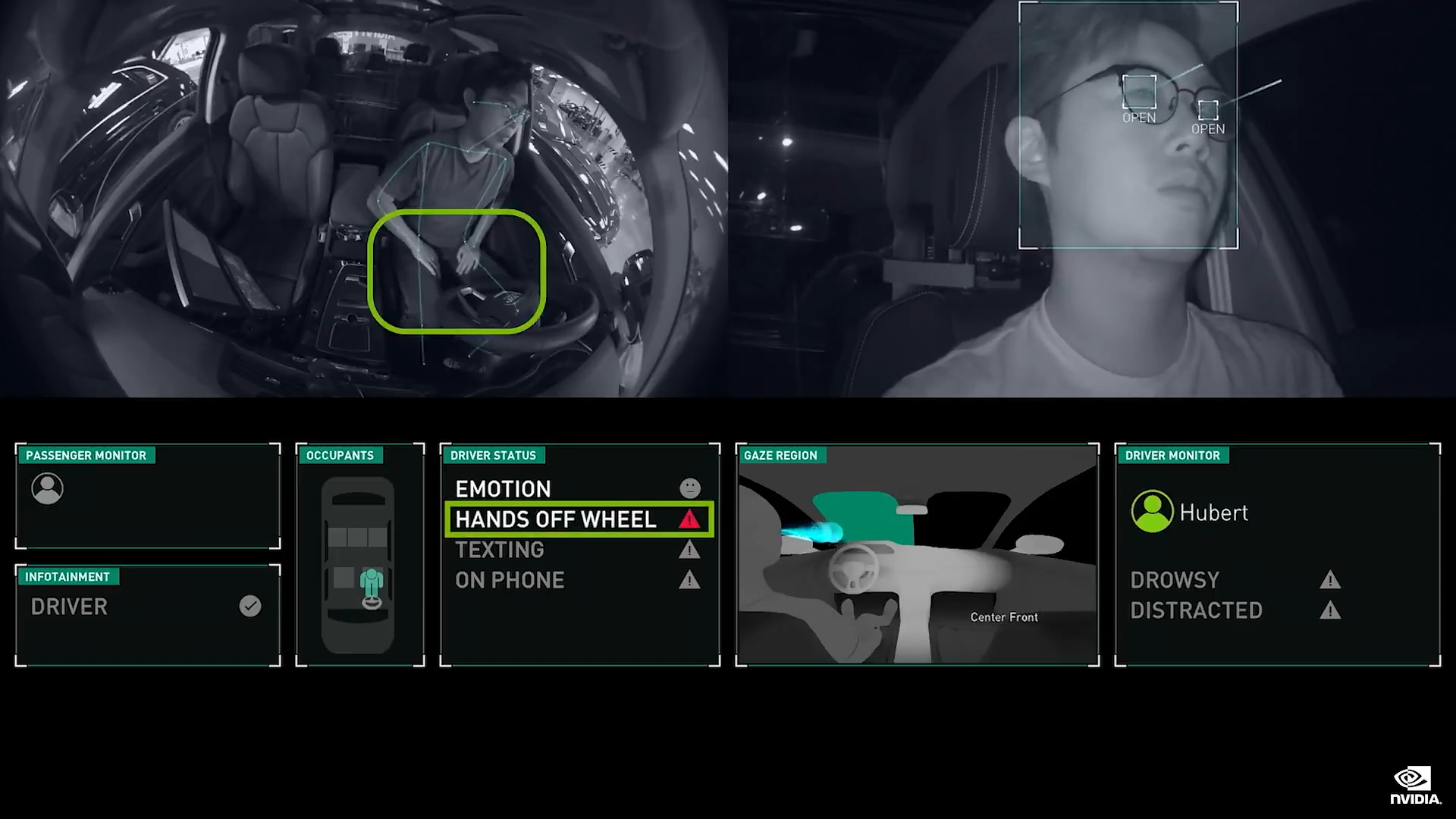
- 一台服务员 AI 计算机

- 一个任务记录器

- 以及安全和网络安全系统
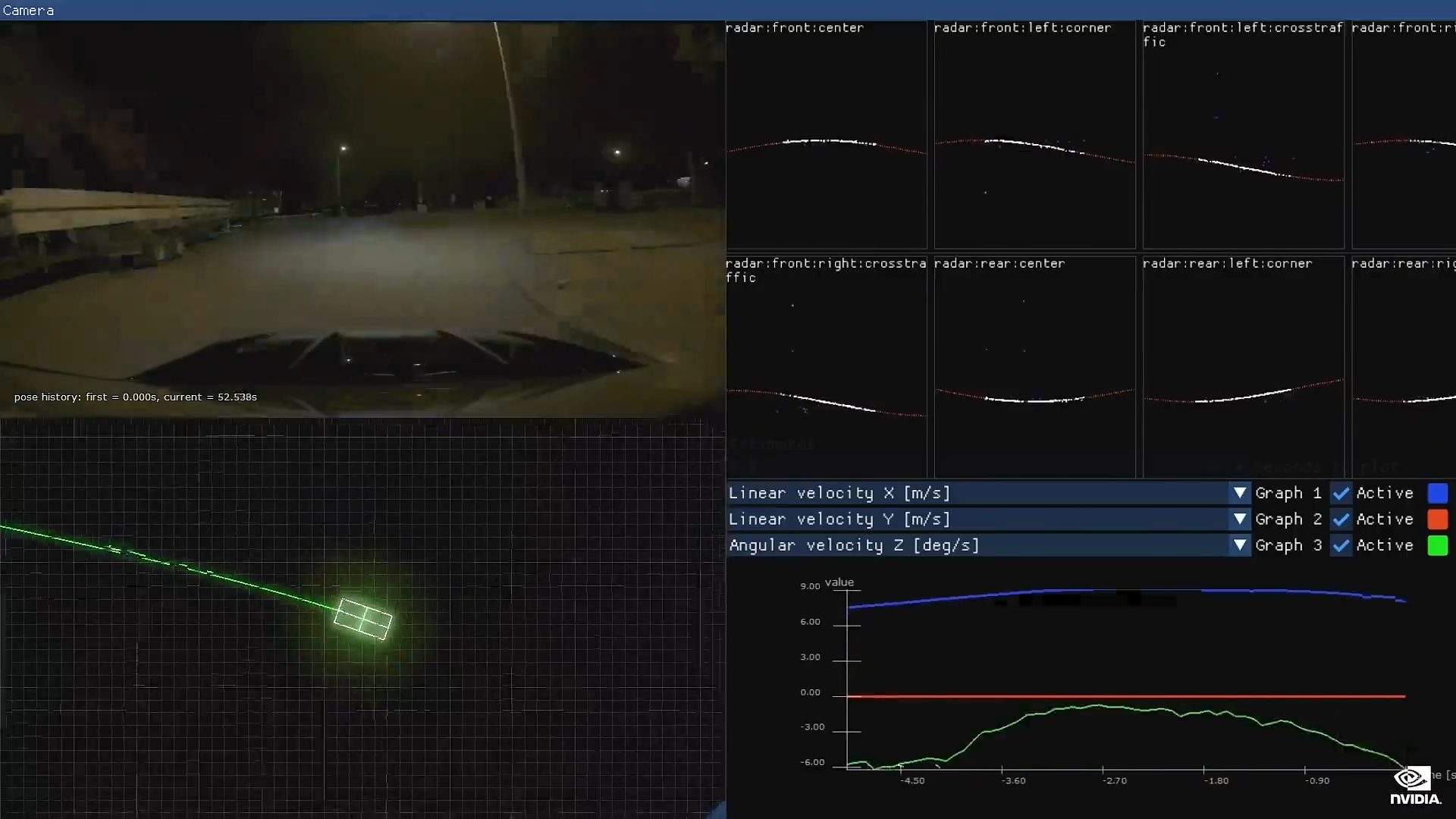
它是开放式架构。 Hyperion 8 可以使用 360 度摄像头、雷达、激光雷达和超声传感器套件实现全自动驾驶。
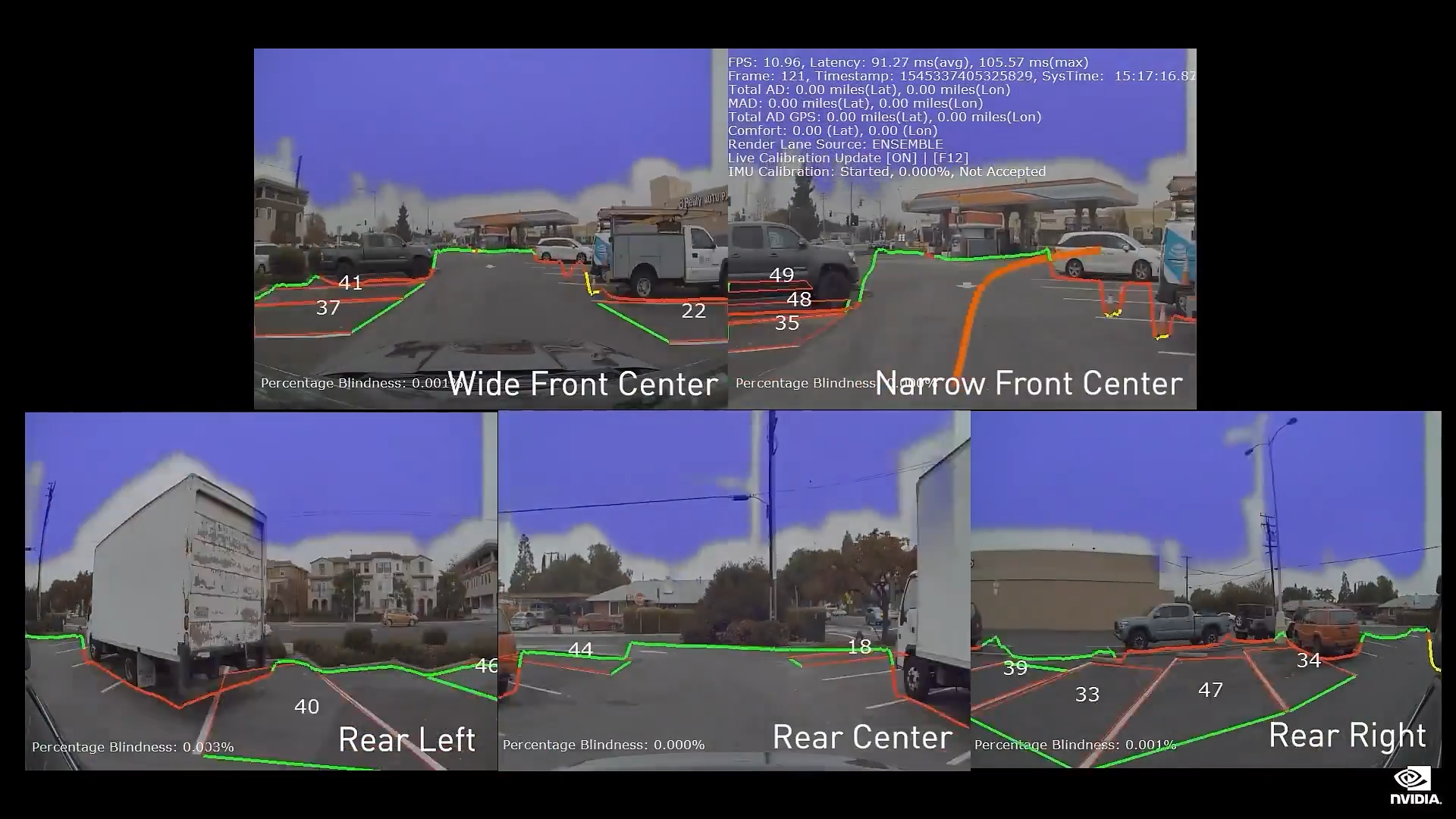


Hyperion 8 将从 2024 年起搭载到梅赛德斯-奔驰汽车中, 然后在 2025 年搭载到捷豹路虎汽车中。
今天,我们宣布 Hyperion 9 将从 2026 年起搭载到汽车中。Hyperion 9 将拥有14 个摄像头、9 个雷达、3 个激光雷达和 20 个超声传感器。总体而言,Hyperion 9 处理的传感器数据量将两倍于 Hyperion 8,从而进一步增强安全性并扩大全自动驾驶的工作领域。

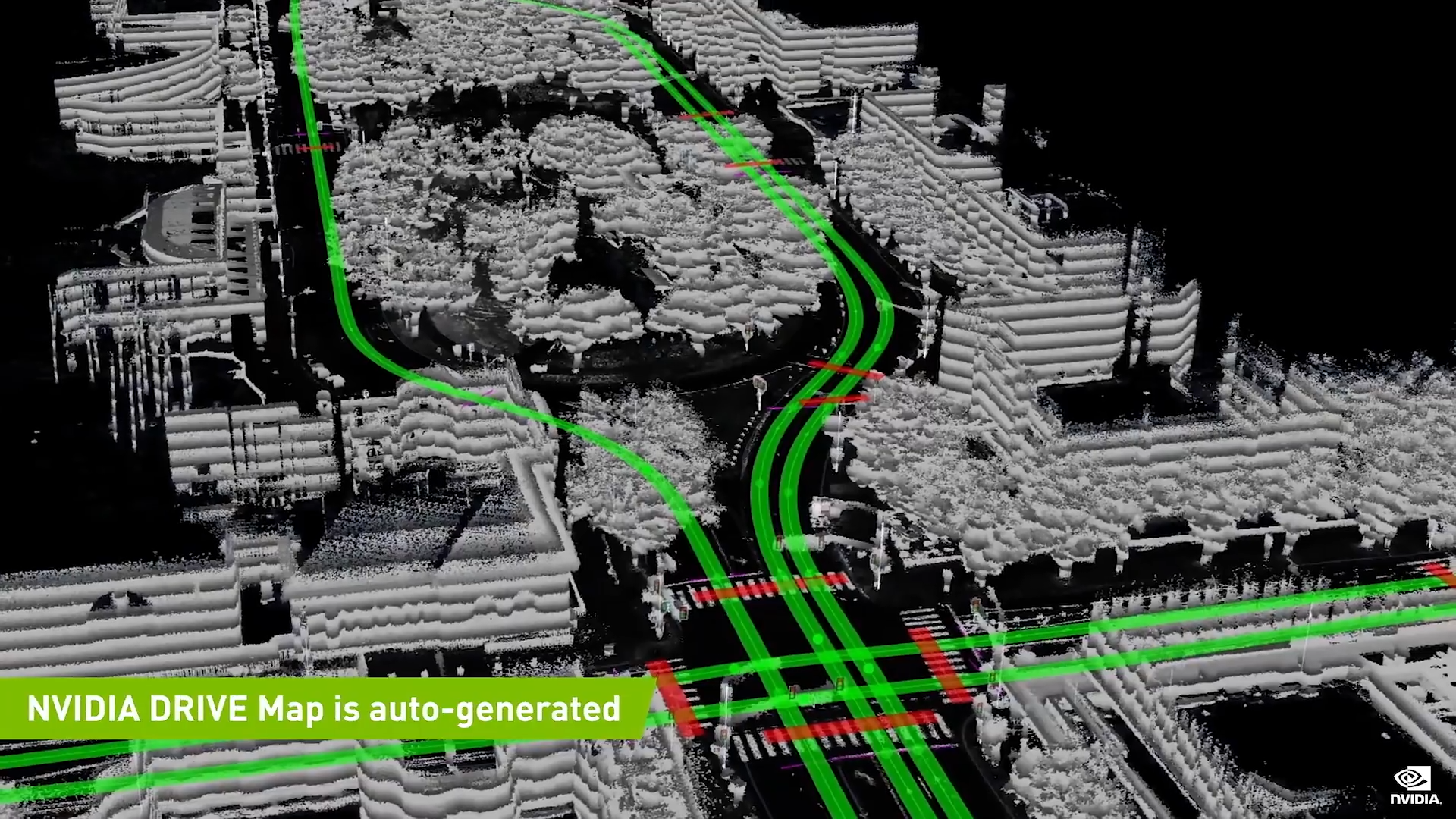
DRIVE MAP
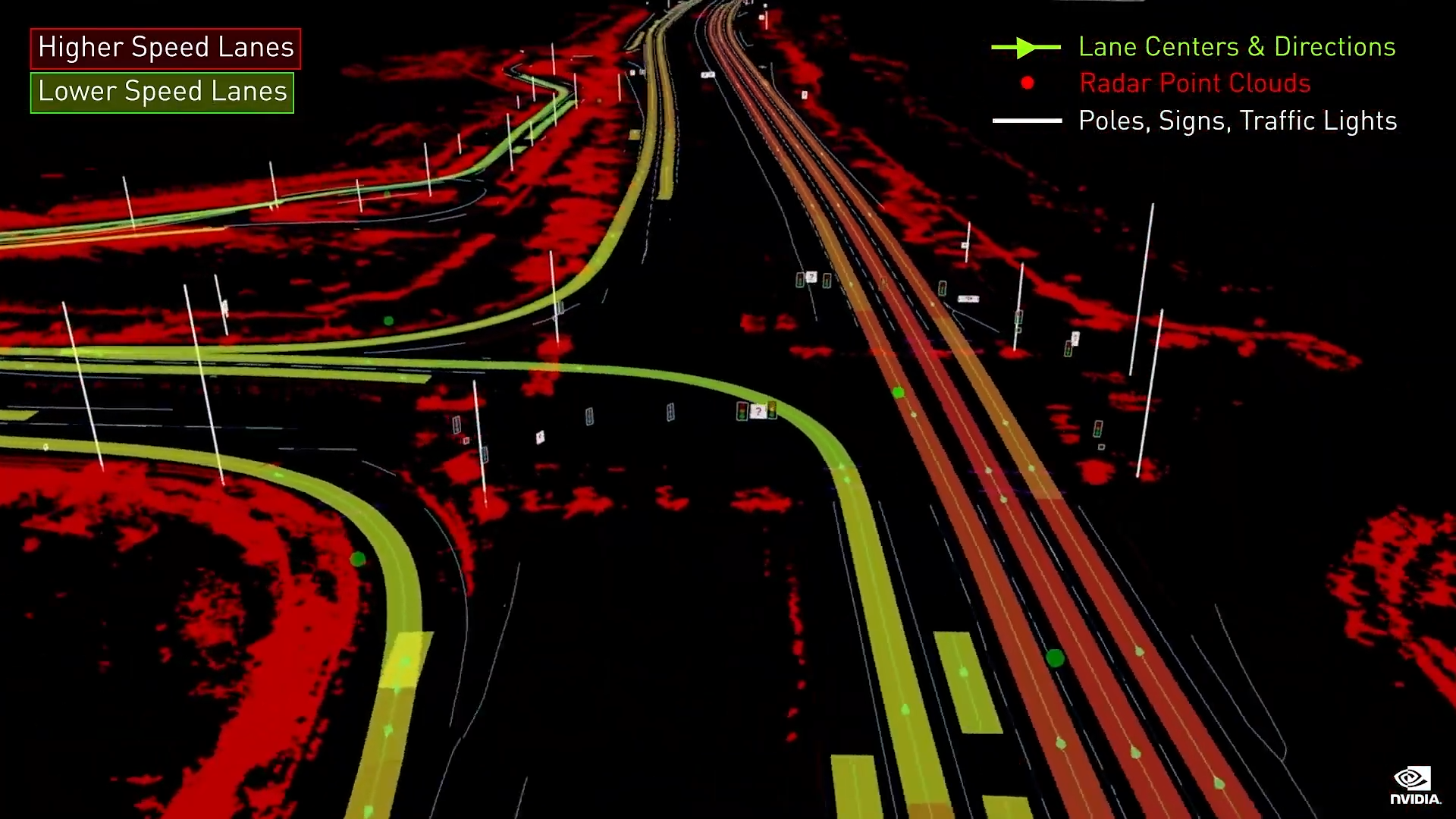
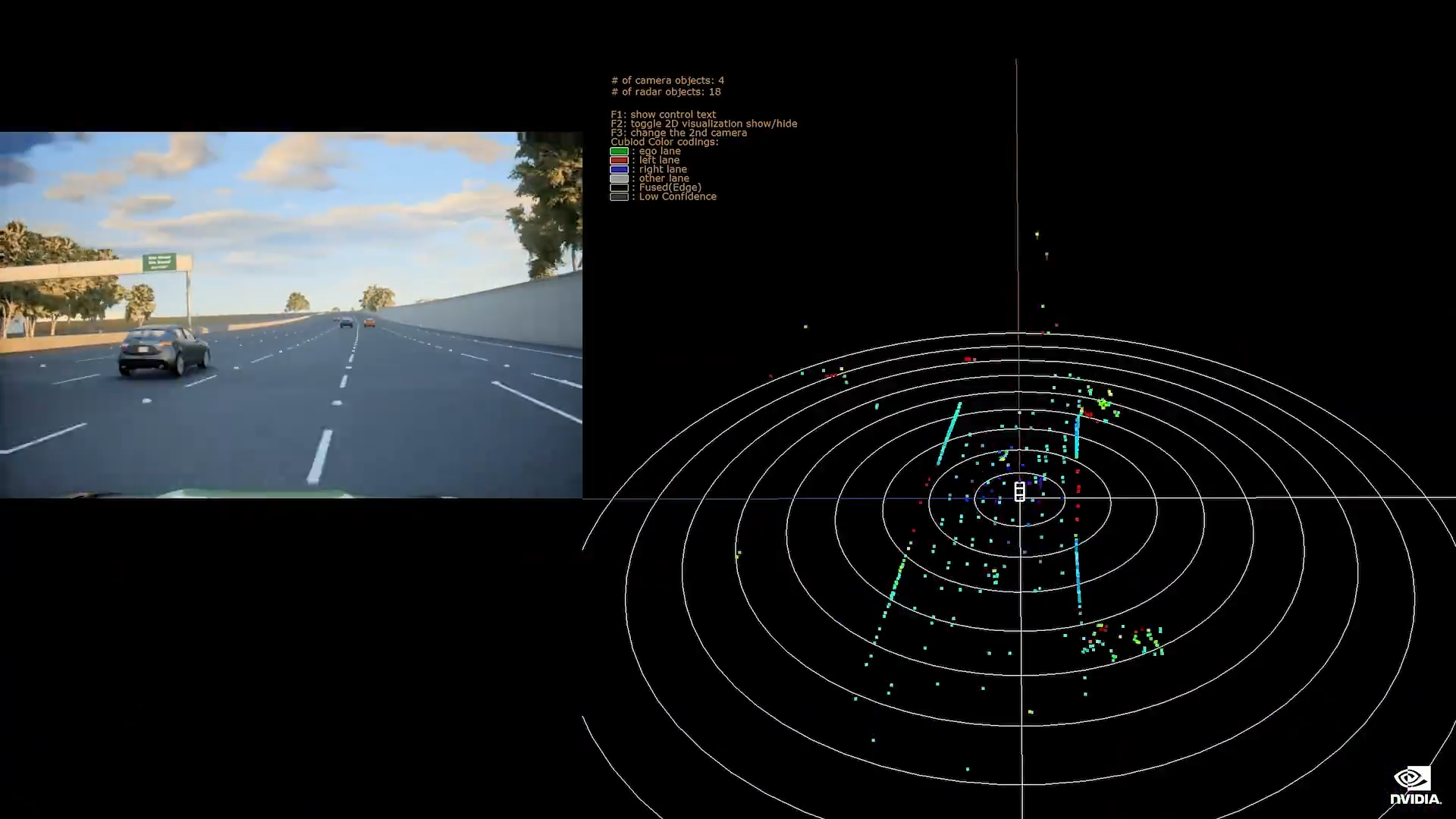
NVIDIA DRIVE Map 是一种多模态地图引擎,包括摄像头、雷达和激光雷达的数据。您可以单独定位到地图的每一层,这将提供多样性和冗余性,以实现最高级别的安全性。

Drive Map 有两个地图引擎:
真值测绘地图
 和众包车队地图
和众包车队地图

到 2024 年底,我们预计绘制并创建北美、西欧和亚洲所有主要公路的数字孪生,总长度约为 50 万公里。

数百万辆乘用车将不断扩展和更新该地图。

我们正在构建地球级别的自动驾驶车队数字孪生,以探索新的算法和设计,并在部署到车队之前测试软件。我们正在开发两种场景仿真方法,每种都以不同方式重建整个世界。
- 其中一种方法从 NVIDIA Drive Map 开始。

这种多模态地图引擎可为整个世界创建高度精确的 3D 表现形式。

地图加载到 Omniverse 中,

建筑、植被和其他路边目标均会生成。

系统对之前驾驶过程中遇到的运动目标、汽车和行人进行推理和定位,然后放入数字孪生中。
| Real World | Digital Twin |
|---|---|
 |
 |
我们可以将每个运动目标生成动画,或向其分配 AI 行为模型,还可以应用域随机化来生成多样化且合理的挑战性场景。
| Real World | Digital Twin(Domain Randomization) |
|---|---|
 |
 |
- 第二种方法使用神经图形 AI 和 Omniverse,将预先录制的驾驶视频转换为可回放和可修改的驾驶过程。

我们首先重建 3D 场景。

系统会识别并移除运动的目标,背景被恢复。


重建场景后,我们可以改变现有车辆的行为,或添加可完全控制、在交通环境下真实反应的车辆。

重新生成的驾驶过程,结合 3D 几何图形和基于物理效果的材质,让我们可以为场景重新打光,应用物理效果和仿真激光雷达等传感器。现在,可以重新运行预先录制的场景,并运用于闭环仿真和测试。

DRIVE Map 和 DRIVE Sim 包含 NVIDIA 研究工作取得的突破性 AI 成果,展示了 Omniverse 数字孪生在推动自动驾驶汽车开发方面的力量。

NVIDIA DRIVE Map、DRIVE Sim、搭载 Orin 的 Hyperion 8 和 DRIVE AV 栈既可单独使用,也可作为一个整体使用。
电动汽车已促使业界对汽车架构进行彻底的重新设计。未来的汽车将高度可编程,从内置许多嵌入式控制器发展为高度集中式的计算平台。AI 和自动驾驶功能将在软件中提供,并在汽车生命周期内不断增强。NVIDIA Orin 携手多家公司共同打造这样的未来,已经取得巨大成功。Orin 是理想的集中式自动驾驶和 AI 计算平台,也是新一代电动汽车、无人驾驶出租车、公共汽车和卡车的引擎。Orin 本月开始发售。
今天,我们很高兴地宣布,全球第二大电动汽车制造商比亚迪将为 2023 年上半年开始投产的汽车搭载 DRIVE Orin 计算平台
Holoscan
NVIDIA 自动驾驶车载计算机、软件和机器人 AI 基本上是与新一代医疗系统相同的计算管线。
请允许我为大家展示 Holoscan 可以为一台名为光片显微镜(Lightsheet Microscope)的惊人仪器做些什么。光片显微镜由诺贝尔奖得主 Eric Betzig 发明,可利用高分辨率荧光创建细胞移动和分裂的影片,使得研究人员能够研究运动中的生物学问题在于光片显微镜每小时可产生 3TB 的数据,这相当于 30 部 4K 电影的数据量。处理 3TB 的数据需要长达一天的时间,

借助 NVIDIA Clara Holoscan,我们可以对这些数据进行实时处理。
Clara Holoscan介绍
现在,借助 Clara Holoscan 和 NVIDIA Index,我们可以实时可视化大量活细胞。这些数据是直接从显微镜记录下来的,通过观察这些活的癌细胞的移动情况,我们可以同时看到正常、健康的生物特征及其恶化过程。蓝色荧光标记的细胞核从一个细胞分裂为两个细胞。癌症的一个标志是,与正常的健康细胞相比,细胞分裂更频繁,错误检查更少。加州大学伯克利分校的晶格光片显微镜具有超高分辨率,借此科学家能够发现隐藏在普通光学器件中的东西,这是 使用传统显微镜无法观察到的。当我们放大时,观察到一个对于癌细胞系来说都非常罕见的情况:发现一个细胞分裂成 3 个细胞。 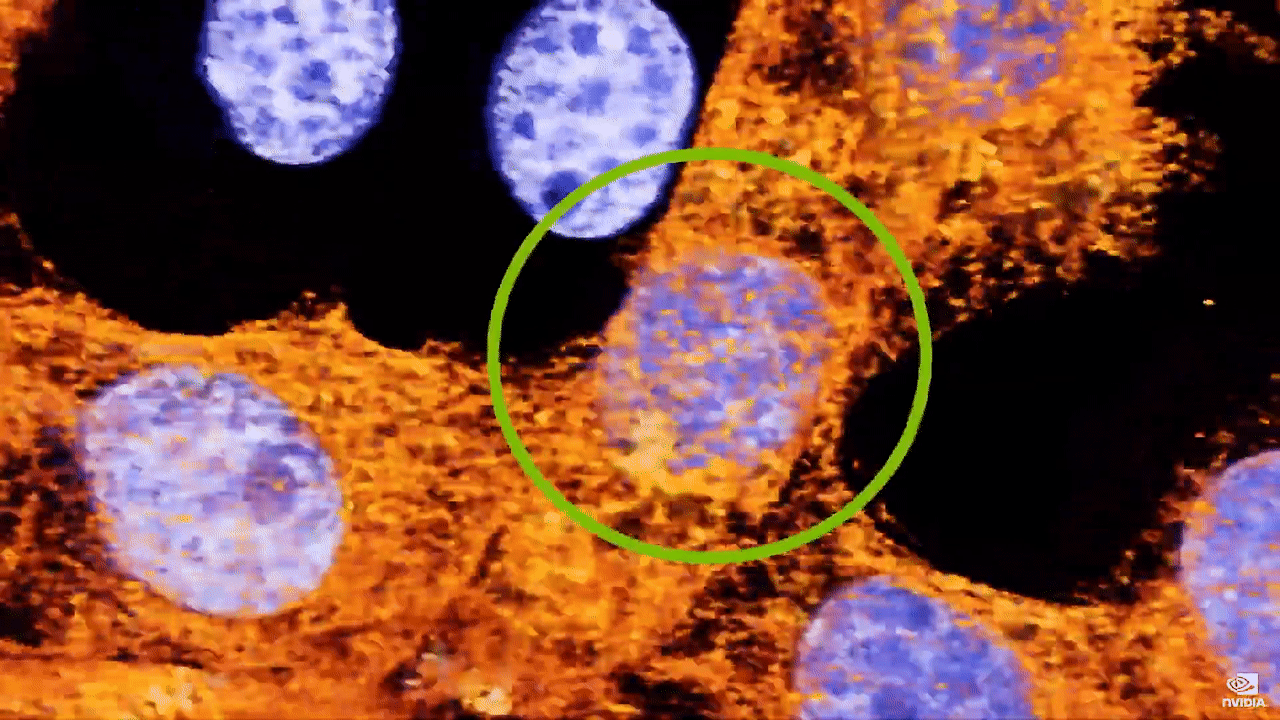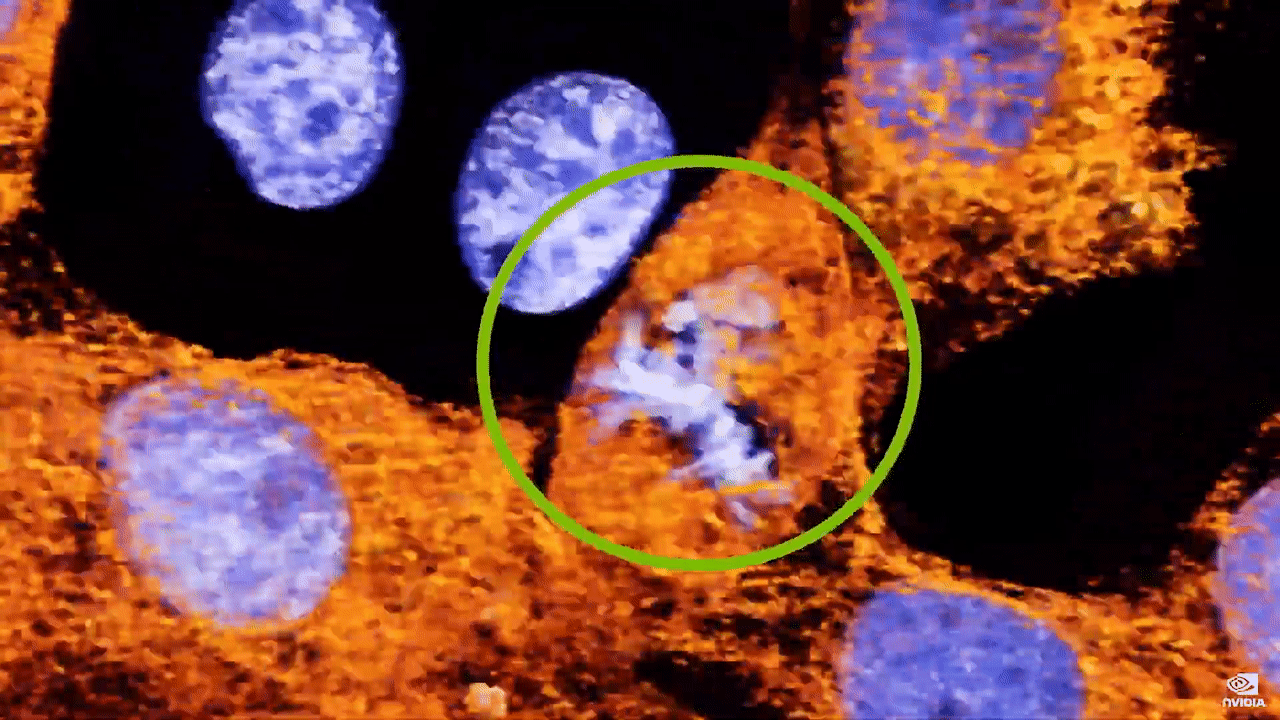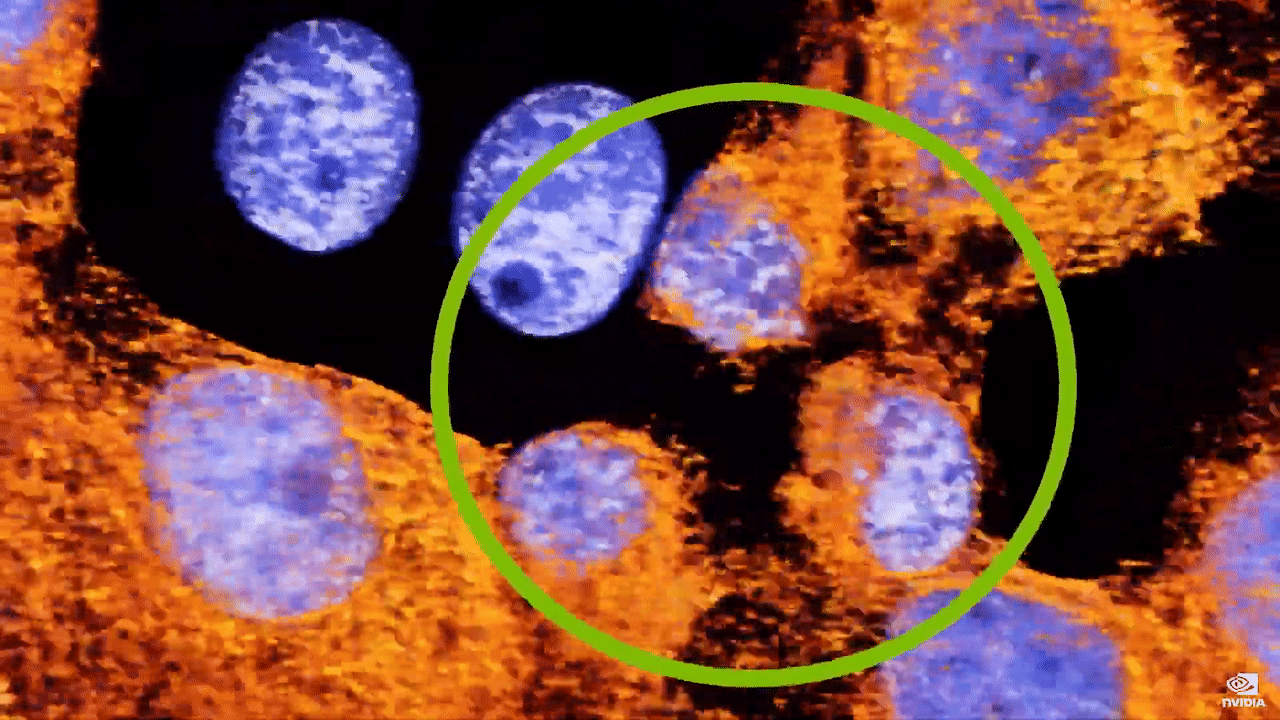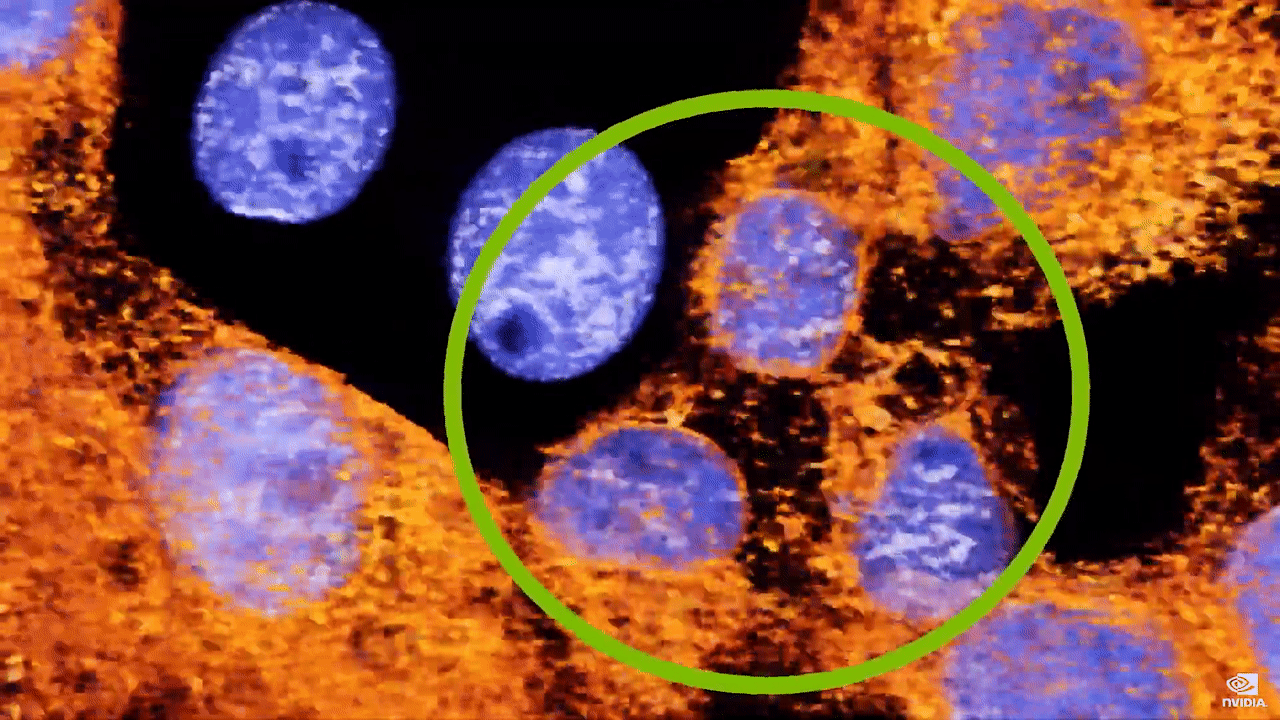 这一现象仅在一些科学出版物中有过零星报道,科学家尚不知道我们将看到什么,但现在借助实时处理和可视化技术,科学界可以发现此类的未见过的事件。 我们来看看未来的发展情况。
Clara Holoscan 是一个开放、可扩展的机器人平台。Clara Holoscan 的设计符合 IEC-62304 医疗级规格,并达到极高的设备安全和保障级别。Holoscan 的计算量惊人。其核心计算机为 Orin 和 ConnectX-7,并可选配 GPU。Holoscan 开发平台目前向早期体验客户开放,正式上市时间为 5 月,并在 2023 年第一季度完成医疗级准备。未来的医疗设备将是 AI 仪器的天下,用于辅助诊断或手术。
正如 NVIDIA DRIVE 是机器人车辆平台一样,Clara Holoscan 也是一个机器人医疗仪器平台。我们很高兴看到业界对 Holoscan 的热情,也很乐于与领先的医疗设备制造商和机器人手术公司合作。
Metropolis
对机器人和自动化的需求正呈指数级增长。一些机器人会移动,而其他机器人则会观察移动的目标。NVIDIA 与数千客户和开发者合作构建机器人,广泛用于制造、零售、医疗健康、农业、建筑、机场和整个城市。
NVIDIA 的机器人平台由 Metropolis 和 Isaac 组成:Isaac 是一个为移动机器打造的平台;Metropolis 是一个跟踪移动目标的静止机器人。
Metropolis 和 Isaac 平台(如同 DRIVE)包含 4 大核心:
- 真值生成
- AI 模型训练
- Omniverse 数字孪生
- 配备了软件和计算机的机器人
Metropolis 已经取得了非凡的成绩:下载量达 30 万次,拥有 1000 多个生态系统合作伙伴,并在超过 100 万个设施中运营,其中包括 USPS、沃尔玛超市、特拉维夫和伦敦等城市、希思罗机场、Veolia 回收工厂和吉列橄榄球场。
现在,客户可以使用 Omniverse 创建其架构的数字孪生,以提升安全性和效率。
我们来看看百事公司是如何使用 Metropolis 和 Omniverse 的
百事介绍
百事的产品每天在全球有超过 10 亿次的消费,将如此多的产品分销至 200 多个区域市场需要 600 多个配送中心,提高供应链效率和环境可持续性是百事一直以来的重要目标。 为实现这一目标,他们采用 NVIDIA Omniverse 和 Metropolis 构建数字孪生,模拟包装和配送中心,这样他们能够在进行实物投资之前测试布局变化,优化工作流程以加速吞吐量。 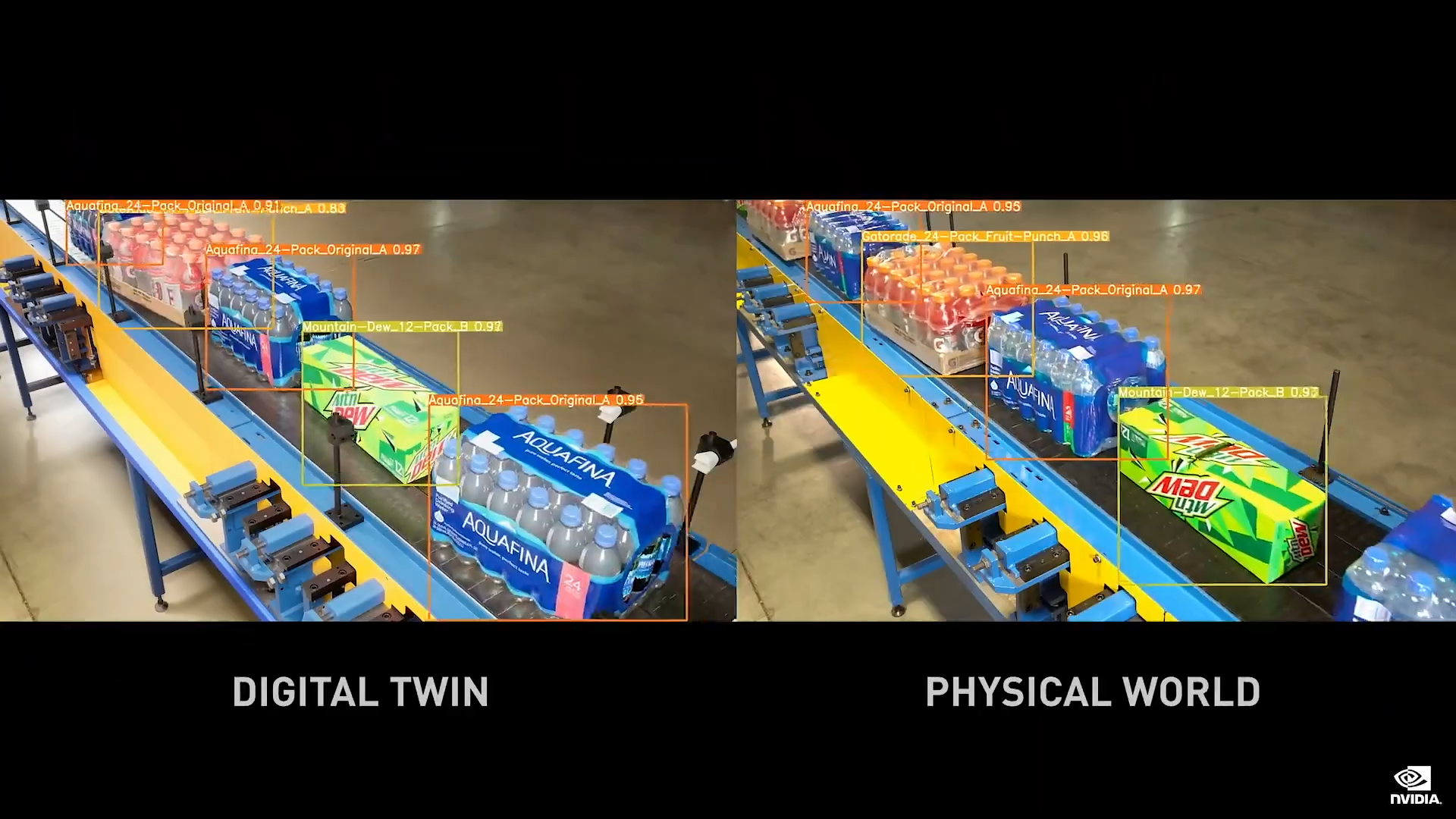 随着新产品和流程的推出,可以使用 Omniverse Replicator 和 NVIDIA TAO创建逼真的合成数据,然后重新训练实时 AI 模型。这些新模型和优化被转移到现实世界,通过 NVIDIA Metropolis 应用(使用 AI 计算机视觉)实时监控和优化传送带速度,防止在长达数英里的传送带上发生堵塞和宕机。  此外,借助 NVIDIA Fleet Command,所有这些应用均可从一个集中式控制平面,安全部署于数百个配送中心并进行管理。 通过利用 NVIDIA Omniverse、Metropolis 和 Fleet Command,百事公司正在简化供应链运营,减少能源消耗和浪费,并推动可持续发展的使命。
Issac
机器人发展最快的领域之一是自主移动机器人 (AMR),本质上是室内的无人驾驶车,速度较低,但环境高度非结构化。目前有数千万个工厂、商店和餐厅,以及面积达数亿平方英尺的仓储和运营中心。
今天,我们将发布 Isaac 的一个重要版本,即 Isaac for AMR
我将着重介绍一下该版本的一些关键点
与 DRIVE 平台一样,Isaac for AMR 也有四大核心,每个都单独可用,并且完全开放
- 用于真值生成的新 NVIDIA DeepMap
- 用于训练模型的 NVIDIA AI、
- 搭载 Orin 的 AMR 机器人参考设计
- Isaac 机器人技术堆栈中的新 Gem
- 基于 Omniverse 的新版 Isaac Sim.
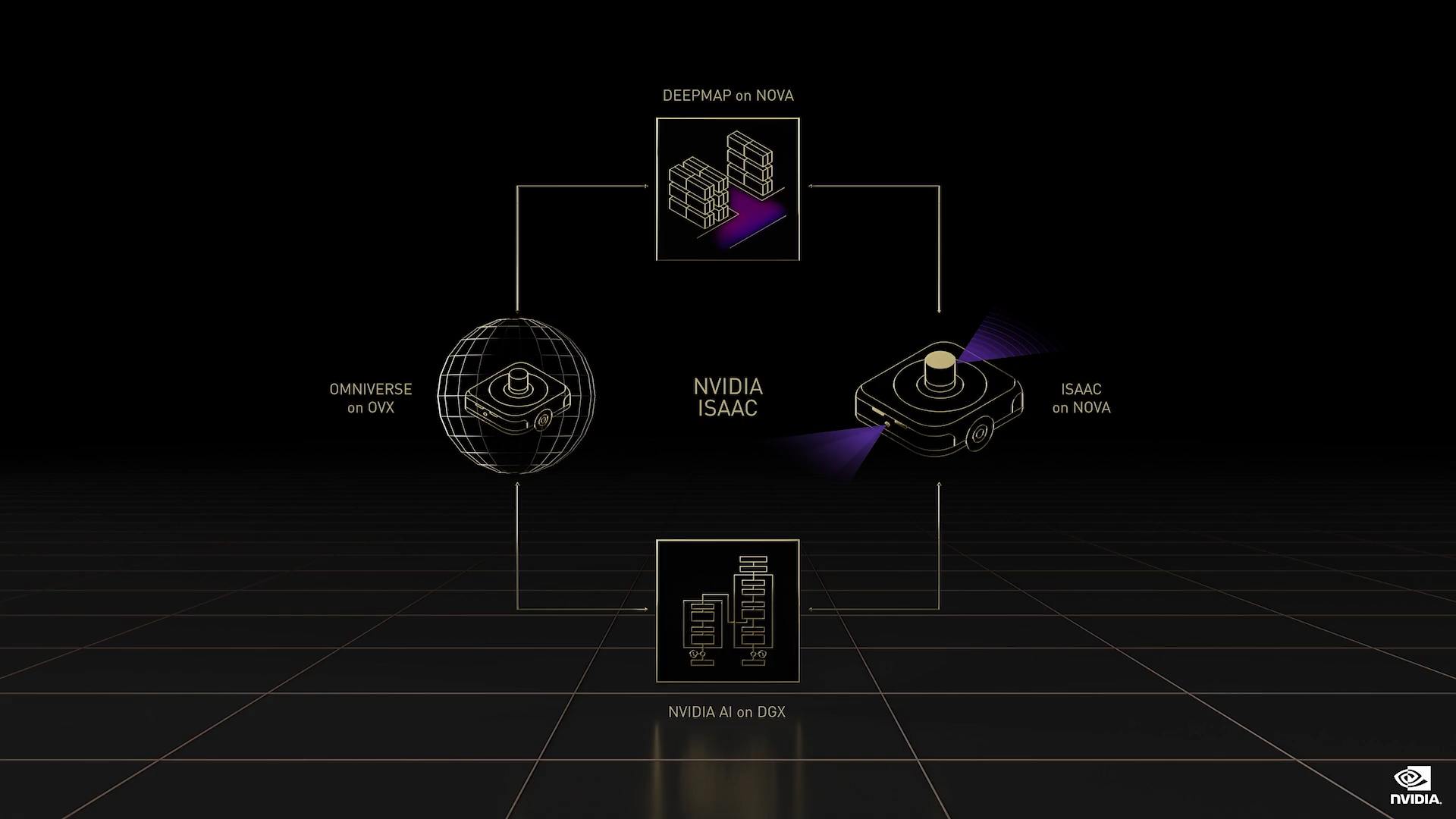
首先,与 DRIVE Hyperion 一样,Isaac Nova 是一个 AMR 机器人系统参考设计,整个 Isaac 堆栈都基于此构建。
Nova 拥有2 个摄像头、2 个激光雷达、8 个超声波雷达和 4 个鱼眼摄像头用于远程操作。
今天,我们宣布推出 Jetson Orin 开发者套件。Nova AMR 将于第二季度上市。Nova AMR 配备 NVIDIA 新的 DeepMap LIDAR 制图系统,您可以扫描和重建环境,以进行路线规划和数字孪生仿真。
Isaac 机器人 SDK 包括感知、定位、建图、规划和导航模块。今天,我们宣布用于构建 AMR 的重要更新。
Isaac 包括目标和人员检测

3D 位姿估计

LIDAR 和视觉 SLAM 定位和建图

3D 环境重建
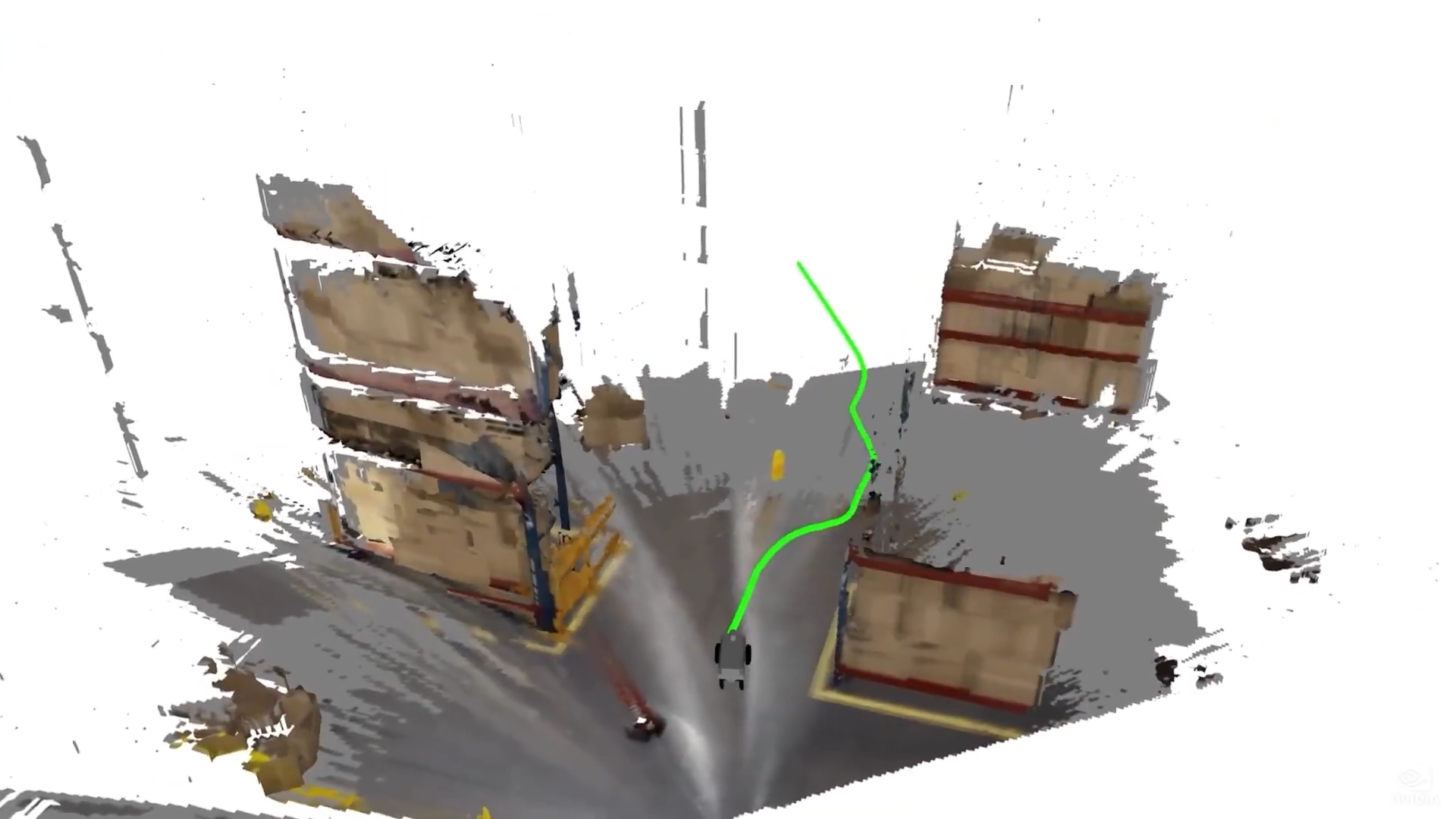
自由空间感知

使用强化学习的小车对接

导航堆栈、与 NVIDIA cuOpt 集成以进行实时规划

以及机械臂运动规划和机器人运动学等重要功能

还有一个用于远程操作的 SDK。
最后,Omniverse 可支持构建 Isaac Replicator(用于生成合成数据),Isaac Gym(用于训练机器人),以及 Isaac Sim(用于数字孪生)。Isaac 开发流程全程集成了 Omniverse
Isaac Gym 强调了 Omniverse 的物理仿真精度的重要性。
在 Isaac Gym 中,一个新机器人通过使用深度强化学习执行数千到数百万次学习来掌握一项新技能。
然后,经过训练的 AI 大脑被下载到物理机器人中。由于 Omniverse在物理上是精确的,因此机器人在获得其方位后,将掌握其在数字孪生中的技能。一起来看一下。
视频介绍
成功开发、训练和测试适用于现实世界应用的复杂机器人需要高保真仿真和准确的物理效果。 Isaac Sim 基于 NVIDIA 的 Omniverse 平台构建,将沉浸式虚拟现实的、物理属性准确的、逼真的环境与复杂的虚拟机器人相结合。 我们来看看合作伙伴使用 Isaac Sim 开发的三种截然不同的 AI 机器人。 Fraunhofer IML 是物流领域的技术领导者,使用 NVIDIA Isaac Sim 来虚拟开发 Obelix。这是一种高度动态的室内/室外自主移动机器人 (AMR)。从 CAD 导入逾 5400 个零件并借助 Omniverse PhysX 进行装配后,虚拟机器人在仿真环境中的移动与在现实世界中一样灵巧。这不仅可加快虚拟开发速度,还能够扩展至更大的场景。 接下来要介绍的是以工业自动化闻名的 Festo。该公司使用 Isaac Sim为协作机器人(简称 cobot)开发智能技能,需要对其人类伙伴和任务有敏锐的认识。使用 Cortex(一款 Isaac Sim 工具),Festo 可显著简化 cobot 技能的编程,为实现感知,此任务中使用的 AI 模型仅使用由 Isaac Replicator 生成的合成数据进行训练。 最后,要为您介绍机器狗 Anymal,由苏黎世联邦理工学院(ETH Zurich)和 Swiss-Mile 的一个领先的机器人研究小组开发。借助 GPU 加速的端到端强化学习,Anymal 的脚被轮子取代,然后使用 NVIDIA 的 Isaac Gym 训练工具,只需几分钟就可学会在城市地形上“行走”,而无需花费几周时间。运动策略在 Isaac Sim 中进行验证后,才会部署在真实的 Anymal 上。 这是一个针对真实部署进行的引人入胜的模拟器训练演示,从训练感知和策略到硬件在环,Isaac Sim 工具可构建 AI 机器人。这些机器人在仿真中诞生,在现实世界中工作(娱乐)。
现代仓储运营中心正在演变为技术奇迹,设备由人类和机器人协同操作。仓库也是一个机器人,负责协调内部物料的运输和 AMR 的路径优化。我们来看看 Amazon 如何使用 Omniverse 数字孪生技术来设计和优化令人惊叹的仓储运营中心。
视频介绍
每一天,亚马逊的数百个运营中心需处理数千万个包裹,而其中超过三分之二的客户订单由机器人处理。为了支持这种高度复杂的操作,我们部署了数十万个自主移动机器人和相关的存储舱,这使我们能够在仓库中存储远高于传统货架的库存,这帮助我们以更安全、更高效的方式移动库存。扩展的关键在于我们模拟这些建筑的能力以及在构建之前了解它们的性能。我们来看看 NVIDIA Omniverse 如何助力优化和简化这些复杂的流程。 在 Amazon Robotics,我们可以在 NVIDIA Omniverse 中创建相同比例的仓库“数字孪生”,帮助我们优化仓库设计、训练更智能的机器人助手,并提升运营效率。在 Omniverse 中,我们能够以特有的方式整合来自不同 CAD 应用的数据集,并在 Omniverse 的 RTX 加速光线追踪、材质和物理效果的推动下高度真实地呈现这些大型模型。数字孪生是未来仓库和工厂不可或缺的组成部分,可实现持续集成和交付。对于软件和仓库布局的每一次新优化,我们都可以先在数字孪生中进行测试,然后再发布至物理仓库。这样既可防止系统停机或故障,也可最大限度地提高运营效率。然后,各种形状、尺寸、重量和材质的包裹都可以在我们的仓储中心迅速移动。我们使用 NVIDIA Omniverse 更好地训练自主机器人分类和拣选解决方案。训练这些机器人的感知系统以使其具有足够的准确性以避免系统故障,需要大量高质量的数据,但通常可能没有数据或者数据量不够。当我们的包装材料中包含很多反光胶带时,感知系统会失误,我们使用在 Omniverse 中生成的物理属性准确、逼真的合成数据以重新训练模型。这些数据与真实数据别无二致,从而可以节省数周的重新训练时间,并提高模型准确性。最后,借助我们运营中心的数字孪生,以及快速、准确训练机器人感知系统的能力,我们还可以更好地配置人机工作站,更好地模拟人体工程学。 亚马逊正借助 NVIDIA Omniverse 数字孪生端到端地重塑仓库物流,并大幅提升运营效率,从而为客户提供更多价值。
Omniverse Cloud
与 NASA 和 Amazon 一样,我们在机器人和工业自动化领域的客户也意识到了数字孪生的重要性,并且正通过 Omniverse 完成令人惊叹的任务。您可以看到 Omniverse 在 NVIDIA 整个 AI 和机器人领域工作中的重要性。下一波 AI 浪潮(机器人系统)需要 Omniverse 这样的平台,我们希望 Omniverse 能够为数千万设计师、创作者、机器人专家和 AI 研究人员提供帮助。今天,我们将宣布推出 Omniverse Cloud,只需点击几下,您和您的协作者就可以完成连接。
在这个演示中,您将看到 4 位设计师,他们都在远程工作,通过 Omniverse Cloud 连接,并协作创建一个虚拟世界。我们来看看这有多么简单。
Omniverse Cloud演示 (25:51 ~ 27:45)
3D 设计是一项复杂的团队工作,涉及不同的艺术家、应用和硬件,且工作地点通常各不相同 借助 Omniverse Cloud,这将变得更加简单 使用 NVIDIA RTX PC、笔记本电脑和工作站,设计师可实时协同工作 如果您没有 RTX 计算机,只需点击一下即可从 GeForce Now 上启动 Omniverse 让我们看看一个建筑设计团队在网络会议中使用 Omniverse View 来评审项目 好的,这里是 5 楼的露台 为了更好地感受光照,我们来看看中午时候这个地方的样子 好的! 嗯,有一点阳光了。我们来对棚架进行一些调整 稍等 现在如何? 好多了,我们来看看能否连线 Teresa 好的,正在发送链接 嗨,两位好! 你好!我们做了中午的光线模拟,决定增加一些阴影。你有什么想法? 看起来很棒,但我觉得还额外需要一点什么 如果添加一些树,会怎么样? 好,请 TJ 帮我们完成吧 大家好,需要我做点什么? 嗨,TJ,你能在桌子附近的花盆里加些中等大小的树吗? 没问题,我来添加一下 这样看起来如何? 很赞!但我们可以让树木呈现更多差异吗?比如大小和种类? 好,就是这样 嗨,TJ,我们到吧台来看看晚上的效果 就是这样 哇,看起来很棒哦! 我将发送链接以供审批 相聚 Omniverse,不见不散!
您可能已经注意到,其中一个设计师是 AI。 随着 AI 技能的不断发展,我们不仅能利用它们来帮助我们设计建筑和工厂,同时还可用于餐厅订单服务,帮助客户,甚至回答有关我们健康的问题。
Omniverse,为下一波的 AI 浪潮而生。
Review
我们已经介绍了很多内容,让我快速回顾一下:
我们宣布推出 NVIDIA 四层技术栈中的新产品:
- 硬件
- 系统软件和库
- 软件平台(NVIDIA HPC、NVIDIA AI 和 NVIDIA Omniverse),
- AI 和机器人应用框架
这些产品正引领着五个态势去塑造我们的行业
- Million-X 百万倍的计算加速
- Transformer 增强 AI
- 让数据中心成为 AI 工厂
- 对机器人系统的需求呈指数增长
- 下一个 AI 时代的数字孪生

四层技术栈,五大态势
NVIDIA 加速计算、数据中心级全栈工程优化,使计算速度提高了百万倍。Million-X 百万倍加速为应对药物研发和气候科学等重大挑战提供了契机。随着自主学习 Transformer 的发明,AI 的发展速度跃上新高,AI 已从根本上改变了软件的能力以及开发软件的方式。公司通过处理和提炼数据来打造 AI、构建智能,其数据中心就是 AI 工厂。
NVIDIA H100 是全球 AI 基础架构的新引擎。NVIDIA 的 NVLink Switch 系统可将最多 32 个 DGX 连接成一个高达 1 ExaFLOPS 算力的模块,作为 AI 工厂的基础单元,

Hopper H100 是有史以来最大的代际性能提升,其大规模训练性能是 A100 的 9 倍,大型语言模型推理的吞吐量是 A100 的 30 倍。Hopper 还可以加速主流服务器。
NVIDIA H100 CNX 通过最先进的网络芯片 – NVIDIA ConnectX-7将网络直接连接到 H100。NVIDIA H100 是全球 AI 基础架构的引擎。
H100 已经投产,将从第三季度开始供货。
Grace 有望在明年投入生产。
Grace 是一款令人惊艳的超级芯片:2 个 CPU 通过 900 GB/s 的 NVLink 芯片到芯片的互连从而构成一个内存带宽为 1 TB/s 的 144 核 CPU 。Grace,全球 AI 基础架构的理想 CPU。NVLink 现在应用于裸片之间、芯片之间和系统之间的互联,并为我们提供了多种 Grace-Hopper 系统配置:从 2 个 Grace、1 个 Grace 加 1 个 Hopper、到 2 个 Grace 加 8 个 Hopper。

未来的所有 NVIDIA 芯片都将支持 NVLink,包括 CPU、GPU、DPU 和 SOC,我们还将为客户和合作伙伴提供 NVLink,以构建配套芯片。NVLink 为客户打开了新世界的大门,让他们可以利用 NVIDIA 平台和生态系统构建半定制芯片和系统。全球超过 25000 家公司使用的 NVIDIA AI 平台将进行重大更新。
NVIDIA Omniverse 平台适合虚拟世界、数字孪生和机器人系统,将掀起下一波 AI 浪潮。正如 TensorFlow 和 PyTorch 是面向感知的 AI 的基本框架一样,Omniverse 也将成为面向动作的 AI 的不可或缺的一部分。DGX 是 AI 工厂的基础架构,OVX 将成为数字孪生的基础架构。OVX 运行 Omniverse 数字孪生,用于大规模仿真,多个自主系统在同一个时空运行,OVX 的基础是网络结构。
我们宣布推出了 NVIDIA Spectrum-4 51.2 Tb/s 的交换机,凭借 ConnectX-7 和 BlueField-3 ,它将成为首款 400 Gbps 的端到端网络平台。
Spectrum-4 的样品将于第三季度问世。
能够感知、规划并采取行动的机器人系统将引领下一波 AI 浪潮。
NVIDIA Avatar、Drive、Metropolis、Isaac 和 Holoscan 是基于四大支柱构建的端到端全栈机器人平台。
四大支柱即真值数据生成、AI 模型训练、机器人技术栈和 Omniverse 数字孪生。
开发者可以部分采用这些平台,也可以整体采用。
Omniverse 是我们机器人平台的中心。与 NASA 和 Amazon 一样,我们在机器人和工业自动化领域的客户也意识到了数字孪生和 Omniverse 的重要性。
Drive Orin 已全面投产。
Issac Orin 开发者套件现已上市。
Clara Holoscan 开发者套件将于 5 月上市。我们在本届 GTC 上更新了 60 个 SDK。对于我们的 300 万开发者、科学家和 AI 研究人员以及数万家初创公司和成熟企业而言,这表示着其一直以来运行的 NVIDIA 系统的速度会越来越快。
NVIDIA SDK 服务于医疗健康、能源、交通、零售、金融、媒体和娱乐等总价值达 100 万亿美元的行业。通过在全栈和数据中心级实现加速,我们将力争在未来十年内再实现百万倍的提速。我迫不及待地想知道下一个 Million-X 百万倍会带来怎样的变化。

我要感谢 NVIDIA 开发者、合作伙伴、客户和 NVIDIA 的家人们,感谢你们为塑造世界所做的出色工作。不过,请暂时不要离开。Omniverse 生成了您今天看到的每一个渲染和仿真。
NVIDIA 卓越的创意团队希望带您再一次体验 Omniverse。